连接远程服务器 没有-h 就是连接本机,-u 是user -p是password
mysql -h hostname -u root -p
指定使用哪个库
mysql>use xxxx;
注释
mysql>命令; -- 注释的内容
显示所有数据库
mysql>show databases;
指定使用哪个数据库
use test;
创建数据库
create database 数据库名;
创建数据库且指定字符集
create database 数据库名 character set utf8;
修改数据库的字符集
alter database 数据库名称 character set 字符集
删除数据库
drop database 数据库名字
查询当前正在使用哪个数据库,这个有点不同,必须还有一个括号,代表是一个函数
select database();
创建表
create table 表名(列名 列的数据类型 约束,列名2 列的数据类型2 约束)
显示所有表
show tables;
列的类型
char(3) 代表可以存3个字符
varchar(3) 可变长度,但也只能存3个字符
int 整数类型
float 浮点类型
double 双浮点
boolean 布尔类型
data 日期型
data: YYYY-MM--DD
time: hh:mm:ss
datatime: YYYY-MM-DD hh:mm:ss 默认值是null
timestamp:YYYY-MM-DD hh:mm:ss 默认使用当前时间
text 文本型
blob 字段型,二进制类型,存任何数据
约束
primary key 主键约束,唯一不能为空
unique 唯一约束
not null 非空约束
创建一个带有约束的学生表
create table student(sid int primary key,sname varchar(32), sex int, age int);
查看所有表
show tables;
查看表的定义
desc tables;
添加列
alter table 表名 add 列名 列的类型 列的约束
alter table student add score int not null;
修改列的类型,把上面的add改成modify即可
alter table student modify sex varchar(2);
修改列名,把modify改成change即可,但是列表后面还需要带类型
alter table student change sex 新名称 varchar(2);
删除指定列
alter table student drop 列名;
删除表
drop table 表名;
插入数据
如果不能插入中文,那么修改mysql目录下的my.ini,然后把default-character-set=utf8修改成gbk即可
这种方式,列名和值可以不写全
insert into 表名(列名1,列名2,列名3) values(值1,值2,值3);
这种方式,值必须要写全
insert into 表名 values (值1,值2,值3);
如果要插入多行,用逗号分隔即可
insert into 表名 values(值1,值2),(值3,值4),(值5,值6)
insert into student values(1,'荒天帝',1,10);
删除表中的数据
删除表中指定数据
delete from 表名 条件
delete from student where id =1;
truncate from student where id=1;
删除表中所有数据
delete from student;
truncate from student;
俩种删除表数据的区别
delete适合小数据量的删除,一条条的删除
truncate 先删除表,再重建表,要删除的就不重建,适合大数据量的删除
更新表的数据
如果不加where 条件,那么就会修改所有指定的列
update 表名 set 列名=新值 列名2=新值 条件;
update 表名 set sid=6 sname='呵呵' where age>6;
创建一个商品分类的表
id 名称 描述
create table class(cid int primary key auto_increment,cname varchar(10),cdesc varchar(31));
auto_increment意思是自动增长,主键可填null,他会每新插入新数据就自动+1
insert into class values(null,'手机','智能手机'),(null,'电脑','智能电脑'),(null,'食物','智能食物'),(null,'零食','智能辣条');
创建商品表
id 名称 价格 日期 类别id
create table product(
pid int primary key auto_increment, 真正的商品id
pname varchar(10),
price double,
pdate timestamp,
cno int 用于和class的id连接,class的id是类别id
);
create table product(pid int primary key auto_increment,pname varchar(10),price double,pdate timestamp,cno int);
insert into product values(null,'小米',1000,null,1),(null,'苹果',5000,null,1),(null,'外星人',10000,null,2),(null,'辣条',1,null,4),(null,'方便面',3,null,3);
timestamp类型的日期填null,会自动指定当前时间
查询表里的所有数据
select * from 表名;
查询表中指定列的数据
select 列名1,列名2 from 表;
select pname,price from product;
别名查询,给列或表重新起一个名字
列或表 as 新名字
因为from会优先执行,所以表名被定义为了as,所以可以用p.name,因为student表里有pname
select p.pname,p.price from product as p;
去除重复查询
distinct 不同的 ,查出来的价格没有重复的
select distinct price from product;
运算查询
*代表所有列,后面又加了price*1.5,是新的一列,比原来多一列,但只是页面显示的,原数据并没有改变
select *,price*0.5 as 打折后的价格 from product;
条件查询
把价格大于60的所有商品找出
select * from product where price>60;
where后面的条件写法
关系运算符 > >= < <= = != <>
select * from product where price<>60;
逻辑查询 and or not between
查询价格在10~100之间的所有商品
select * from product where price>10 and price<100;
select * from product where between 10 and 100; 这里的10和100不能互调
范围查询 in
查出商品分类在1,3的所有产品
select * from product where cno in(1,3);
模糊查询
查询出名称带有'苹' 字 的商品,%代表匹配所有,包括空
select * from product where pname like '%苹%';
查询名字第2个字是熊的所有商品, _就代表一个字符
select * from product where pname like '_米';
查询出名字带有下划线的所有商品, \是转移符
select * from product where pname like '%\_%';
排序
desc是降序,asc升序,默认是升序
select * from product order by price desc;
查询名称有'米'的商品,按价格降序排序
select pname,price from product where pname like '%米%' order by price desc;
聚合函数
注意,where 条件后面不能加聚合函数
sum() 求和 avg() 求平均值 count() 计算数量 max() 最大值 min() 最小值
获取所有商品价格的总和
select sum(price) from product;
获取所有商品的评价价格
select avg(price) from product;
获取所有商品的个数
select cout(*) from product;
查出商品价格大于平均价格的所有商品,用到了子查询,因为where 后面不能有聚合函数,所有必须用子查询
select * from product where price>(select avg(price) from product);
分组查询
统计每个类别有多少个商品 原理是根据cno字段分组,分组后统计商品的个数,
下面的意思是,根据cno分组,分组了n组,显示cno数值我们会发现,cno分组是不包含重复的cno的
就是说,cno有 1 ,2 1, 3, 4 在product表里,那么分组就按 1 ,2,3,4 分成4组,那么其实重复的cno没有显示出来
而count(*)便是计算每分成一组,这一组里面有几个数据,而这个数据便是被隐藏的重复cno
select cno,count(*) from product group by cno;
having 关键字
分组统计每组商品的平均价格,商品平均价格需要>60
select cno,avg(price) from product group by cno having avg(price)>60;
select cno,avg(price) as 平均价格 from product group by cno having 平均价格>60;
having和where的区别
having关键字后面可以接聚合函数,出现在分组之后,这个相当于是对结果过滤
where 关键字后面不可以接聚合函数,出现在分组之前
编写顺序
s ---f----w---g---h---o
select----from---where ---group by---having ---order by
执行顺序
f----w---g---h---s---o
from----where ----group by---having--select----order by
外键约束
forerign key
给product中的cno添加一个外键约束,这样,每次添加product,那么最后一个cno在class里就必须有与之对应的
不然添加不进去,且这个class的cid添加外键约束之后,class表里的cid就无法删除,必须要删除与cid对应的商品
才可以删除cid
alter table product add forerign key(cno) references class(cid)
现在有一个选课系统,我们给学生添加课程编号,但是如果一个学生要选很多课呢,很明显这种方法就不可行了
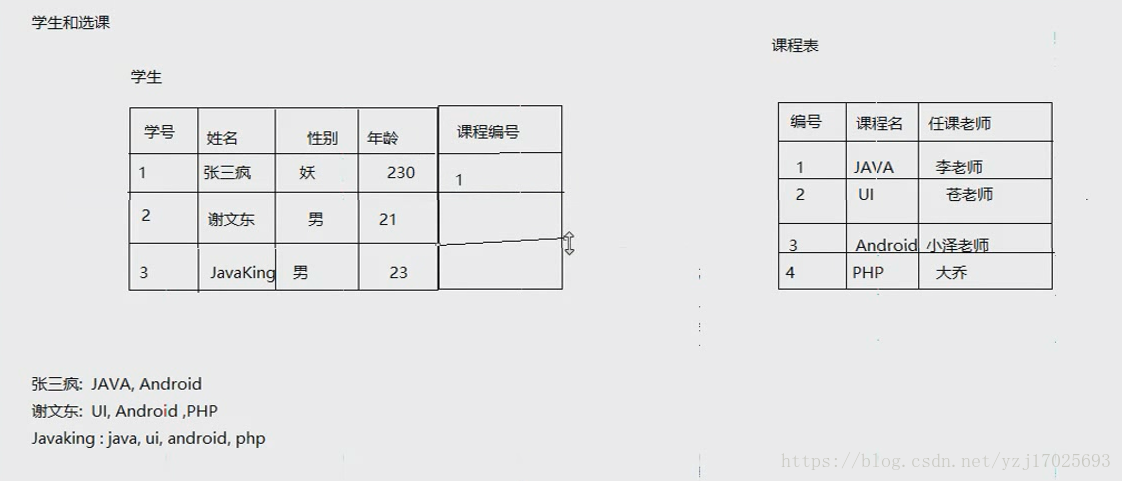
这个时候就要考虑多对多的原则了,就是说多个学生,选修多个课,这就是多对多

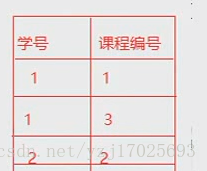
如果多对多的时候,就必须要再键一个表,拆成1对多的关系
商城案例,用户表和订单表是1对多,因为1个用户可以有很多订单 商品表和商品分类是多对1,因为多个不同的商品都有一个分类
订单表和商品表是多对多,因为多个商品可以有多个订单,那么多对多就需要新建立一张表了,这张表和俩边的表都需要构成1对多
订单编号1 商品编号1
订单编号1 商品编号2 意思就是说,1个订单号包括了2个商品
订单编号2 商品编号1 也可以1个订单号只包括一个 商品,所以这就是多对多,那么新建一张表就可以描述出来
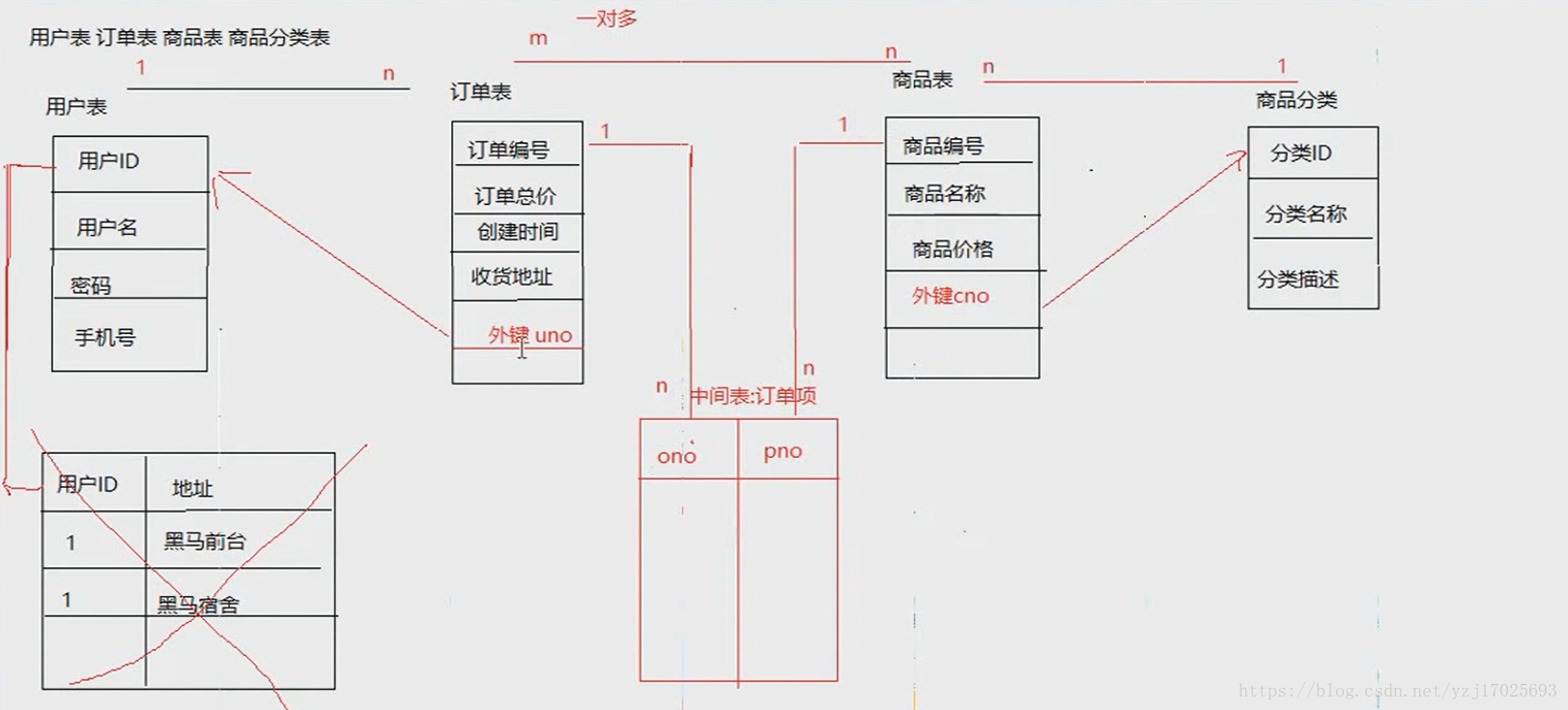
创建用户表
用户id 用户名 密码 手机号
create table user(uid int primary key auto_increment,username varchar(31),password varchar(31),phone varchar(11));
创建订单表
订单id 总价不能为空 时间 地址 外键约束,就是指定这个订单是哪个用户拥有的,
create table orders(oid int primary key auto_increment,sum int not null,otime timestamp,address varchar(100),unum
int,foreign key(unum) references user(uid));
商品表
商品id 商品名 价格 外键约束,指定这个商品的类的id
create table product(pid int primary key auto_increment,pname varchar(10),price double,cno int,foreign key(cno)
references class(cid));
商品类
商品类ID 类名 类描述
create table class(cid int primary key auto_increment,cname varchar(15),cdesc varchar(100));
中间表,订单表和商品表之间的
2个外键约束,一个订单的id,一个是商品的id,然后是商品的数量,商品的总价格
create table orderItem(ono int,pno int,foreign key(ono) references orders(oid),foreign key(pno) references
product(pid),ocunt int,subsum double);
给表中添加信息
添加商品分类
insert into class values(null,'手机','智能手机'),(null,'电脑','智能电脑'),(null,'零食','智能零食'),(null,'女朋友','充气女朋友');
添加商品
insert into product values(null,'小米',1000,1),(null,'苹果',5000,1),(null,'外星人',10000,2),(null,'辣条',2,3),(null,'方便面',5,3),(null,'徒儿版',998,4),(null,'韩红版',1998,4);
创建一个用户
insert into user values(null,'荒天帝','123','123456');
创建2个订单
insert into orders values(null,500,null,'地狱',1),(null,1000,null,'火星',1);
给订单添加物品,第1个订单有2个物品,第二个订单只有一个物品
insert into orderItem values(1,5,50,250),(1,2,125,250),(2,6,1,998);交叉连接查询 笛卡尔积
把俩张表合在一起,但是会把俩张表的每一条都对应,显示很多就和 1234 和1234有多少组合一样 11 12 13 14
相当于俩张表的乘积,而我们只需要11 22 33 44 一一对应即可
select * from product ,class;
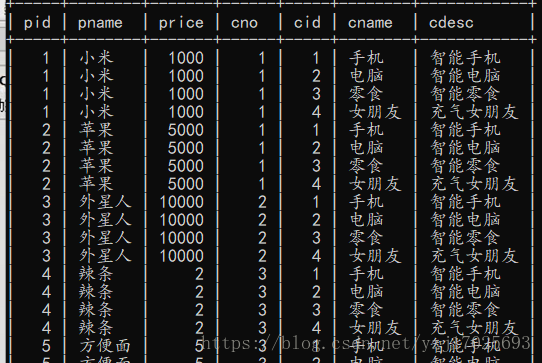
解决方法
select * from product,class where product.cno=class.cid;
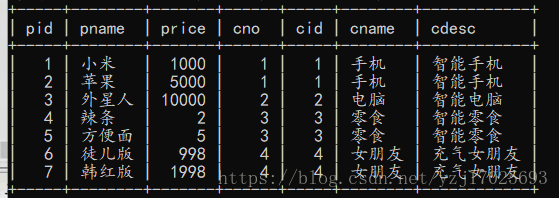
内连接查询
隐式内连接
查出的结果用where过滤
select * from product as p,class as c where p.cno=c.cid;
显示内连接
带着条件去查询,执行效率要高一点,且内外连接都都是显示交集,不会显示2边缺少的数据,而左右连接会
inner join on 都是关键字
select * from product as p inner join class c on p.cno=c.cid;
左外连接,右表中如果没有对应的数据,那么都用null填充,右外连接反之
select * from product as p left outer join class c on p.cno=c.cid;
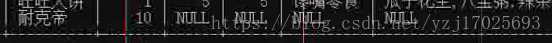
分页查询
索引从0开始,显示2条数据
select * from product limit 0,2;
select * from product limit 2,2; 从第3条开始,显示2条数据
子查询
查询分类名称为手机的所有商品
1 查询分类名为手机的id
select id from class where cname='手机';
2 查询id为1的所有商品
select * from product where product.cno=(select cid from class where cname='手机');
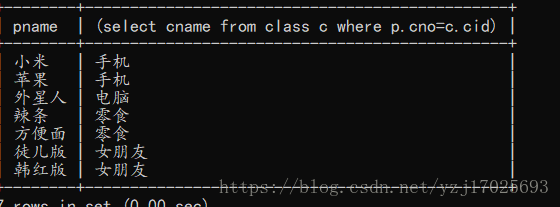
查询出所有商品的名称和其分类名
pname是商品的名称直接写,但是分类名,就必须要判断哪些名称对应哪些分类,用id来判断
这涉及了多表查询,既然是多表查询,那么就要考虑笛卡尔积,所以必须p.cno=c.cid,且id必须对应,不然分类就不对了
select p.pname,c.cname from product as p,class as c where p.cno=c.cid;
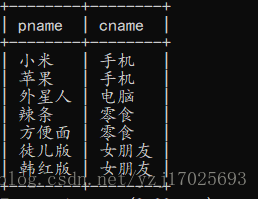
这个和上面的效果是一样,但是用的是子查询
select pname,(select cname from class c where p.cno=c.cid) from product as p;