数据提取工具有很多,这里只介绍BeautifulSoup的简单使用和小案例
因为有写的很好的介绍博客,所以我直接粘链接
BeautifulSoup介绍链接:https://cuiqingcai.com/1319.html
案例依旧选用没有反爬的 豆瓣电影Top250
第一步:获取源码
简单的三句话
# 导入requests模块 import requests # 导入BeautifulSoup模块 from bs4 import BeautifulSoup # 获取要爬取的网页的url url = 'https://movie.douban.com/top250' # 用get()方法请求下载网页 rsp = requests.get(url) # text属性返回网页源码的内容 text = rsp.text
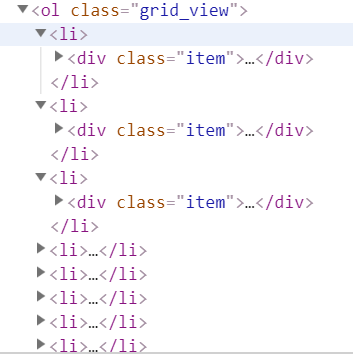
第二步:找到数据的位置
通过用浏览器的开发者工具查看源码
发现每一个电影都包含在<li>的<div class='item'> 中
用beautifulsoup的 findall() 方法找到它的位置
# 用BeautifulSoup()方法将源码内容生成能用BeautifulSoup解析的lxml格式文件 BS = BeautifulSoup(text, 'lxml') # 用find_all()方法找到包含电影的所有标签 movies = BS.find_all(name='div', attrs={'class': 'item'})
第三步:获取所需要的数据
利用beautifulsoup的各种获取方法提取出对应数据
小注意:
电影信息标签里有内嵌标签<br>,用string属性无法获取,所以用 get_text() 方法来获取文本
# 遍历每一个电影信息 for movie in movies: # 提取图片的地址信息 img = movie.find(name='img', attrs={'width': '100'}).attrs['src'] # 提取电影名字信息 name = movie.find(name='span', attrs={'class': 'title'}).string # 提取电影介绍信息 # 注意:get_text()能提取包含有内嵌标签的信息 intro = movie.find(name='p', attrs={'class': ''}).get_text() # 提取评价信息 # 注意:评价信息分别在在多个<span>里面,所以用findall()方法 star = movie.find(name='div', attrs={'class': 'star'}).find_all(name='span') # 获取评分 score = star[1].string # 获取评价人数 fans_num = star[3].string # 获取引语 quote = movie.find(name='span', attrs={'class': 'inq'}).string

第四步:简单保存
用open()、write() 方法将提取的数据存在txt文本文件里
# 用open()方法创建一个名为‘Top250’的‘txt’文件 with open('Top250.txt', 'a', encoding='utf-8') as f: # 用write()方法写入内容 f.write('img:'+img+' name:'+name+' intro:'+intro+' score:'+score+' fans_num:'+fans_num+' quote:'+quote + '\n')结果展示:

全部代码
# 导入requests模块
import requests
# 导入BeautifulSoup模块
from bs4 import BeautifulSoup
# 获取要爬取的网页的url
url = 'https://movie.douban.com/top250'
# 用get()方法请求下载网页
rsp = requests.get(url)
# text属性返回网页源码的内容
text = rsp.text
# 用BeautifulSoup()方法将源码内容生成能用BeautifulSoup解析的lxml格式文件
BS = BeautifulSoup(text, 'lxml')
# 用find_all()方法找到包含电影的所有标签
movies = BS.find_all(name='div', attrs={'class': 'item'})
# 遍历每一个电影信息
for movie in movies:
# 提取图片的地址信息
img = movie.find(name='img', attrs={'width': '100'}).attrs['src']
# 提取电影名字信息
name = movie.find(name='span', attrs={'class': 'title'}).string
# 提取电影介绍信息
# 注意:get_text()能提取包含有内嵌标签的信息
intro = movie.find(name='p', attrs={'class': ''}).get_text()
# 提取评价信息
# 注意:评价信息分别在在多个<span>里面,所以用findall()方法
star = movie.find(name='div', attrs={'class': 'star'}).find_all(name='span')
# 获取评分
score = star[1].string
# 获取评价人数
fans_num = star[3].string
# 获取引语
quote = movie.find(name='span', attrs={'class': 'inq'}).string
# 用open()方法创建一个名为‘Top250’的‘txt’文件
with open('Top250.txt', 'a', encoding='utf-8') as f:
# 用write()方法写入内容
f.write('img:'+img+' name:'+name+' intro:'+intro+' score:'+score+' fans_num:'+fans_num+' quote:'+quote + '\n')