1. delorean,用来处理时间的库
import datetime
import pytz
# 一般情况下,我们想表示时间的话
est = pytz.timezone("Asia/Shanghai")
t = datetime.datetime.now(est)
print(t) # 2018-07-30 23:06:21.563803+08:00
# 使用delorean
from delorean import Delorean
d = Delorean()
t = d.shift("Asia/Shanghai")
print(t) # Delorean(datetime=datetime.datetime(2018, 7, 30, 23, 6, 21, 607802), timezone='Asia/Shanghai')
print(t.next_day(1)) # Delorean(datetime=datetime.datetime(2018, 7, 31, 23, 7, 40, 48419), timezone='Asia/Shanghai')
print(t.next_day(-1)) # Delorean(datetime=datetime.datetime(2018, 7, 29, 23, 8, 1, 593950), timezone='Asia/Shanghai')
# 下一个星期天
print(t.next_sunday()) # Delorean(datetime=datetime.datetime(2018, 8, 5, 23, 8, 56, 391465), timezone='Asia/Shanghai')
# 下一个星期五
print(t.next_friday()) # Delorean(datetime=datetime.datetime(2018, 8, 3, 23, 8, 56, 391465), timezone='Asia/Shanghai')
from delorean import stops
import delorean
for stop in stops(freq=delorean.HOURLY, count=10):
print(stop)
'''
Delorean(datetime=datetime.datetime(2018, 7, 30, 15, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 30, 16, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 30, 17, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 30, 18, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 30, 19, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 30, 20, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 30, 21, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 30, 22, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 30, 23, 11, 17), timezone='UTC')
Delorean(datetime=datetime.datetime(2018, 7, 31, 0, 11, 17), timezone='UTC')
'''
2.prettybody
from prettytable import PrettyTable
p = PrettyTable()
p.field_names = ["name", "age", "gender", "husband"]
p.add_row(["satori", 18, "f", "zgg"])
p.add_row(["mashiro", 18, "f", "zgg"])
p.add_row(["miku", 18, "f", "zgg"])
p.add_row(["matsuri", 18, "f", "zgg"])
print(p)
'''
+---------+-----+--------+---------+
| name | age | gender | husband |
+---------+-----+--------+---------+
| satori | 18 | f | zgg |
| mashiro | 18 | f | zgg |
| miku | 18 | f | zgg |
| matsuri | 18 | f | zgg |
+---------+-----+--------+---------+
'''
# 添加一列
p.add_column("anime", ["东方地灵殿", "樱花庄的宠物女孩", "初音未来", "sola"])
print(p)
'''
+---------+-----+--------+---------+------------------+
| name | age | gender | husband | anime |
+---------+-----+--------+---------+------------------+
| satori | 18 | f | zgg | 东方地灵殿 |
| mashiro | 18 | f | zgg | 樱花庄的宠物女孩 |
| miku | 18 | f | zgg | 初音未来 |
| matsuri | 18 | f | zgg | sola |
+---------+-----+--------+---------+------------------+
'''
# 获取表格
print(p.get_html_string())
'''
<table>
<tr>
<th>name</th>
<th>age</th>
<th>gender</th>
<th>husband</th>
<th>anime</th>
</tr>
<tr>
<td>satori</td>
<td>18</td>
<td>f</td>
<td>zgg</td>
<td>东方地灵殿</td>
</tr>
<tr>
<td>mashiro</td>
<td>18</td>
<td>f</td>
<td>zgg</td>
<td>樱花庄的宠物女孩</td>
</tr>
<tr>
<td>miku</td>
<td>18</td>
<td>f</td>
<td>zgg</td>
<td>初音未来</td>
</tr>
<tr>
<td>matsuri</td>
<td>18</td>
<td>f</td>
<td>zgg</td>
<td>sola</td>
</tr>
</table>
'''
print(p.get_string())
'''
+---------+-----+--------+---------+------------------+
| name | age | gender | husband | anime |
+---------+-----+--------+---------+------------------+
| satori | 18 | f | zgg | 东方地灵殿 |
| mashiro | 18 | f | zgg | 樱花庄的宠物女孩 |
| miku | 18 | f | zgg | 初音未来 |
| matsuri | 18 | f | zgg | sola |
+---------+-----+--------+---------+------------------+
'''
# 获取指定的列,指定的行
print(p.get_string(fields=["name", "anime"], start=0, end=4))
'''
+---------+------------------+
| name | anime |
+---------+------------------+
| satori | 东方地灵殿 |
| mashiro | 樱花庄的宠物女孩 |
| miku | 初音未来 |
| matsuri | sola |
+---------+------------------+
'''
3.snowballstemmer
# 用来提取单词词干,支持15种语言
from snowballstemmer import EnglishStemmer
print(EnglishStemmer().stemWord("love"))
print(EnglishStemmer().stemWord("production"))
print(EnglishStemmer().stemWord("affection"))
print(EnglishStemmer().stemWord("gravity"))
'''
love
product
affect
graviti
'''
4.wget,比较有用的库,可以用来下载图片
import wget url = "https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1532975831713&di=6add9fa41ac1a7ddbddcaa919d49c497&imgtype=0&src=http%3A%2F%2Fimage.uczzd.cn%2F6715434799472055716.jpeg%3Fid%3D0" # 参数一:url,下载的地址,参数二:out,输出的文件名或路径 wget.download(url=url, out=r"C:\Users\Administrator\Desktop\aaa\matsuri.jpg")
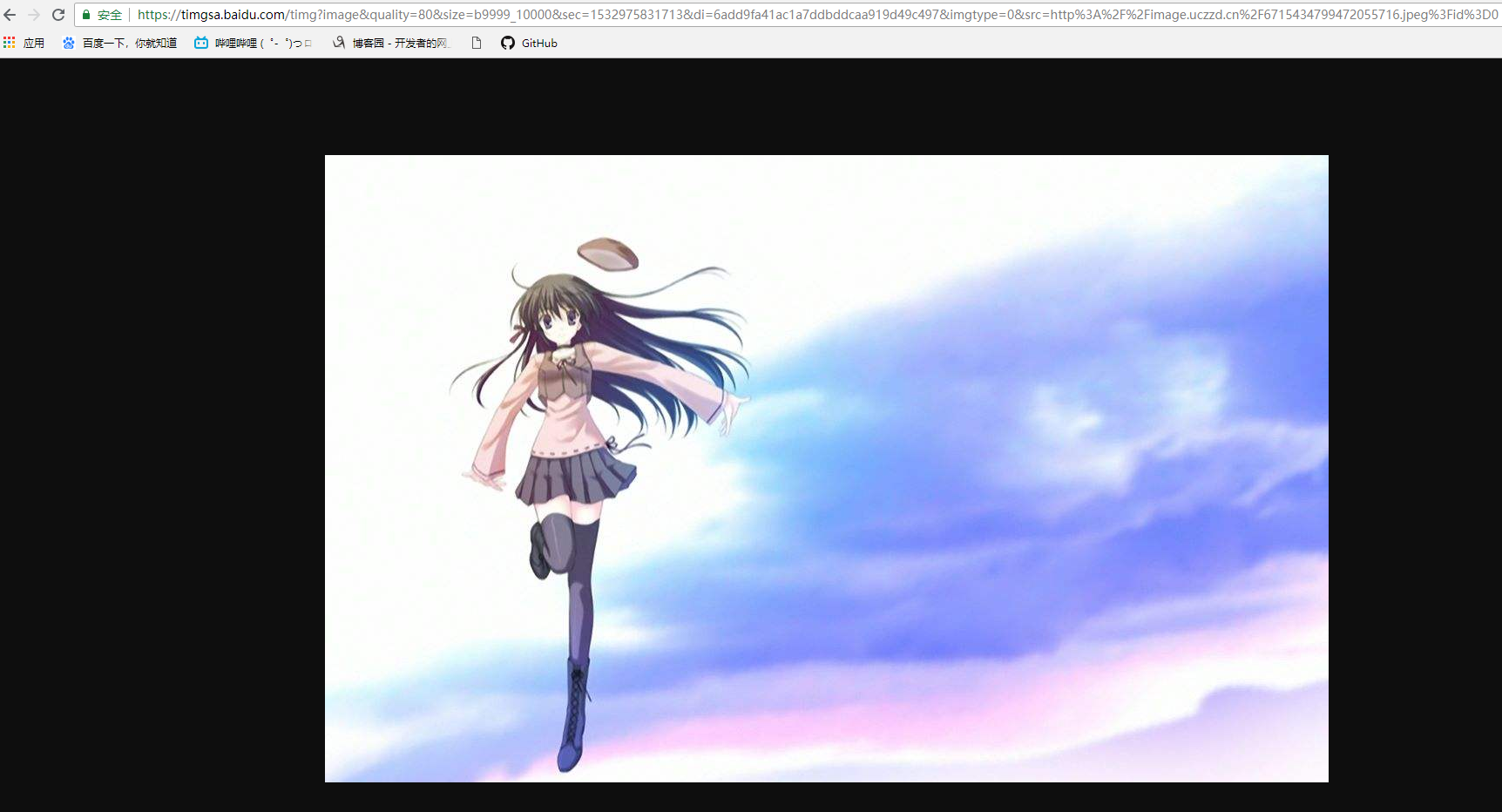
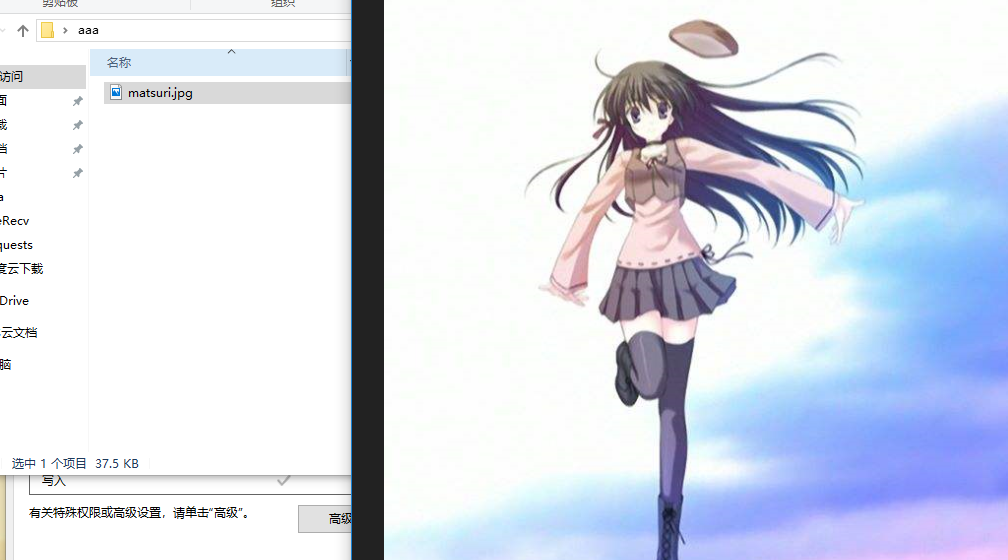
当然输入一个普通的url,会将整个页面的html文本下载下来
5.fuzzywuzzy,用来做字符串的相似度
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
print(fuzz.ratio("my name is satori", "my name is mashiro")) # 74,表示相似度是百分之74
print(fuzz.ratio("i love satori", "I love satori")) # 92,可见是区分大小写的
print(fuzz.ratio("i love satori", "I love satori!")) # 89
print(fuzz.partial_ratio("i love satori", "i love satori!!!!!")) # 100
# 两者对位置都敏感,但是ratio是属于全匹配。partial_ratio是搜索匹配,知道一方结束,后面的即使有也不会造成影响
print(fuzz.ratio("我永远喜欢古明地盆", "我永远喜欢古明地盆,多睡觉少操心")) # 72
print(fuzz.partial_ratio("我永远喜欢古明地盆", "我永远喜欢古明地盆,多睡觉少操心")) # 100