在上一篇文章中,我们学习了线程池的构造方法以及基本的使用方法。还没有看过上一篇文章的朋友,建议先去阅读 Android 线程池的使用,本文将继续深入了解线程池的高级用法。
BlockingQueue 的接口队列
在多数情况下,我们构建线程池主要是通过 Executors 的工厂方法来创建线程池,但 Executors 的工厂方法创建的线程池也是直接或间接通过配置 ThreadPoolExecutor 参数来实现的。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {...
}在上面的参数中理解起来都比较简单,但 workQueue 要多说明一下。workQueue 是一个 BlockingQueue 对象,它是一个特殊的队列,当我们从 BlockingQueue 中取数据时,如果 BlockingQueue 是空的,则取数据的操作会进入到阻塞状态,当 BlockingQueue 中有了新数据时,这个取数据的操作又会被重新唤醒。同理,如果 BlockingQueue 中的数据已经满了,往 BlockingQueue 中存数据的操作又会进入阻塞状态,直到 BlockingQueue 中又有新的空间,存数据的操作又会被重新唤醒。它的泛型限定它是用来存放 Runnable 对象的。不同的线程池它的任务队列实现是不一样的,所以保证不同线程池不同功能的核心就是这个 workQueue 的实现了,通过 Executors 的工厂方法创建的线程池传入的 workQueue 也是不一样的。接下来就来说明 BlockingQueue 的多种不同的实现类。
- ArrayBlockingQueue:这个表示一个规定了大小的 BlockingQueue,ArrayBlockingQueue 的构造函数接受一个 int 类型的数据,该数据表示BlockingQueue 的大小,存储在 ArrayBlockingQueue 中的元素按照 FIFO(先进先出)的方式来进行存取。
- LinkedBlockingQueue:这个表示一个大小不确定的 BlockingQueue,在LinkedBlockingQueue 的构造方法中可以传一个 int 类型的数据,这样创建出来的 LinkedBlockingQueue 是有大小的,也可以不传,不传的话,LinkedBlockingQueue 的大小就为 Integer.MAX_VALUE
- PriorityBlockingQueue:这个队列和 LinkedBlockingQueue 类似,不同的是PriorityBlockingQueue 中的元素不是按照 FIFO 来排序的,而是按照元素的Comparator 来决定存取顺序的(这个功能也反映了存入 PriorityBlockingQueue 中的数据必须实现了 Comparator 接口)。
- SynchronousQueue:这个是同步 Queue,属于线程安全的 BlockingQueue的一种,在 SynchronousQueue 中,生产者线程的插入操作必须要等待消费者线程的移除操作,Synchronous 内部没有数据缓存空间,因此我们无法对 SynchronousQueue进行读取或者遍历其中的数据,元素只有在你试图取走的时候才有可能存在。我们可以理解为生产者和消费者互相等待,等到对方之后然后再一起离开。
了解了 BlockingQueue 的种类,再来看看各种不同线程池分别传入的 workQueue 的类型:
1、newFixedThreadPool()—>LinkedBlockingQueue
2、newSingleThreadExecutor()—>LinkedBlockingQueue
3、newCachedThreadPool()—>SynchronousQueue
4、newScheduledThreadPool()—>DelayedWorkQueue
自定义线程池 ThreadPoolExecutor
一般来说,Java 内置的线程池已经够我们使用了,不过有时候我们也可以根据需求来自定义线程池,而要自定义不同功能的线程池,归根结底还是要根据 BlockingQueue 的实现,所以我们要自定义线程池,就必须从 BlockingQueue 着手,而上面说了 BlockingQueue 的实现类有多个,那么我们这次就选用 PriorityBlockingQueue 来实现一个按任务的优先级来处理的线程池。
1. 首先我们创建一个基于 PriorityBlockingQueue 实现的线程池.
ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 3, 0, TimeUnit.SECONDS, new PriorityBlockingQueue<Runnable>());- 创建一个实现 Runnable 接口的类,并向外提供一个抽象方法供我们实现自定义功能,并实现 Comparable 接口,实现这个接口主要就是进行优先级的比较.
public abstract class PriorityRunnable implements Comparable<PriorityRunnable> ,Runnable{
private int priority;
public PriorityRunnable(int priority) {
if (priority < 0)
throw new IllegalArgumentException();
this.priority = priority;
}
@Override
public int compareTo(PriorityRunnable another) {
int my = this.getPriority();
int other = another.getPriority();
return my < other ? 1 : my > other ? -1 : 0;
}
@Override
public void run() {
doSth();
}
public abstract void doSth();
public int getPriority() {
return priority;
}
}- 使用我们自己的 PriorityRunnable 提交任务,整体代码如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 3, 0, TimeUnit.SECONDS, new PriorityBlockingQueue<Runnable>());
for (int i = 0; i < 30; i++) {
final int priority = i;
PriorityRunnable runnable = new PriorityRunnable(priority) {
@Override
public void doSth() {
String threadName = Thread.currentThread().getName();
Log.v(TAG, "线程:" + threadName + ",正在执行优先级为:" + priority + "的任务");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
executor.execute(runnable);
}
}测试效果
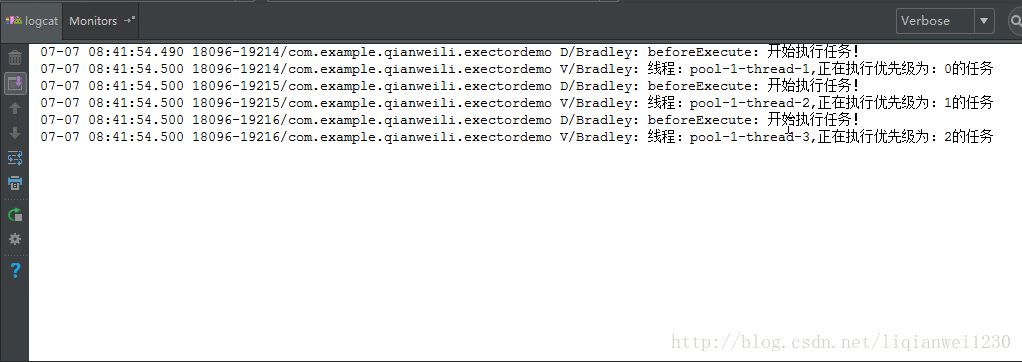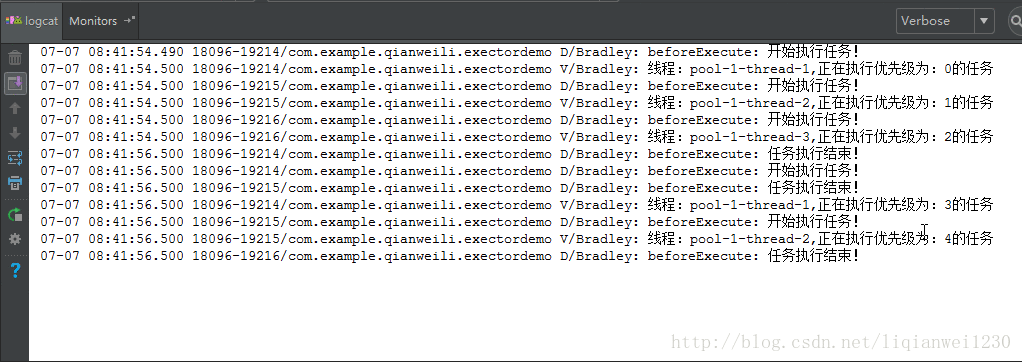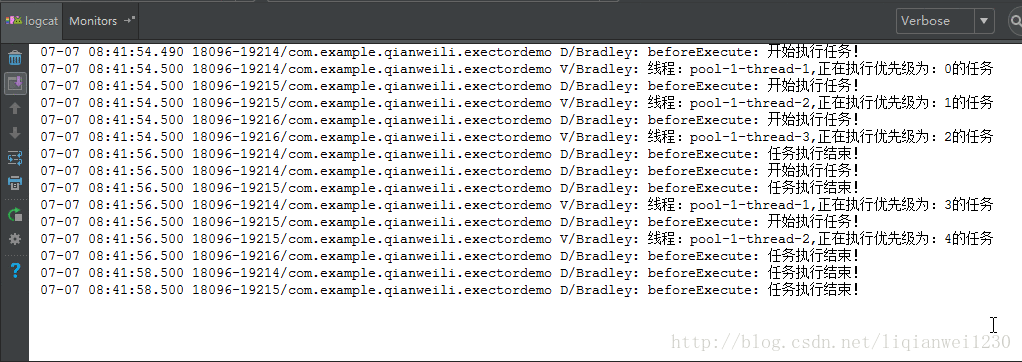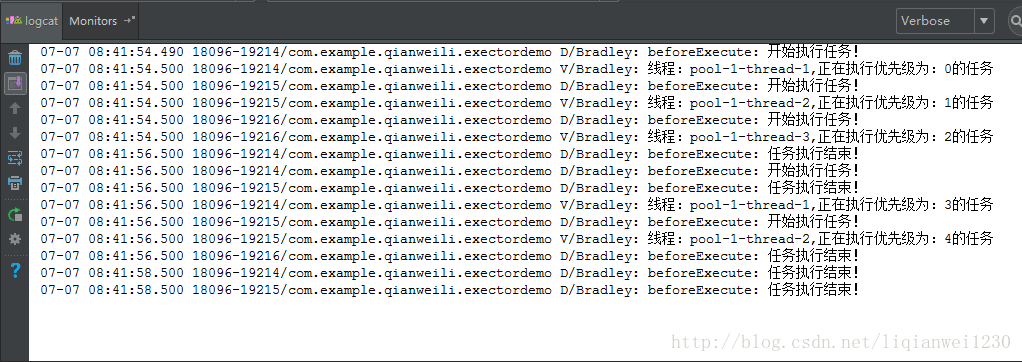
我们看下刚刚自定义的线程池是否达到了我们想要的功能,即根据任务的优先级进行优先处理任务,效果如下:
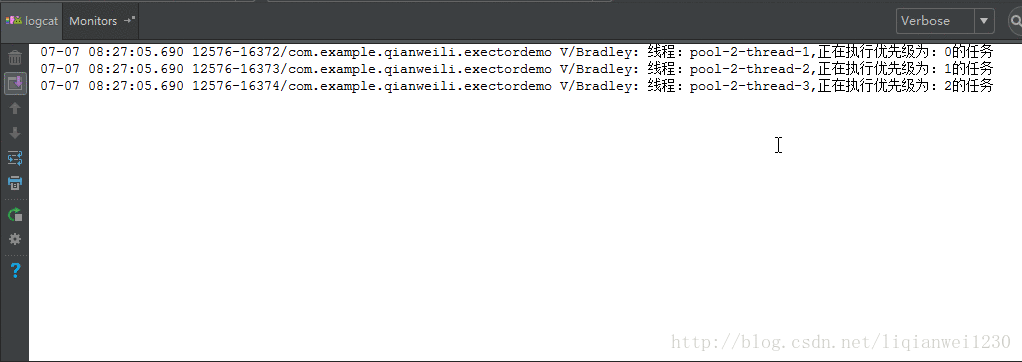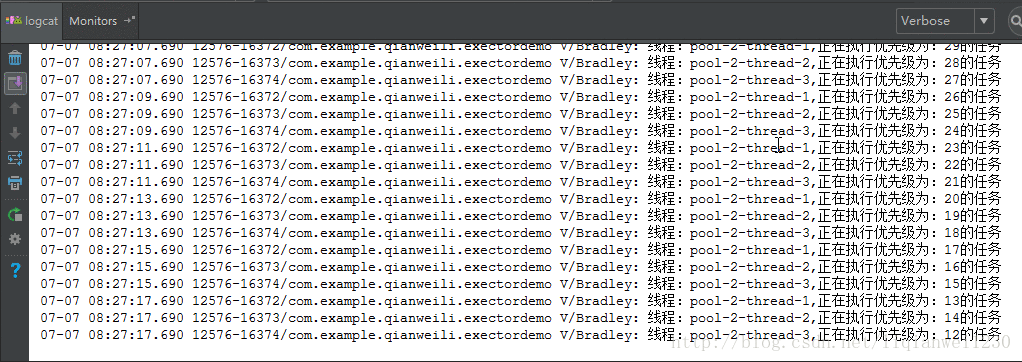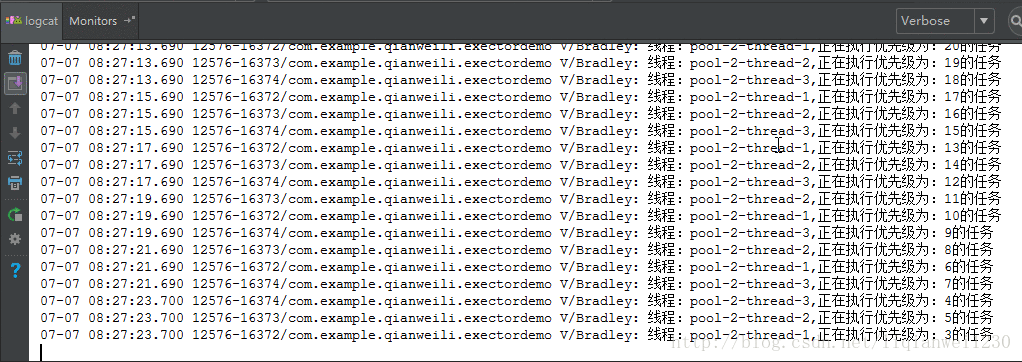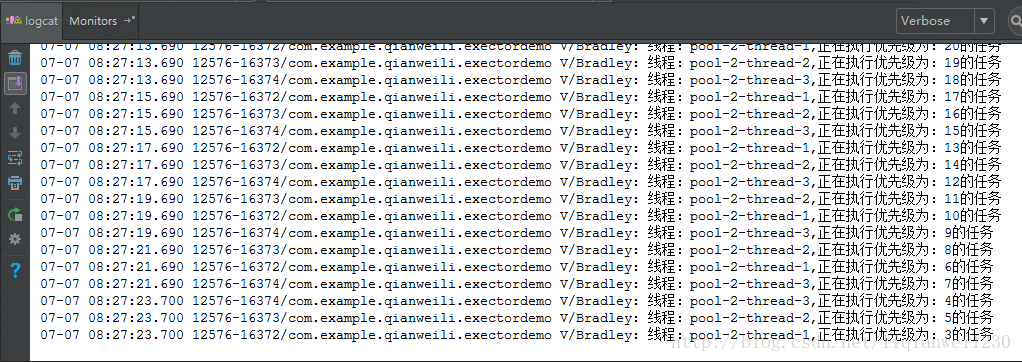
可以从执行结果中看出,由于核心线程数设置为 3,刚开始时,系统有 3 个空闲线程,所以无须使用任务队列,而是直接运行前三个任务,而后面再提交任务时由于当前没有空闲线程所以加入任务队列中进行等待,此时,由于我们的任务队列实现是由 PriorityBlockingQueue 实现的,所以进行等待的任务会经过优先级判断,优先级高的放在队列前面先处理。从效果图中也可以看到后面的任务是先执行优先级高的任务,然后依次递减。
优先级线程池的优点
从上面我们可以得知,创建一个优先级线程池非常有用,它可以在线程池中线程数量不足或系统资源紧张时,优先处理我们想要先处理的任务,而优先级低的则放到后面再处理,这极大改善了系统默认线程池以 FIFO 方式处理任务的不灵活.
扩展线程池ThreadPoolExecutor
除了内置的功能外,ThreadPoolExecutor 也向外提供了三个接口供我们自己扩展满足我们需求的线程池,这三个接口分别是:
1. beforeExecute() - 任务执行前执行的方法
2. afterExecute() -任务执行结束后执行的方法
3. terminated() -线程池关闭后执行的方法
这三个方法在 ThreadPoolExecutor 内部都没有实现,我们也可以通过自定义 ThreadPoolExecutor 来实现这个功能。
public class MyThreadPool extends ThreadPoolExecutor {
private static final String TAG = "Bradley" ;
public MyThreadPool(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
super.beforeExecute(t, r);
Log.d(TAG, "beforeExecute: 开始执行任务!");
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
Log.d(TAG, "beforeExecute: 任务执行结束!");
}
@Override
protected void terminated() {
super.terminated();
Log.d(TAG, "terminated: 线程池关闭!");
}
}而运行后的结果则是,这正符合刚刚说的。
优化线程池 ThreadPoolExecutor
虽说线程池极大改善了系统的性能,不过创建线程池也是需要资源的,所以线程池内线程数量的大小也会影响系统的性能,大了反而浪费资源,小了反而影响系统的吞吐量,所以我们创建线程池需要把握一个度才能合理的发挥它的优点,通常来说我们要考虑的因素有 CPU 的数量、内存的大小、并发请求的数量等因素,按需调整。
通常核心线程数可以设为CPU数量+1,而最大线程数可以设为CPU的数量*2+1。
获取CPU数量的方法为:
Runtime.getRuntime().availableProcessors();shutdown()和shutdownNow()的区别
关于线程池的停止,ExecutorService 为我们提供了两个方法:shutdown 和 shutdownNow,这两个方法各有不同,可以根据实际需求方便的运用,如下:
1、shutdown() 方法在终止前允许执行以前提交的任务。
2、shutdownNow() 方法则是阻止正在任务队列中等待任务的启动并试图停止当前正在执行的任务。