内容
Hibernate的二级缓存
Hibernate的查询缓存
内容回顾:
Hibernate的检索方式:
* 对象导航方式:
* Customer customer = ...;
* customer.getOrders();
* 根据OID进行检索:
* get();
* load();
* HQL:
* session.createQuery(“HQL”);
* 简单查询:
* from Customer;
* 排序查询:
* from Cusomer order by 属性;
* 条件查询:
* 位置绑定:
* from Customer where cname = ?;
* 名称绑定:
* from Customer where cname = :aaa;
* 分页查询:
* query.setFirstResult(0);
* query.setMaxResults(10);
* 聚集函数:
* select count(*) from Customer;
* 多态查询:
* 别名查询:
* 构造方法:
* 投影查询:
* 多表查询:
* 交叉连接:
* 内连接:
* 迫切内连接:
* 左外连接:
* 迫切左外连接:
* 命名查询:
* QBC:
* session.createCriteria(Class clazz);
* 简单查询:
* 排序查询:
* 条件查询:
* 分页查询:
* 离线条件查询:
* SQL:
* session.createSQLQuery(“SQL”);
* Hibnerate的抓取策略:
* 立即检索:
* 延迟检索:
* 在<class>设置lazy=”false”
* 在持久化类上设置final.(立即检索)
* 在调用方法的时候,初始化代理对象.
* 延迟的时候:
* 类级别延迟:
* <class>标签上lazy
*关联级别延迟:
* <set>/<many-to-one>/<one-to-one>
* fetch和lazy配置:
* <set>
* fetch:
* select :默认值:
* join :使用迫切左外连接的形式.
* subselect:使用子查询查询的关联对象.
* lazy:
* true :默认值
* false :不采用延迟.
* extra :及其懒惰.
* <many-to-one>
* fetch :
* select :默认值.
* join :使用迫切左外连接
* lazy :
* proxy :是否采用延迟看另一方<class>标签上配置的lazy是什么.
* false :不采用延迟
* no-proxy
* batch-size:批量抓取.
* Hibernate中事务与并发:
* 事务管理:
* 特性:
* 隔离级别:
* 丢失更新解决:
* Hibernate中事务并发管理:
* 设置隔离级别:
* 使用悲观锁和乐观锁解决丢失更新:
* 提供了本地线程绑定session:
* Hibernate的二级缓存:
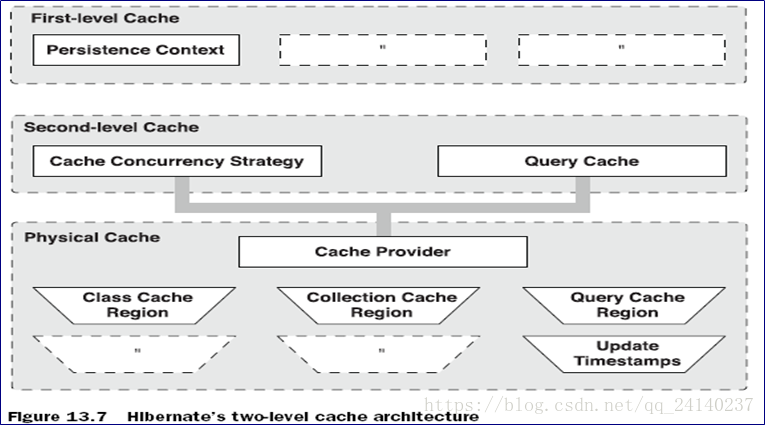
* 二级缓存:SessionFactory级别缓存.可以在多个session之间共享数据的.
* 二级缓存结构:
* 类缓存区,集合缓存区,更新时间戳,查询缓冲区.
* 二级缓存的适合放入的数据:
* 不经常修改的,允许偶尔出现并发问题.
* 二级缓存的配置:
* 在Hibernate中开启二级缓存.
* 配置二级缓存的提供商:
* EHCache
* 配置哪些类使用二级缓存:
* 在映射文件中配置.
* 在核心配置文件中配置(推荐).
1.2 Hibernate的二级缓存:
缓存(Cache):计算机领域非常通用的概念。它介于应用程序和永久性数据存储源(如硬盘上的文件或者数据库)之间,其作用是降低应用程序直接读写永久性数据存储源的频率,从而提高应用的运行性能。缓存中的数据是数据存储源中数据的拷贝。缓存的物理介质通常是内存
hibernate二级缓存的结构
二级缓存的并发访问策略
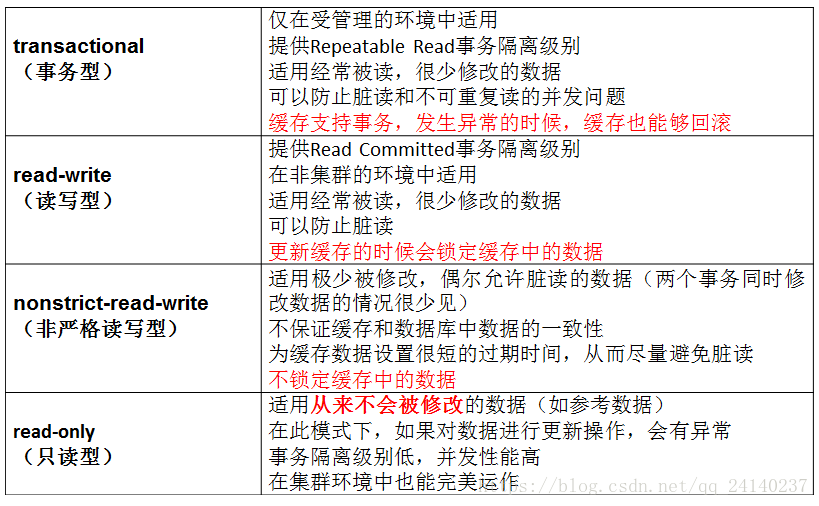
与其他应用数据共享的数据
缓存提供的供应商
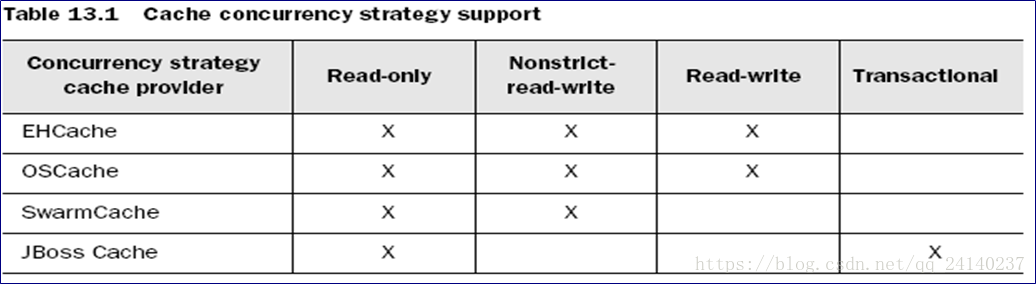
4 种缓存插件支持的并发访问策略(x 代表支持, 空白代表不支持)
配置进程范围内的二级缓存(配置ehcache缓存)
1 拷贝ehcache-1.5.0.jar到当前工程的lib目录下
依赖backport-util-concurrent 和 commons-logging
2 开启二级缓存
<property name="hibernate.cache.use_second_level_cache">true</property>
3 要指定缓存的供应商
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
4 指定使用二级缓存的类
* 方法一 在使用类的*.hbm.xml配置

*方法二 在hibernate.cfg.xml文件中配置(建议)
<!-- 指定使用二级缓存的类放在maping下面 -->
<!-- 配置类级别的二级缓存-->
<class-cache class="cn.itcast.c3p0.Customer" usage="read-write"/>
<class-cache class="cn.itcast.c3p0.Order" usage="read-write"/>
<!-- 配置集合级别的二级缓存-->
<collection-cache collection="cn.itcast.c3p0.Customer.orders" usage="read-write"/>
5 配置ehcache默认的配置文件ehcache.xml(名字固定)(放在类路径下)

一级缓存:缓存地址,下次在做get的时候,会从一级缓存中获取。第一条打出:true
二级缓存:缓存的是散装数据(每个数据拿出来放在二级缓存里),在获取的时候,因为一级生命周期结束,从二级缓存中获取,又会得到一个对象,把数据拿出来,重新组装成一个Customer对象,相当于Customer c2=…,所以第二条得到的是false。
1.2.1 类缓存区特点:
缓存的是对象的散装的数据.
1.2.2 集合缓存区的特点:
缓存的是对象的id.需要依赖类缓冲区的配置.

若没有配置类缓存区,就会往集合区缓存数据,就会缓存的都是对象(订单)的id,再去查询,从二级缓存获取数据,再次用订单,从集合中获取id,发送根据id去查询的sql语句。集合缓存区的使用需要依赖类缓存区。
配置类缓存,好处:可以直接从二级缓存区获取数据。
<!-- Hibernate中开启二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- 配置二级缓存的提供商 -->
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
<!-- 配置哪些类使用二级缓存 -->
<class-cache usage="read-write" class="cn.itcast.hibernate3.demo1.Customer"/>
<class-cache usage="read-write" class="cn.itcast.hibernate3.demo1.Order"/>
<!-- 集合缓冲区 -->
<collection-cache usage="read-write" collection="cn.itcast.hibernate3.demo1.Customer.orders"/>
测试类级别的二级缓存只适用于get和load获取数据,对query接口可以将数据放置到类级别的二级缓存中,但是不能使用query接口的 list方法从缓存中获取数据;query接口将查询的对象放置到二级缓存的查询缓存
<!-- 配置查询缓存 -->
<property name="hibernate.cache.use_query_cache">true</property>
一级缓存更新数据会同步到二级缓存
二级缓存的数据存放到临时目录

配置进程范围内的二级缓存(配置ehcache缓存)
使用name属性,cn.itcast.second.Order
如果此值为 0, 表示对象可以无限期地存在于缓存中 . 该属性值必须大于或等于 timeToIdleSeconds 属性值
ehcache.xml文件
<diskStore path="D:\cache" />
<cache name=""
maxElementsInMemory="10“
eternal=“true"
overflowToDisk="true“
maxElementsOnDisk=“10000000”
diskPersistent="false“
diskExpriyThreadIntervalSeconds=“120”/>
</ehcache>

list()方法会向二级缓存中放数据,但是不会使用二级缓存中的数据.(一级缓存效率高,二级缓存效率低)
iterate方法会发送N+1条SQL查询(效率较低).但是会使用二级缓存的数据(用二级缓存时效率较高)
iterator 先到数据库中检索符合条件的id,然后根据id分别到一级和二级缓冲中查找对象 (没有在查询数据库,每次只能查一个,可能导致n+1次查询 )
1.2.3 二级缓存数据到硬盘:
1.2.4 更新时间戳区域:
时间戳缓存区域
1.2.5 查询缓存:
<property name=“hibernate.cache.use_query_cache">true</property>
查询缓存可以缓存属性!!!!
比二级缓存功能更加强大,而且查询缓存必须依赖二级缓存.
二级缓存:对类/对象的缓存.
查询缓存:针对类中属性的缓存.
查询缓存的配置:
* 配置查询缓存:(二级缓存已经配置完毕.)
* 在核心配置文件中:
<!-- 配置查询缓存 -->
<property name="hibernate.cache.use_query_cache">true</property>
* 编写代码的时候:
@Test
// 查询缓存的测试
public void demo9(){
Session session = HibernateUtils.getCurrentSession();
Transaction tx = session.beginTransaction();
Query query = session.createQuery("select c.cname from Customer c");
/*
* 设置查询缓存
* * 如果查询缓存存在 直接返回
* * 如果查询缓存不存在 查询数据库 将查询结果放置到查询缓存中
*/
// 使用查询缓存:
query.setCacheable(true);//发送query.list();
tx.commit();
session = HibernateUtils.getCurrentSession();
tx = session.beginTransaction();
query = session.createQuery("select c.cname from Customer c");
query.setCacheable(true);//不发送aql
query.list();
tx.commit();
}
Myeclipse,可反向生成工程:新建一个项目,提供一个表,持久化类、映射文件和dao可以自动生成,但整合的时候有问题
1.3 Struts2和Hibernate的整合:
1.3.1 SH的整合
第一步:创建一个web项目:
第二步:导入jar包:
Struts2开发包:
Hibernate开发包:
* hibernate3.jar
* lib/jpa/*.jar
* lib/required/*.jar
* mysql驱动
* c3p0
引入配置文件:
* struts.xml
* hibernate.cfg.xml
* log4j.properties
第三步:创建包结构:
cn.itcast.vo
...
第四步:创建实体类与映射:
第五步:请求
customer_findAll.action