1.Kafka的基本操作
我们知道Kafka使用的是主题,下面我们就来创建一个简单的主题
a.创建主题
$>bin/kafka-topics.sh --create --zookeeper s10:2181 --replication-factor 3 --partitions 3 --topic test
我们在创建主题的时候看到有两个参数分别是replication和partitions 。Kafka通过设置副本数replication来保证可靠性,注意我们在设置副本的数量的时候,这个数值一定要小于等于Kafka启动的集群数量,否则会出错。Kafka通过设置分区partitions数来快速读写,保证支持数千个客户端同时读写。还记得Hive的分区表么,功能类似。

b.查看主题列表
$>bin/kafka-topics.sh --list --zookeeper s10:2181

c.启动控制台生产者
$>bin/kafka-console-producer.sh --broker-list s10:9092 --topic test

d.启动控制台消费者
$>bin/kafka-console-consumer.sh --bootstrap-server s10:9092 --topic test --from-beginning

最后的参数--from-beginning说明了这个消费者表示要从头开始读,之前kafka已经在分区中保存了一些数据(我在主题test之后测试的数据所以消费者如果设置了从头开始读数据的话,数据会显示出来)。Kafak在消费者读取数据的时候会记录消费者读取数据的位置,这个参数当然也可以省略

e.在生产者控制台输入hello world
现在的生产者和消费者都处于阻塞的状态,我们来再生产者发一句话,看看消费者接受的情况。生产者输入HELLO WORLD
生产者:

消费者:

2.Kafka的工作流程
还记得我们之前说的大数据系列之系统服务zookeeper么。我们说过,集群在启动的时候会向zookeeper注册信息,包括Hadoop的高可用,Hbase等等。那么Kafak也不例外,Kafka集群在启动的时候也会在zookeepr上注册信息,我们先来看一下Kafka在启动集群的时候,其在zookeeper都注册了什么信息(别忘了zookeeper的数据结构:目录 数据)。打开zookeeper的客户端:
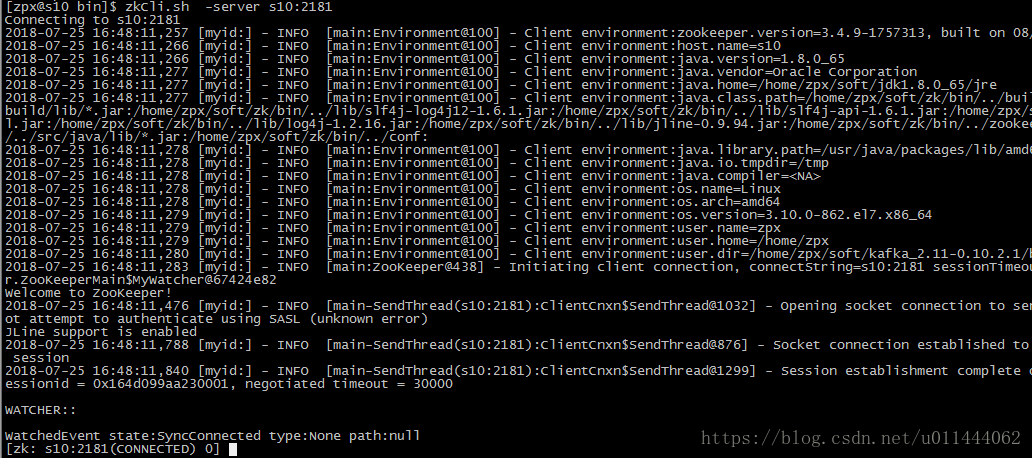

我们可以看到,多了很多的信息:
/controller:{"version":1,"brokerid":11,"timestamp":"1532508178488"}
我们发现有个"brokerid":11,说明了此时s11是主控制器(我配置的brokerid是这样:s10:10,s11:11,s12:12)
/brokers:[ids, topics, seqid]
/brokers/ids:[11, 12, 10]
我们之前给Kafka集群的每台主机都设置了一个id号用来标识他们
/brokers/ids/11:{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://s11:9092"],"jmx_port":-1,"host":"s11","timestamp":"1532508180720","port":9092,"version":4}
ids记录每个节点的链接信息,包括:时间戳和终端。消费者可以通过查看ids来或者Kafka的集群信息。
/brokers/topics:[test, __consumer_offsets]
记录了我们创建的主题test已经消费者的数据偏移量
/brokers/topics/test: [partitions]
我们之前创建了3个分区,都在这个目录下
/brokers/topics/test/partitions:[0, 1, 2]
/brokers/topics/test/partitions/0:[state]
/brokers/topics/test/partitions/0/state:{"controller_epoch":16,"leader":10,"version":1,"leader_epoch":35,"isr":[11,10,12]}
在主题test的0号分区里面我们看到,有两个重要的信息,leader:10,请注意:Kafak中只用分区才有leader这个术语。''isr":[11,10,12],则是0号分区的备份,我们不是在创建主题的时候创建了3个副本么。只有leader节点负责该分区的数据读写操作,其他的备份节点从leader节点拷贝数据,当leader节点挂掉的时候吗,备份节点中的第一个注册的节点变成leader节点,重新提供服务,保证数据的可靠性。
/brokers/topics/__consumer_offsets:
{"version":1,"partitions":{"45":[11,10,12],"34":[12,11,10],"12":[11,12,10],"8":[10,11,12],"19":[12,10,11],"23":[10,12,11],"4":[12,11,10],"40":[12,11,10],"15":[11,10,12],"11":[10,12,11],"9":[11,10,12],"44":[10,11,12],"33":[11,10,12],"22":[12,11,10],"26":[10,11,12],"37":[12,10,11],"13":[12,10,11],"46":[12,11,10],"24":[11,12,10],"35":[10,12,11],"16":[12,11,10],"5":[10,12,11],"10":[12,11,10],"48":[11,12,10],"21":[11,10,12],"43":[12,10,11],"32":[10,11,12],"49":[12,10,11],"6":[11,12,10],"36":[11,12,10],"1":[12,10,11],"39":[11,10,12],"17":[10,12,11],"25":[12,10,11],"14":[10,11,12],"47":[10,12,11],"31":[12,10,11],"42":[11,12,10],"0":[11,12,10],"20":[10,11,12],"27":[11,10,12],"2":[10,11,12],"38":[10,11,12],"18":[11,12,10],"30":[11,12,10],"7":[12,10,11],"29":[10,12,11],"41":[10,12,11],"3":[11,10,12],"28":[12,11,10]}}
记录了消费者的数据偏移量
/admin:[delete_topics]
记录了Kafka删除主题的信息,注意Kafka删除主题只是将表标记为删除,并没有真正的删除。
/consumers:记录了消费者的信息,包括当前消费者拥有的主题,主题下的分区

通过上述Kafka在zookeeper的一些注册信息,我们可以知道,Kafka集群在启动的时候主要在zookeeper上注册:Kafka集群地址,主题信息(包括分区),Consumer信息。那么生产者producer信息在哪里呢,注意:生产者producer并不是连接在zookeeper上,而是连接在Kafka集群。生产者producer通过查看zookeeper获得主题leader,然后生产者producer连接到leader的的主题上,发送消息,Kafka将这些消息保存下来,放到日志目录下(上一篇中我们配置的):
我们在s10下看一下这个目录,发现这个目录下存放着3个比较重要的目录,这就是我们创建的主题test的3个分区0,1,2,我们之前创建了3个分区,还有3个备份,那就在s11,s12下这个目录查看一下,发现,正好,3个备份,3个分区

我们随便进入一个分区看一下:

查看.log文件

发现了生产者发送的数据,注意不同的数据进入到了不同的分区下,.index下就是记录了这个分区下数据被读取的索引情况。
Kafka将生产者数据保存下来之后,消费者从zookeeper下获得主题下的分区信息,就能知道这个分区在哪个节点上面然后通过读取这个节点的数据目录(这里配置的是:/home/zpx/kafka/logs/test-X),然后通过数据,.index会记录数据读取的索引。
Kafka支持副本模式
---------------------
[同步复制](保证数据可靠性)
1.producer联系zk识别leader
2.向leader发送消息
3.leadr收到消息写入到本地log
4.follower从leader pull消息
5.follower向本地写入log
6.follower向leader发送ack消息
7.leader收到所有follower的ack消息
8.leader向producer回传ack
[异步副本]
和同步复制的区别在与leader写入本地log之后,
直接向client回传ack消息,不需要等待所有follower复制完成。
