最近,我们的团队负责编写一个高性能的缓存服务。目标很明确,但可以通过多种方式实现。最后,我们决定尝试新的技术使用Go实现该服务。
目录:
- 需求
- 为什么用GO
- 缓存
- 并发
- 过期
- 省略垃圾收集器
- BigCache
- HTTP服务器
- JSON反序列化
- 结论
- 概要
需求
根据需求,我们的服务应该:
- 使用HTTP协议来处理请求
- 处理10k rps(写入为5k,读取为5k)
- 缓存数据至少10分钟
- 响应时间(不包括在网络上花费的时间)低于
- 5ms - 平均
- 10ms - 99.9%满足
- 400ms - 99.999%满足
- 处理包含JSON消息的POST请求,其中每条消息:
- 包含一个条目及其ID
- 不大于500字节
- 在通过POST请求添加条目后立即通过GET请求检索条目并返回int(一致性)
简单来说,我们的任务是编写一个带有过期和REST接口的快速字典。
为什么用GO
我们公司的大多数微服务都是用Java或其他基于JVM的语言编写的,有些是用Python编写的。我们还有一个用PHP编写的单一的遗留平台,但除非必须,否则我们不会触摸它。我们已经了解这些技术,但我们愿意探索新技术。我们的任务可以用任何语言实现,因此我们决定在Go中编写它。
Go已经有一段时间了,有大公司和不断增长的用户社区支持。它被宣传为编译的,并发的,命令式的,结构化的编程语言。它还具有托管内存,因此它看起来比C / C ++更安全,更容易使用。我们对使用Go编写的工具有很好的经验,并决定在这里使用它。我们在Go有一个开源项目,现在我们想知道Go如何处理大流量。使用Go我们相信整个项目只需要不到100行代码,并且足够快可以满足我们的要求。
缓存
为了满足要求,缓存本身需要:
- 即使有数百万条目,也要非常快
- 提供并发访问
- 过期后清除
考虑到第一点,我们决定放弃外部缓存,如Redis,Memcached或Couchbase,主要是因为网络需要额外的时间。因此,我们专注于内存缓存。在Go中已经存在这种类型的缓存,即LRU组缓存, go-cache,ttlcache,freecache。只有freecache满足了我们的需求。接下来的子章节揭示了为什么我们决定自己推销自己,并描述如何实现上述特征。
并发
我们的服务会同时收到许多请求,因此我们需要提供对缓存的并发访问。实现这一目标的简单方法是放在sync.RWMutex缓存访问功能之前,以确保一次只能修改一个goroutine。然而,其他想要对其进行修改的goroutine也会被阻止,从而成为瓶颈。为了消除这个问题,可以使用切片。切片背后的想法很简单。创建N个切片的数组,每个切片包含其自己的具有锁的缓存实例。当需要缓存具有唯一键的项时,首先由该函数选择它的切片hash(key) % N。在获取缓存锁并发生对缓存的写入之后。项目读数是类似的。当切片的数量相对较高并且哈希函数返回唯一键的正确分布的数字时,则锁竞争几乎可以最小化为零。这就是我们决定在缓存中使用切片的原因。
过期
从缓存中删除过期元素的最简单方法是将它与FIFO队列一起使用。将条目添加到缓存时,会发生另外两个操作:
- 在队列末尾添加包含密钥和创建时间戳的条目。
- 从队列中读取最旧的元素。将其创建时间戳与当前时间进行比较。当它晚于驱逐时间时,队列中的元素与其在缓存中的相应条目一起被删除。
由于已经获取了锁,因此在写入缓存期间执行删除。
省略垃圾收集器
在Go中,如果使用Map,垃圾收集器(GC)将在标记和扫描阶段查询该Map的每个元素。当Map足够大(包含数百万个对象)时,这会对应用程序性能产生巨大影响。
我们对我们的服务进行了一些测试,我们在其中为数百万条目提供缓存,之后我们开始向一些不相关的REST端点发送请求,只执行静态JSON序列化(它根本没有触及缓存)。对于空缓存,此端点的最大响应延迟为10k rps,为10ms。当缓存填满时,它有超过第99%的延迟。度量标准表明堆中有超过40万个对象,GC标记和扫描阶段耗时超过4秒。测试结果表明,如果我们想要满足与响应时间相关的要求,我们需要跳过GC以获取缓存条目。我们该如何做?有下面三种解决办法。
GC仅限于堆,所以第一种就是堆外。有一个项目可以帮助解决这个问题,称为offheap。它提供自定义功能Malloc()并Free()管理堆外部的内存。但是,需要实现依赖于这些功能的缓存。
第二种方法是使用freecache。Freecache通过减少指针数来实现零GC开销的映射。它将键和值保存在环形缓冲区中,并使用索引切片查找条目。
省略GC用于缓存条目的第三种方法与Go 1.5中提供的优化有关。此优化表明,如果您在键和值中使用没有指针的映射,则GC将省略其内容。这是一种保持堆积并省略GC以获取Map中条目的方法。但是,它不是最终解决方案,因为Go中的所有内容基本上都是基于指针构建的:结构,切片,甚至是固定数组。只有原函数喜欢int或bool不接触指针。那么我们可以用map[int]int做些什么呢?因为我们已经生成了哈希键以便从缓存中选择正确的切片(在并发中描述),所以我们将它们重用为我们的密钥map[int]int。但是int类型的价值呢?我们可以保留哪些信息做为int?我们可以保留条目的偏移量。另一个问题是,为了再次省略GC,可以保留这些条目吗?可以分配大量字节,并且可以将条目序列化为字节并保留在其中。在这方面,值map[int]int可以指向一个条目,其中条目在建议的数组中开始。并且由于FIFO队列用于保存条目并控制它们的删除(在Eviction中描述),因此可以重建它并基于巨大的字节数组,该映射的值也将指向该数组。
在所有呈现的场景中,都需要进入(de)序列化。最后,我们决定尝试第三种解决方案,因为我们很好奇它是否能够工作并且我们已经拥有大多数元素 - 哈希键(在切片选择阶段计算)和条目队列。
BigCache
为了满足本章开头提出的要求,我们实现了自己的缓存并将其命名为BigCache。BigCache提供切片,过期删除,并省略了GC用于缓存条目。因此,即使对于大量数据,它也是非常快速的缓存。
Freecache是Go中唯一可用的内存缓存,它提供了这种功能。Bigcache是它的替代解决方案,并以不同的方式减少GC开销,因此我们决定与它共享:bigcache。有关freecache和bigcache之间比较的更多信息,请访问github。
HTTP服务器
内存分析器向我们显示在请求处理期间分配了一些对象。我们知道HTTP处理程序将成为我们系统的热点。我们的API非常简单。我们只接受POST和GET来上传和下载缓存中的元素。我们实际上只支持一个URL模板,因此不需要功能齐全的路由器。我们通过剪切前7个字母从URL中提取ID,它运行的很好。
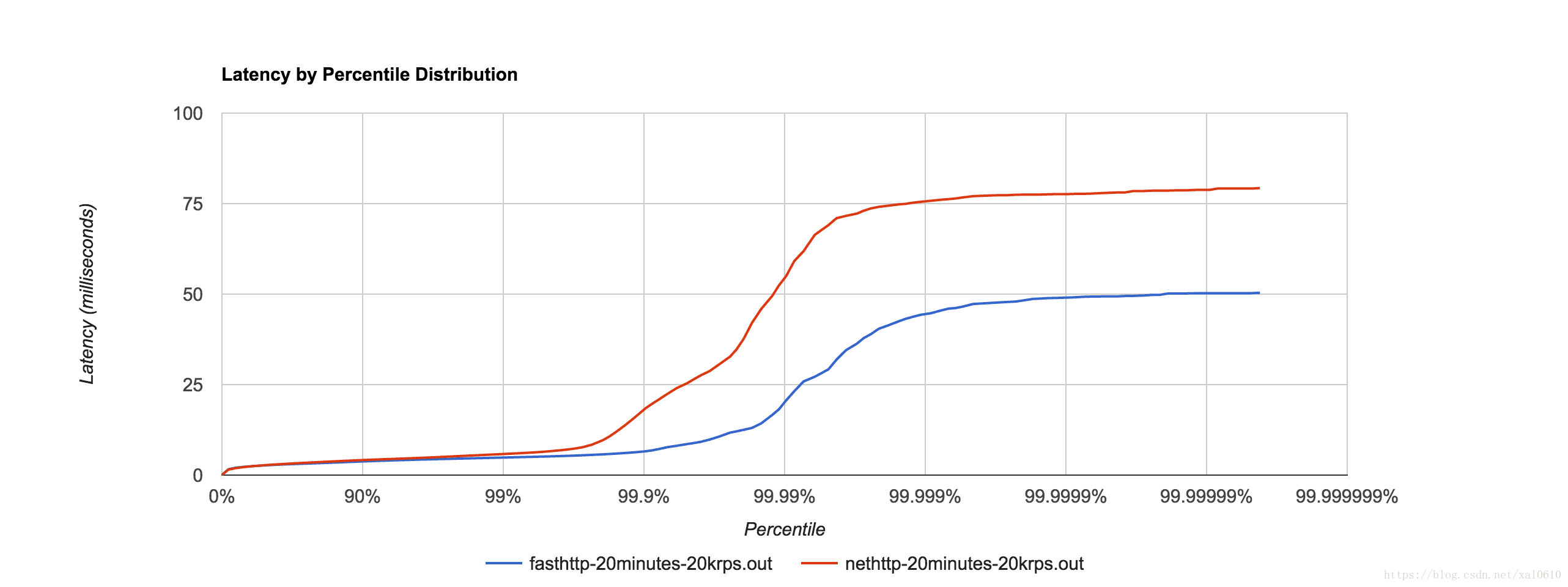
当我们开始开发时,Go 1.6在RC中。我们减少请求处理时间的第一个努力是更新到最新的RC版本。在我们的案例中,表现几乎相同。我们开始寻找更高效的东西,我们找到了 fasthttp。它是一个提供零分配HTTP服务器的库。根据文档,它在合成测试中比标准HTTP处理程序快10倍。在我们的测试中,结果发现它只快了1.5倍,但仍然更好!
fasthttp通过减少HTTP Go包的工作来提高其性能。例如:
- 它将请求生命周期限制在实际处理的时间
- 请求头是懒惰解析(我们真的不需要请求头)
不幸的是,fasthttp并不是标准http的真正替代品。它不支持路由或HTTP / 2并声称不支持所有HTTP边缘技术。它适用于具有简单API的小型项目,因此我们会坚持使用默认HTTP进行正常(非超级性能)项目。
JSON反序列化
在分析我们的应用程序时,我们发现该程序在JSON反序列化上花费了大量时间。内存分析器还报告说,处理了大量数据json.Marshal。它并没有让我们感到惊讶。对于10k rps,每个请求350个字节可能是任何应用程序的重要负载。然而,我们的目标是速度,所以我们研究了它。
我们听说Go JSON序列化程序没有其他语言那么快。大多数基准测试都是在2013年完成的,所以在1.3版之前。当我们看到问题-5683声称Go比Python慢3倍并且 邮件列表说它比Python simplejson慢5倍时,我们开始寻找更好的解决方案。
如果您需要速度,JSON over HTTP绝对不是最佳选择。不幸的是,我们所有的服务都以JSON相互通信,因此合并新协议超出了此任务的范围(但我们正在考虑使用avro,就像我们为Kafka所做的那样)。我们决定坚持使用JSON。快速搜索为我们提供了一个名为ffjson的解决方案。
ffjson文档声称它比标准快2-3倍json.Unmarshal,并且使用更少的内存来完成它。
| JSON | 16154 ns / op | 1875年B / op | 37 allocs / op |
| ffjson | 8417 ns / op | 1555 B / op | 31 allocs / op |
我们的测试证实,ffjson比内置的解组器快了近2倍并且执行的分配更少。怎么可能实现这个目标?
首先,为了从ffjson的所有功能中受益,我们需要为struct生成一个unmarshaller。生成的代码实际上是一个扫描字节的解析器,并用数据填充对象。如果你看一下JSON语法,你会发现它非常简单。ffjson利用了解结构的确切内容,只解析结构中指定的字段,并在发生错误时快速失败。标准编组程序使用昂贵的反射调用来在运行时获取结构定义。另一个优化是减少不必要的错误检查。json.Unmarshal将更快地执行更少的alloc,并跳过反射调用。
| json(无效的json) | 1027 ns / op | 384 B / op | 9 allocs / op |
| ffjson(无效的json) | 2598 ns / op | 528 B / op | 13 allocs / op |
有关ffjson如何工作的更多信息,请点击此处。基准测试可在此处获得
结论
最后,我们将应用程序从2.5秒以上加速到不到250毫秒,以获得最长的请求。这些时间只发生在我们的用例中。我们相信,对于更多的写入或更长的过期时间,访问标准缓存可能需要更多的时间,但是使用bigcache或freecache它可以保持毫秒级别,因为消除了长GC暂停的问题。
下图显示了优化服务之前和之后的响应时间的比较。在测试期间,我们发送了10k rps,其中5k是写入,另外5k是读取。过期时间设定为10分钟。测试时间为35分钟。

最终结果是隔离的,具有与上述相同的设置。

概要
如果您不需要高性能,请坚持使用标准库。它们保证可以维护,并且具有向后兼容性,因此升级Go版本应该是顺畅的。
我们用Go编写的缓存服务终于满足了我们的要求。我们花费大部分时间来确定GC停顿会对应用程序响应能力产生巨大影响,因为它控制着数百万个对象。幸运的是,像bigcache或freecache这样的缓存解决了这个问题。