为什么选择BGP而不是一个IGP协议(如OSPF或者IS-IS),这是Calico项目组偶尔被问到的一个问题。提问的人总认为这是一个问题,但实际上这是相关却又不同的两个问题。要弄清楚原因,并且知道Calico对着两个问题的答案,我们需要先明确目前BGP和IGP是何如在一个大规模网络中工作的。
1 在一个大型网络中,这些协议在哪里(以及为什么)会被用到?
任何网络,尤其是大型网络,都需要处理两个不同的路由问题:
- 发现网络中路由器之间的拓扑结构
- 发现网络中正在工作的
endpoints(数据终端,后面使用英文原文),以及可到达该网络的外部连接。
下面一张图可以帮助我们理解:
图1 内部网络/外部网络示意图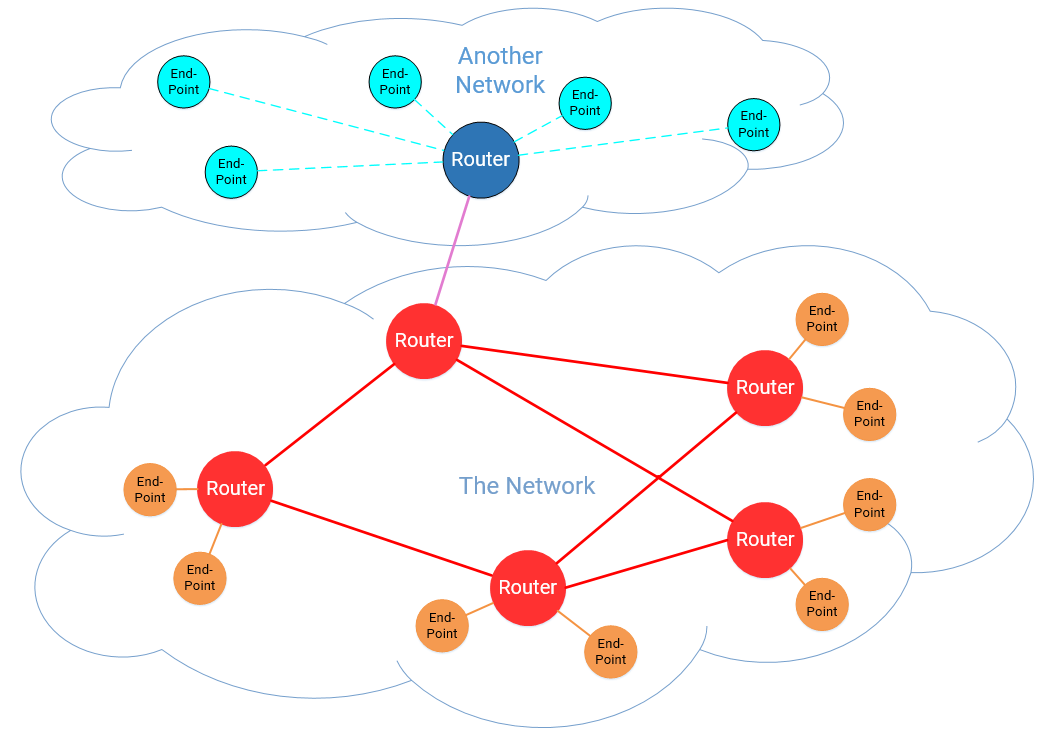
我们对上图加上一些注释。我们这个网络中,路由器、路由器之间的链路是红色的。endpoints,以及endpoints与路由器之间的链路是橙色的。网络中endpoints没有运行路由协议的能力,而路由器可以。
我们的网络还通过一个洋红色的“网络-网络”的链路连接到“外部网络”。外部网络中与我们网络互连的路由器是蓝色的。这个网络也有endpoints,它们在图中被标记为蓝绿色。因为外部网络不属于我们管理,我们看不到它里面发生了什么。我们对外部网络的所有了解就是:它宣告过来的endpoints路由,以及外部网络中那个与我们互联的蓝色路由器。
这就引出了自制系统Autonomous System(AS)的概念。我们的网络就是一个AS,外部是另外一个AS。然而对AS的深入讨论超出了本文的范围,暂且将它们视作一个管理域的边界就好。你对自己AS内部发生的事件远比对其他AS的了解的更多,这也就是上图外部网络中的连接都是用虚线的原因。我们并不知道那些endpoints是如何连接到那个蓝色的路由器(我们的对等体),我们也不需要去关心。
1.1 自治系统内部的基础架构路由(通常是IGP)
在一个非完整图(incomplete graph)结构路由器组成的网络中,路由器们需要先了解网络拓扑,才能穿越整个网络发送流量到目标地址。这时IGP,比如IS-IS或者OSPF就需要被用到了。
incomplete graph:可以理解成路由器之间不是全互联的结构,两个路由器之间的通讯很可能需要借助一个中间路由器传递。例如,如果A希望将数据包发送给Z,那么它可能不得不先将数据包发送给B,并依次传递给C、X等,最后才能到达目标Z。
IGP需要执行大量复杂计算,才能让每台设备在同一时刻都能得到对所处网络拓扑的相同认知。这其实就限制了IGP所能运行的规模。在一个IGP的单一视图内(single view)应该只包含几十个(极端情况下可能是小几百个)路由器,以满足这些规模和性能的需求。虽然,也存在一些可以突破规模限制的技术,比如在OSPF中使用area(区域)或者在IS-IS中使用Level(层),两者都可以认为是将网络切割成若干个单一视图。但是,这些技术也带来了其它架构上的限制,因为超出本文的范围这里不再展开。
IGP也被限制在它们所能通告的最大endpoints数量上,这个数量浮动范围比较大,但是上限也就在几千到1万+。当IGP中的路由数量超过5000或6000条时,许多大型网络的管理人员都会感到紧张。
在一些实施案例中,网络中的路由器是直接互联的,比如以太网互联结构的Calico网络,就不需要IGP的参与,它的结构是一个逻辑的完整图(logically complete graph)。甚至即便它不是完整图,如果结构很简单也不需要IGP。
1.2 外部终端节点路由通告
截止到2015年1月在公共互联网上宣告的路由超过526000条,一些网络已经拥有超过100万的endpoints。这绝对是你可以在一个路由扩展网络结构中可以看到的规模。
为了满足这些需求,BGP协议被开发了出来。它可以在一个网络中扩容到几百台路由器,如果使用路由器反射器(BGP route reflection)数量可以到达数万台。如果需要的话,它可以宣告数百万条路由信息,并通过非常灵活的策略加以管理。
1.3 OSPF是简单的,BGP是困难和复杂的?
实际上,这并不十分准确。如果有什么区别的话,那就是BGP并不关心完整的拓扑,在它最简单的应用环境中,BGP的配置、运行和排错比OSPF或者IS-IS都要简单。或者说:协议本身是简单的,然而,在大型传输网络和非常复杂的终端网络中,网络管理员需要使用路由策略,给流量增加了基于安全和商业目的的处理逻辑。由于该策略可能非常复杂,所以导致BGP策略的管理也变得复杂。相反,如果策略是非常简单的,或者没有使用路由策略,那么BGP通常只需要一些“告诉一个路由器它的对等体邻居是谁”的配置就可以正常运行了。
2 为什么Calico选择BGP而不是IGP?
我们需要将这个问题分成两个问题来回答
2.1 为什么Calico使用BGP宣告endpoints的路由?
Calico工程的其中一个设计概要就是:使用通用的互联网工具和技术去实现大规模网络互连结构,其主要原因是(互联网)行业在运营真正大型网络已经上积累了几十年的经验,使用的工具和技术也已经过长时间的磨练(比如BGP),如果把这些工作全部丢进垃圾桶就比较愚蠢了。随着数据终端网络(end point networks)已经接近的互联网的规模:如今,在基于VM的云环境中一个pod可以轻松承载数千到数万个计算服务器,并运行着几万甚至小几十万个VM (在Calico被称为的end points)。而在基于容器的云环境中,endpoints的数量可能还会增加一个或两个数量级。所以,我们也应该使用与互联网运营商同样的工具。
在Calico设计的网络中,可能会出现几万台路由器,以及潜在的几百万条路由信息或者endpoints,这种数量级是与IGP的设计不匹配的,但是BGP可以,特别是当我们使用路由反射器去扩展路由器数量的时候。
简而言之,BGP是Calico网络的唯一选择。
2.2 如果使用基础架构路由(IGP)会怎么样?
我们没有完全拒绝IGP,只是在很多情况下,Calico网络不需要基础设施路由协议。例如,在后面会提到的“以太网互联结构的Calico网络模型”中,每个计算服务器vRouter彼此间是直连的,也就不再需要IGP协议了。
而在使用“IP互联结构的Calico网络模型”中,如果互联结构被设计的比较复杂,则可能需要计算服务器vRouter去参与一些IGP进程。
需要注意的是,在IP互联结构,这些中间路由器/交换机也必须是BGP路由拓扑的成员。
3 总结
总结一下,我们在Calico网络中使用BGP去宣告endpoints路由是因为如下原因:
- BGP是一种简单的路由协议
- 拥有当前行业的最佳实践
- 唯一能够支撑Calico网络规模的协议
希望通过本文的论述已经回答了“为什么Calico网络需要使用BGP”这个问题。