在实现整个mnist手写数字识别之前,我们先对整个识别过程推导一遍。
首先,假设我们已经拥有一个训练完成的模型,设样本为,其中向量的各元素均为mnist数据集每张28*28图片的灰度值,一共784个元素 。
现在,令样本X为第i类的特征的加权和为
其中,为样本X中第j个元素的值对样本X为第i类是的影响程度,也就是权值,
指如果在数据整体中,第i类较多,则
较大。
现在已经求得样本X为第i类时的特征的加权和,下一步就是将这些加权和计算softmax,也就是都计算一个exp函数,然后进行标准化(让所有类别输出的概率值和为1)。如下:
令为样本X是第i类的概率,则
网格图如下:
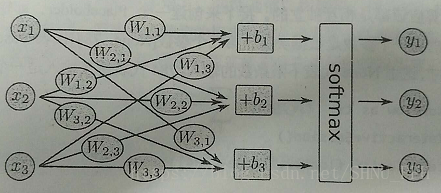
那么预测结果,
,...,
,也即
,所以我们只用通过学习求得权值矩阵和偏置矩阵B,以及利用一个softmax函数,即可完成对手写数字的识别。

代码如下:其中loss函数采用的cross-entropy,优化算法是随机梯度下降SDG,也即mini-batch gradient descent,mini-batch下降算法。其中loss函数用来评价模型的训练结果,优化算法主要可以加快算法向最优解方向收敛,同时在一定程度上避免陷入局部最优,当然不能完全避免。
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("C:/Users/PengFeihu/Desktop/mnist",one_hot=True)
print(mnist.train.images.shape,mnist.train.labels.shape)
print(mnist.test.images.shape,mnist.test.labels.shape)
print(mnist.validation.images.shape,mnist.validation.labels.shape)
import tensorflow as tf
sess = tf.InteractiveSession() #创建新的会话并将该会话设置成为默认会话
x = tf.placeholder(tf.float32, [None,784]) #设置输入样本大小,None表示不限样本数量,784表示每个样本包含784个灰度值
W=tf.Variable(tf.zeros([784,10]))
b=tf.Variable(tf.zeros([10])) #将权值矩阵和偏置矩阵初始设置为0
#接下来实现softmax regression算法,其中tensorflow中的softmax regression函数可以自动实现forward和backward
y=tf.nn.softmax(tf.matmul(x,W)+b)
#定义loss function,采用的是cross-entropy
y_ = tf.placeholder(tf.float32,[None,10])
cross_entropy=tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y),
reduction_indices=[1] ))
#优化器,步长0.5,loss function为cross_entropy
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
tf.global_variables_initializer().run()
#开始训练
for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
train_step.run({x:batch_xs, y_:batch_ys})在以上基础上,再加一层隐含层,通过多层神经网络(多层感知器MLP)实现mnist手写数字的识别。其中hidden层的激活函数选择ReLU,优化器使用adagrad,同时为了演示避免过拟合的方法,对隐含层节点输出进行了dropout处理。保留的节点比率为0.75。代码如下:
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("C:/Users/PengFeihu/Desktop/mnist",one_hot=True)
import tensorflow as tf
sess = tf.InteractiveSession()
in_units = 784 #输入节点数
h1_units = 300 #隐含层节点数
W1 = tf.Variable(tf.truncated_normal([in_units, h1_units], stddev = 0.1)) #用截断的正态分布初始化隐含层权值
b1 = tf.Variable(tf.zeros([h1_units])) #将偏置全都置0
W2 = tf.Variable(tf.zeros([h1_units, 10]))
b2 = tf.Variable(tf.zeros([10]))
x = tf.placeholder(tf.float32, [None, in_units])
keep_prob = tf.placeholder(tf.float32) #保留节点的比率
#定义隐含层输出和输出层输出
hidden1 = tf.nn.relu(tf.matmul(x,W1) + b1)
hidden1_drop = tf.nn.dropout(hidden1, keep_prob)
y = tf.nn.softmax(tf.matmul(hidden1_drop,W2)+b2)
#定义损失函数和优化器
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y),
reduction_indices = [1])) #loss函数依旧使用交叉信息熵cross_entropy
train_step = tf.train.AdagradOptimizer(0.3).minimize(cross_entropy) #优化算法使用了Adagrad,学习速率为0.3.之前使用的SGD
#开始训练,注意在训练中加入了keep_prob参数
tf.global_variables_initializer().run()
for i in range(3000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run({x: batch_xs, y_: batch_ys, keep_prob: 0.75}) #保留0.75的隐含层节点的输出
#对模型进行准确率评价
correct_prediction = tf.equal(tf.argmax(y, 1), tf.arg_max(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(accuracy.eval({x:mnist.test.images, y_:mnist.test.labels,
keep_prob: 1.0}))在代码最后有一个准确率评价,这个评价最后将会打印出模型预测的准确率。有一个疑问:accuracy.eval({x: mnist.test.images, y_:mnist.test.labels, keep_prob: 1.0})的作用是什么?是将测试集导入模型并返回和labels比对的准确率吗?