1.内存相关知识
C++使用三种(C++11是四种)不同的方案来存储数据,这些方案的区别在于数据保留在内存中的时间。
自动存储持续性:在函数定义中声明的变量(包括函数参数)的存储持续性为自动。它们在程序开始执行其所属的函数或代码块时被创建,在执行完函数或代码块时,它们使用的内存被释放。C++有两种存储持续性为自动的变量。
静态存储持续性:在函数定义外定义的变量和使用关键字static定义的变量的存储持续性都为静态。它们在程序整个运行过程中都存在。C++为静态存储持续性变量提供了3种链接性:外部链接性(可在其他文件中访问),内部链接性(只能在当前文件中访问)和无链接性(只能在当前函数或代码块中访问)。
线程存储持续性(C++11):当前,多核处理器很常见,这些CPU可同时处理执行多个任务,这让程序能够将计算放在可并行处理的不同线程中。如果变量使用关键字thread_local声明的,则其生命周期与所属的线程一样长。
动态存储持续性:用new运算符分配的内存将一直存在,直到使用delete运算符将其释放或程序结束为止。这种内存的存储持续性为动态,有时被称为自由存储(free store)或堆(heap)。
2.作用域和链接
作用域描述了名称在文件的多大范围内可见。链接性描述了名称如何在不同单元间共享。链接性为外部的名称可在文件间共享,链接性为内部的名称只能由一个文件中的函数共享。自动变量的名称没有链接性,因为他们不能共享。
C++变量的作用域有多种。作用域为局部的变量只在定义它的代码块中可用。代码块是由花括号括起的一系列语句。作用域为全局的变量在定义位置到文件结尾之间都可以用。自动变量的作用域为局部,静态变量的作用域是全局还是局部取决于它是如何被定义的。在函数原型作用域中使用的名称只在包含参数列表的括号内可用。在类中声明的成员作用域为整个类。在命名空间中声明的变量的作用域为整个命名空间。
C++函数的作用域可以是整个类或整个命名空间,但不能是局部的。
3.自动变量和栈
栈是LIFO(先进后出)的,即最后加入到栈中的变量首先被弹出。这种设计简化了参数传递。函数调用将其参数的值放在栈顶,然后重新设置栈顶指针。被调用的函数根据其形参描述来确定每个参数的地址。下图所示,函数fib()被调用时,传递一个2字节的int和一个4字节的long。这些值被加入到栈中。当fib()开始执行时,它将名称real和tell同这两个值关联起来。当fib()结束时,栈顶指针重新指向以前的位置。新值没有被删除,但不在被标记。
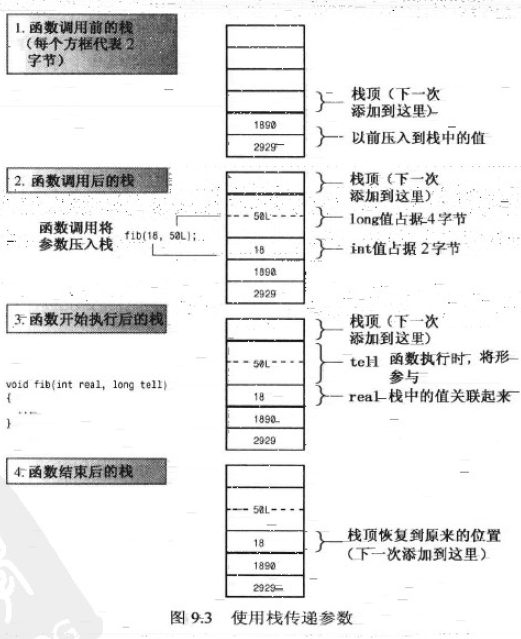
使用栈传递参数
4.再谈const
在C++中,const限定符对默认存储类型稍有影响。在默认情况下全局变量的链接性为外部的,但const全局变量的链接性为内部的。也就是说,在C++看来,全局const定义就像使用了static说明符一样。
C++修改了常量类型的规则,让程序员更轻松。例如,假设将一组常量放在头文件中,并在同一个程序的多个文件中使用该头文件。那么,预处理器将头文件的内容包含到每个源文件中后,所有的源文件都将包含类似下面这样的定义:
const int fingers = 10;
const char* warning = "walk";// extern would be required if const had external linkage
extern const int fingers; // can't be initialize
extern const char* warning;内部链接性还意味着,每个文件都有自己的一组常量,而不是所有文件共享一组常量。每个定义都是其所属文件私有的,这就是能够将常量定义放在头文件中的原因。这样,只要在两个源代码文件中包含同一个头文件,则它们将获得同一组常量。
如果处于某种原因,程序员希望某个常量的链接性为外部的,则可以使用extern关键字来覆盖默认的内部链接性:
extern const int states = 50; // definition with external linkage在函数或代码块中声明const时,其作用域为代码块,即仅当程序执行该代码块中的代码时,该常量才是可用的。这意味着在函数或代码块中创建常量,不必担心其名称与其他地方定义的常量发生冲突。
5.函数和链接性
和变量一样,函数也有链接性,虽然可选择的范围比变量小。和C语言一样,C++不允许在一个函数中定义另外一个函数,因此所有函数的存储持续性都自动为静态的,即在整个程序执行期间都一直存在。在默认情况下,函数的链接性为外部的,即可以在文件间共享。实际上,可以在函数原型中使用关键字extern来指出函数是在另一个文件中定义的,不过这是可选的。还可以使用关键字static将函数的链接性设置为内部的,使之只能在一个文件中使用。必须同时在原型和函数定义中使用该关键字:
static int private(double x);
static int privete(double x)
{
}单定义规则也适用于非内联函数,因此对于每个非内联函数,程序只能包含一个定义。对于链接性为外部的函数来说,这意味着在多文件程序中,只能由一个文件包含该函数的定义,但使用该函数的每个文件都应包含其函数原型。
内联函数不受这项规则的约束,这允许程序员能够将内联函数的定义放在都文件中,这样,包含了头文件的每个文件都有内联函数的定义。然而,C++要求同一个函数的所有内联定义都是必须相同的。
6.语言链接性
另一种形式的链接性——称为语言链接性也对函数有影响。链接程序要求每个不同的函数都有不同的符号名。在C语言中,一个名称只对应一个函数,因此这很容易实现。为满足内部需要,C语言编译器可能将spiff这样的函数名翻译为_spiff。这种方法被称为C语言链接性。但在C++中,同一个名称可能对应多个函数,必须将这些函数翻译为不同的符号名称。因此,C++编译器执行名称矫正或名称修饰,为重载函数生成不同的符号名称。例如可能将spiff(int)转换为_spiff_i,而将spiff(double,double)转换为_spiff_d_d。这种方法被称为C++语言链接。
链接程序寻找与C++函数调用匹配的函数时,使用的方法与C语言不同。但如果要在C++程序中使用C库中预编译的函数,将出现什么情况呢?例如,假设如下代码:
spiff(22); // want spiff(int) from a C library
它在C库文件中的符号名称为_spiff,但对于我们假设的链接程序来说,C++查询约定是查找符号名称_spiff_i。为解决这种问题,可以用函数原型来指出要使用的约定:
extern "C" void spiff(int); // use C protocol for name look-up
extern void spiff(int); // use C++ protocol for name look-up
extern "C++" void spiff(int); // use C++ protocol for name look-up
第一个原型使用C语言链接性;而后面的两个使用C++语言链接性。第二个原型是通过默认方式指出这一点,而第三个显式地指出了这一点。
C和C++链接性是C++标准指定的说明符,但实现可提供其他语言链接性说明符。
7.定位new运算符
通常,new负责在堆(heap)中找到一个足以能够满足要求的内存块。new运算符还有另一种变体,被称为定位(placement)new运算符,它让你能够指定要使用的位置。程序员可能使用这种特性来设置其内存管理规程,处理需要通过特定地址进行访问的硬件或在特定位置创建对象。
要使用特定new特性,首先需要包含头文件new,它提供了这种版本的new运算符的原型,然后将new运算符用于提供了所需地址的参数。除需要指定参数外,句法与常规new运算符相同。具体地说,使用定位new运算符时,变量后面可以由方括号,也可以没有。下面的代码段演示了new运算符的4种用法:
#include <new>
struct chaff
{
char dross[20];
int slag;
};
char buffer1[50];
char buffer2[500];
int main()
{
chaff *p1, *p2;
int *p3, *p4;
// first, the regular forms of new
p1 = new chaff; // place structure in heap
p3 = new int[20]; // place int array in heap
// now, the two forms of placement new
p2 = new (buffer1) chaff; // place structure in buffer1
p4 = new (buffer2) int[20]; // place int array in buffer2
}熟悉定位new运算符后,来看另一段代码。使用常规new运算符好定位new运算符创建动态分配数组。以下代码说明了常规new运算符和定位new运算符之间的一些重要差别。
#include <iostream>
#include <new> // for placement new
using namespace std;
const int Buf = 512;
const int N = 5;
char buffer[Buf]; // chunk of memory
int main()
{
double *pd1, *pd2;
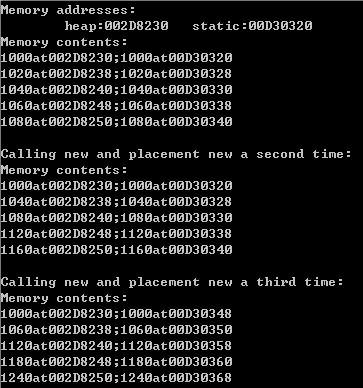
cout << "Calling new and placement new:" << endl;
pd1 = new double[N]; // use heap
pd2 = new (buffer) double[N]; // use buffer array
for (int i = 0; i < N; i++)
pd2[i] = pd1[i] = 1000 + 20 * i;
cout << "Memory addresses:\n" << " heap:" << pd1 << " static:" << (void*)buffer << endl;
cout << "Memory contents:" << endl;
for (int i = 0; i < N; i++)
{
cout << pd1[i] << "at" << &pd1[i] << ";";
cout << pd2[i] << "at" << &pd2[i] << endl;
}
cout << "\nCalling new and placement new a second time:" << endl;
delete[] pd1;
double *pd3, *pd4;
pd3 = new double[N]; // find new address
pd4 = new (buffer) double[N]; // overwrite old data
for (int i = 0; i < N; i++)
{
pd4[i] = pd3[i] = 1000 + 40 * i;
}
cout << "Memory contents:" << endl;
for (int i = 0; i < N; i++)
{
cout << pd3[i] << "at" << &pd3[i] << ";";
cout << pd4[i] << "at" << &pd4[i] << endl;
}
cout << "\nCalling new and placement new a third time:" << endl;
delete[] pd3;
pd1 = new double[N];
pd2 = new (buffer + N * sizeof(double)) double[N];
for (int i = 0; i < N; i++)
{
pd2[i] = pd1[i] = 1000 + 60 * i;
}
cout << "Memory contents:" << endl;
for (int i = 0; i < N; i++)
{
cout << pd1[i] << "at" << &pd1[i] << ";";
cout << pd2[i] << "at" << &pd2[i] << endl;
}
delete[] pd1;
return 0;
}