1、概述
在继续学习tensorflow之前,我想先写一下python爬虫的内容,作为深度学习的一个技能补充。深度学习需要用到大量的训练数据,没有爬虫靠人工下载,工作量不敢想象。学会爬虫就可以去爬一些收集训练数据需要(或喜欢)的网站了。如果想深入学习爬虫,推荐这本书《精通Python网络爬虫+核心技术、框架与项目实战》,下载链接为:
https://download.csdn.net/download/rookie_wei/10469974
1、Urllib库
Urllib库是python的一个用于操作URL的库,Python2.X中分为Urllib库和Urllib2库,Python3.X之后将其合并到Urllib库。这一节用的是Python3.5.
2.1、使用Urllib爬取网页
使用Urllib爬取网页很简单,首先导入Urllib模块,
import urllib.request as ur然后用urllib.request.urlopen打开并爬取一个网页,
urlfile = ur.urlopen("http://www.baidu.com")再用read将网页内容读取出来,然后,打印看看,
data = urlfile.read()
print(data)运行结果:
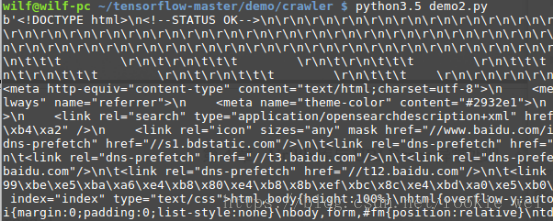
当然也可以用readline函数只读取一行的内容,就不演示了。
如果想将爬取的网页保存到本地文件,那么先open一个本地文件,再write数据,最后close关闭文件即可,代码如下。
fd = open("baidu.html", "wb")
fd.write(data)
fd.close()运行以后,发现本地多了个baidu.html文件,用浏览器运行,得到界面如下,
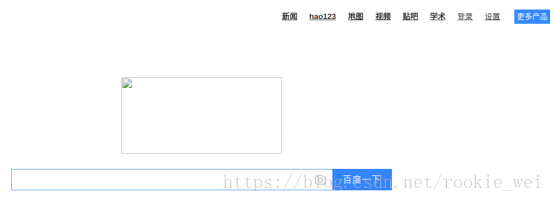
就这么简单的将百度首页爬取到了本地,只是没将图片爬取到本地而已。
Urllib库还提供了一个直接将网页写入本地文件的方法urllib.request.urlretrieve函数,代码如下:
ur.urlretrieve("https://blog.csdn.net/rookie_wei",filename="rookie_wei.html")Urllib的其他用法这里就不一一介绍了,自己百度吧。
2.2、模拟浏览器访问
如果只用上面的方法去访问网页,有些网页为了防止恶意爬虫会进行一些反爬虫设置,就会返回403错误。为了避免这个错误,我们可以设置一些Headers信息,模拟成浏览器去访问这些网站。
打开浏览器的开发者工具(F12键),点击“Network”,

然后打开任意网站(比如百度),可以看到工具窗口出现一些数据,

点击任意一个数据,看到右边出现一个窗口,Headers标签就是头信息,将右边窗口往下滚动,可以找到“User-Agent”标签,
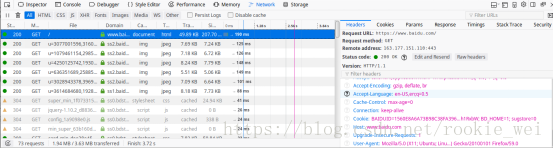
这个就是模拟浏览器访问需要用到的信息,将其复制下来,得到信息:Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0
可以用两种方法将我们的爬虫模拟成浏览器访问。
方法一:使用build_opener()修改报头
urlopen不支持一些HTTP高级功能,可以使用urllib.request.build_opener,代码如下,
#encoding:utf-8
import urllib.request as ur
url = "https://blog.csdn.net/rookie_wei"
headers = ("User-Agent", "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0")
opener = ur.build_opener()
opener.addheaders = [headers]
data = opener.open(url).read()
print(data)运行结果跟上面的一样。
方法二:使用add_header()添加报头
直接上代码,
#encoding:utf-8
import urllib.request as ur
url = "https://blog.csdn.net/rookie_wei"
req = ur.Request(url)
req.add_header("User-Agent", "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0")
data = ur.urlopen(req).read()
print(data)运行结果跟上面的一样。
2.3、设置超时时间
有时候访问一个网页,如果网页长时间未相应,那么系统就会判断该网页超时,即无法打开网页。有时候我们需要自己设置超时的时间值,方法很简单,在使用urlopen时,设置timeout的值即可,单位是秒。例如,
urlfile = ur.urlopen("https://blog.csdn.net/rookie_wei", timeout=30)2.4、使用代理服务器
有时候使用同一个IP高频地去爬取同一个网站,久了之后,可能会被网站的服务器屏蔽,解决这个问题的方法就是使用代理服务器去访问。使用代理服务器去爬取网站时,对方网站显示的是代理服务器的IP地址,即使这个地址被屏蔽了,我们换个代理就是了。
下面的网站提供了很多代理服务器的地址,
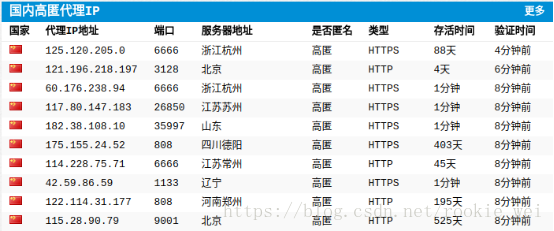
有了代理服务器,下面就可以上示例代码了,
#encoding:utf-8
import urllib.request as ur
def use_proxy(proxy_addr, url):
proxy = ur.ProxyHandler({'http':proxy_addr})
opener = ur.build_opener(proxy, ur.HTTPHandler)
ur.install_opener(opener)
data = ur.urlopen(url, timeout=30).read().decode('utf-8')
return data
proxy_addr = '121.196.218.197:3128'
data = use_proxy(proxy_addr, 'https://blog.csdn.net/rookie_wei')
print(data)如果有些代理不能用了,换一个就是了。
2.5、异常处理
程序在执行过程中难免发生异常,如果不处理,有可能导致整个程序异常退出。python的异常处理也是使用try...except语句,在try中执行主要代码,在except中捕获异常信息,并进行相应处理。这个比较简单,我就不详细讲了,但是这个内容还是很重要的,直接上个例子吧。
#encoding:utf-8
import urllib.request as ur
import urllib.error as ue
try:
ur.urlopen('https://blog.csdn.net/rookie_weia')
except ue.URLError as e:
print('我出现异常啦!')
print(e.code)
print(e.reason)运行结果:

我故意访问一个不存在的网址,可以看到发生异常后,程序会执行except里的代码。
3、正则表达式
正则表达式在爬虫中很重要。正则表达式就是描述字符串排列的一套规则,比如,我们想找出一个网页中所有图片,其他的信息过滤掉,那么就观察图片的格式,然后写一个正则表达式来表示所有的图片,等等。
3.1、原子:
原子是正则表达式最基本的组成单元,每个正则表达式中至少要包含一个原子。常见的原子分为普通字符作为原子、非打印字符作为原子、通用字符作为原子、原子表。下面就来分别讲解。
(1)普通字符作为原子
普通字符,即数字、大小写字母、下划线等,例如将”wei”作为原子使用,这这里有三个原子,分别是”w”、”e”、”i”,举个示例。代码如下,
import re
pattern = 'wei'
str = '_wei'
result = re.search(pattern, str)
print(result)运行结果:

python中使用正则表达式需要用到re模块,pattern变量定义了正则表达式的值,然后使用re模块的search函数在str字符串里匹配对应的正则表达式,然后将结果返回给变量result。从打印结果可以看出,span表示匹配的位置,match表示匹配结果。如果匹配失败,则返回None,可以将字符串改为str = '_wedi'输出结果为,

(2)非打印字符作为原子
非打印字符作为原子指的是一些在字符串中用于格式控制的符号,如换行符”\n”等。

(3)通用字符作为原子
通用字符作为原子,即一个原子可以匹配一类字符。常见通用字符及其含义如下表所示,

例如,我们可以使用”\w\dwei\w”对”wei”字符匹配,则“12weia”、“w2wei_”都可以匹配成功。
(4)原子表
原子表可以定义一组地位平等的原子,然后匹配时会取该原子表中任意一个原子进行匹配,python中原子表用[]表示,例如[abc]就是一个原子表,假设我们定义正则表达式为”[abc]wei”,源字符串为”cweifang”,则用re.search函数匹配,匹配的结果就是“cwei”。如果源字符串为”wei”,则不匹配,返回None。
[^]则表示除了括号内的原子以外,都可以匹配,比如定义正则表达式为”[^abc]wei”,源字符串为”cweifang”,则不匹配,源字符串为”zwei”则匹配。
3.2、元字符
元字符,就是正则表达式中具有一些特殊含义的字符,比如重复N此前面的字符等,常见元字符如下表所示,
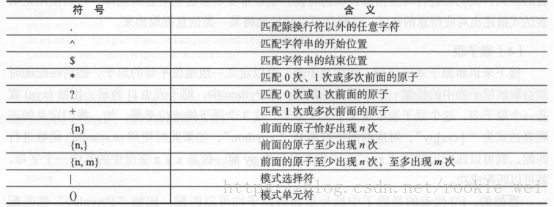
3.3、模式修正
模式修正,即可以在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整等功能。

举个例子,
import re
pattern1 = 'wei'
pattern2 = 'wei'
str = 'ahWeiqew'
print(re.search(pattern1, str))
print(re.search(pattern2, str, re.I))运行结果:

3.4、正则表达式常见函数
re.match函数:
该函数从源字符串的起始位置匹配一个模式,函数的格式为,
re.match(pattern, string, flags=0)
第一个参数是表达式,第二个参数是源字符,第三个参数是可选参数,代表对应的标志位,可以放模式修正等信息。示例代码如下,
import re
pattern1 = '.wei'
str = 'aWeiqew'
print(re.match(pattern1, str, re.I))运行结果:

re.search函数:
re.search函数会扫描整个字符串进行匹配,而re.match函数从字符串开头进行匹配,它们用法是一样的。
re.compile和findall函数
前面介绍的两个函数,即使源字符串中含有多个匹配结果,也只会返回一个,而re.compile函数和findall函数的组合使用则可以将符合模式的内容全部匹配出来。示例代码如下,
import re
str = 'aWeiqew8732weiadnwei2103_wei'
pattern = re.compile('.wei.')
print(pattern.findall(str))运行结果:

4、多线程
使用多线程会使爬虫效率大大提高,比如在爬取图片的爬虫中,开启一个线程获取图片的url地址,一个线程进行下载,则比单个线程先获取图片url再下载的效率高很多。这里就简单介绍python的多线程。
import threading
class A(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
for i in range(1000):
print('我是线程A')
class B(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
for i in range(1000):
print('我是线程B')
t1 = A()
t1.start()
t2 = B()
t2.start()运行结果:

总结:
这一节就先学习爬虫的一些最基本的知识,如果想深入学习的话,推荐我在概述里给的那本书。我的目的不是成为爬虫高手,只要满足爬取我需要的训练数据即可。讲了这么多屁话有什么用?下一节就来两个真实的爬虫示例,一个是爬取汽车之家的汽车厂商及车型,还有一个是在爬取百度图片中爬取我们想搜索的图片。学完之后,就可以爬一些喜欢的小网站的图片和视频了。