1. ASCII码
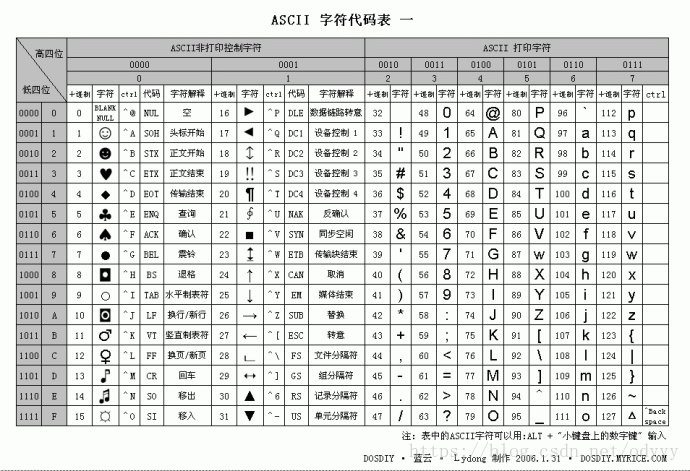
2. GB2312
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,况且有6000多个常用汉字需要保存呢。但是这难不倒智慧的中国人民,我们不客气地把那些127号之后的奇异符号们直接取消掉, 规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
中国人民看到这样很不错,于是就把这种汉字方案叫做"GB2312"。GB2312 是对ASCII 的中文扩展。
3. Unicode
由于世界各地都产生了自己的编码方案,这是给人的沟通带来了巨大麻烦。于是有一个叫做ISO的国际组织开始着手解决这个问题,想用一种规范来表示出所有的语言。于是Unicode就这样产生了。Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
3. UTF
UTF是 Unicode Transformation Format的缩写。是Unicode的一种实现方案。任何文字在Unicode中都对应一个值,这个值称为代码点也叫码位(CodePoint)。代码点的值通常写为:U+ABCD
public class Test1 {
public static void main(String[] args) throws Exception {
char ch = '\u6211';
System.out.println(ch);
}
} 4. HexString
将内存中的每个字节转换为两个十六进制的数,0001对应1,0011对应3以此类推,所以经过这样的转换一个字节的信息实际上要用两个字节来储存。
- 为什么在传输时要用HexString
一个多位的整数将按照其存储地址的最低或最高字节排列。如果最低有效位在最高有效位的前面,则称小端序;反之则称大端序。在网络应用中,字节序是一个必须被考虑的因素,因为不同机器类型可能采用不同标准的字节序,所以均按照网络标准转化。
5. Base64编码
Base64 是网络上常见的用于传输8bit字节代码的编码方式之一,可以将二进制转为“字符串”。在应用程序中常常需要把二进制数据编码为适合放在URL中的形式,此时采用Base64编码具有不可读性,即所编码的数据不会被人用肉眼直接看到。
6. URL编码
ios中http请求遇到汉字的时候,需要转化成UTF-8,用到的方法是:数据请求是URL含有中文,需要转码为UTF8
NSString * encodingString = [urlString stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];请求后,返回的数据,如何显示的是这样的格式:%3A%2F%2F,此时需要我们进行UTF-8解码,用到的方法是:
NSString *str = [model.album_name stringByReplacingPercentEscapesUsingEncoding:NSUTF8StringEncoding];