今天主要学习了关于网页下载器的一些内容,下边做一下总结:
1.网页下载器,顾名思义,就是将URL所对应的网页以HTML的形式下载到本地,最终存储成本地文件或者还是本地内存字符串,然后进行后续的分析与处理;
网页下载器主要有:urllib2和requests
下边介绍下urllib下载网页的方法:

首先是引入urllib.request
然后打开我们所定义的url,最后打印出状态码(getcode的作用就获取状态码),如果状态码是200的话,就代表是正常的。运行之后的结果如下所示:

2.网页解析器:它是以下载好的html网页字符串作为输入,然后从中提取出有价值的数据以及新的URL。
其中常见的网页解析器有:正则表达式(这是一种模糊化思想,个人认为就跟搜索关键词一样)
html.parser
Beautiful Soup(比较强大且比较常用)
lxml
其中后三者主要适用于结构化解析,这里还涉及到一个词叫做DOM(Document Object Model)树,这个今天理解的不是很透彻,以后在慢慢谈。Beautiful Soup属于python的第三方库,主要是从html和xml中提取数据。
这里给大家举个例子:
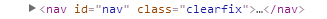
在这里,节点名称就是 nav,节点属性:id=“nav” class=“clearfix” ,节点内容:...
除此之外,今天还接触到了实例爬虫的过程:
第一步就是确定目标;第二步就是分析目标,这里边包括URL格式、数据格式以及网页编码;第三步就是编写代码了,最后执行爬虫。
今天白天帮老师干活,晚上身体有点不舒服,学的比较少,写的也比较范范,希望大家理解,如果有写的不对的,欢迎指出,大家共同学习,一起进步。