1、String、StringBuffer与StringBuilder之间区别
每次操作字符串,String会生成一个新的对象,而StringBuffer不会;StringBuilder是非线程安全的,StringBuffer是线程安全的
对于三者使用的总结:
如果要操作少量的数据用 = String
单线程操作字符串缓冲区 下操作大量数据 = StringBuilder
多线程操作字符串缓冲区 下操作大量数据 = StringBuffer
2、fail-fast
机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件
3、hashcode(),equal()方法深入解析
Java对于eqauls方法和hashCode方法是这样规定的:
1、如果两个对象相同,那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同(上面说的对象相同指的是用eqauls方法比较。)
Java语言对equals()的要求如下,这些要求是必须遵循的。
- 对称性:如果x.equals(y)返回是“true”,那么y.equals(x)也应该返回是“true”。
- 反射性:x.equals(x)必须返回是“true”。
- 类推性:如果x.equals(y)返回是“true”,而且y.equals(z)返回是“true”,那么z.equals(x)也应该返回是“true”。
- 一致性:如果x.equals(y)返回是“true”,只要x和y内容一直不变,不管你重复x.equals(y)多少次,返回都是“true”。
•任何情况下,x.equals(null),永远返回是“false”;x.equals(和x不同类型的对象)永远返回是“false”。
4、自动装箱拆箱
//自动装箱
Integer total = 99;
//自定拆箱
int totalprim = total;简单一点说,装箱就是自动将基本数据类型转换为包装器类型;拆箱就是自动将包装器类型转换为基本数据类型
详解Java的自动装箱与拆箱(Autoboxing and unboxing)
5、反射机制
6、如何写一个不可变类?
- 将类声明为final,所以它不能被继承
- 将所有的成员声明为私有的,这样就不允许直接访问这些成员
- 对变量不要提供setter方法
- 将所有可变的成员声明为final,这样只能对它们赋值一次
- 通过构造器初始化所有成员,进行深拷贝(deep copy)
- 在getter方法中,不要直接返回对象本身,而是克隆对象,并返回对象的拷贝
如何写一个不可变类
7、 多态
多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
多态的概念:同一操作作用于不同对象,可以有不同的解释,有不同的执行结果,这就是多态,简单来说就是:父类的引用指向子类对象
三个必要条件:继承、重写、向上转型。
继承:在多态中必须存在有继承关系的子类和父类。
重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的方法。
向上转型:在多态中需要将子类的引用赋给父类对象,只有这样该引用才能够具备技能调用父类的方法和子类的方法。
理解java的三大特性之多态
8、Override和Overload的含义以及区别
a.Overload顾名思义是重新加载,它可以表现类的多态性,可以是函数里面可以有相同的函数名但是参数名、返回值、类型不能相同;或者说可以改变参数、类型、返回值但是函数名字依然不变。
b.就是ride(重写)的意思,在子类继承父类的时候子类中可以定义某方法与其父类有相同的名称和参数,当子类在调用这一函数时自动调用子类的方法,而父类相当于被覆盖(重写)了。
9、Object有哪些公用方法?
- 方法equals测试的是两个对象是否相等
- 方法clone进行对象拷贝
- 方法getClass返回和当前对象相关的Class对象
- 方法notify,notifyall,wait都是用来对给定对象进行线程同步的
10、HashMap与HashTable的区别。
- HashMap是非线程安全的,HashTable是线程安全的。
- HashMap的键和值都允许有null值存在,而HashTable则不行。
- 因为线程安全的问题,HashMap效率比HashTable的要高。
11、TreeMap原理
- TreeMap是红黑树结构,红黑树是有序的,所以TreeMap也是有序的
- TreeMap的键不能为null
- TreeMap效率不如HashMap,Map需要有序的场合才使用TreeMap
12、2种办法让HashMap线程安全
- 通过Collections.synchronizedMap()返回一个新的Map,这个新的map就是线程安全的.
这个要求大家习惯基于接口编程,因为返回的并不是HashMap,而是一个Map的实现. - 重改写了HashMap,具体的可以查看java.util.concurrent.ConcurrentHashMap. 这个方法比方法一有了很大的改进.
13、ConcurrentHashMap
- ConcurrentHashMap的应用场景是高并发,但是并不能保证线程安全,而同步的HashMap和HashMap的是锁住整个容器,而加锁之后ConcurrentHashMap不需要锁住整个容器,只需要锁住对应的Segment就好了,所以可以保证高并发同步访问,提升了效率。
- 可以多线程写。
- ConcurrentHashMap把HashMap分成若干个Segmenet
1.get时,不加锁,先定位到segment然后在找到头结点进行读取操作。而value是volatile变量,所以可以保证在竞争条件时保证读取最新的值,如果读到的value是null,则可能正在修改,那么就调用ReadValueUnderLock函数,加锁保证读到的数据是正确的。
2.Put时会加锁,一律添加到hash链的头部。
3.Remove时也会加锁,由于next是final类型不可改变,所以必须把删除的节点之前的节点都复制一遍。
4.ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。它使用了多个锁来控制对Hash表的不同Segment进行的修改。 - 在jdk1.8中主要做了2方面的改进
改进一:取消segments字段,直接采用transient volatile HashEntry
14、HashMap,ConcurrentHashMap与LinkedHashMap的区别
- ConcurrentHashMap是使用了锁分段技术技术来保证线程安全的,锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问
- ConcurrentHashMap 是在每个段(segment)中线程安全的
- LinkedHashMap维护一个双链表,可以将里面的数据按写入的顺序读出
15、Vector和ArrayList的区别
- ArrayList在内存不够时默认是扩展50% + 1个,Vector是默认扩展1倍。
- Vector提供indexOf(obj, start)接口,ArrayList没有。
- Vector属于线程安全级别的,但是大多数情况下不使用Vector,因为线程安全需要更大的系统开销。
16、LinkedHashMap 实现LRU
public class LRULinkedHashMap <K,V> extends LinkedHashMap<K,V> {
//定义缓存的容量
private int capacity;
private static final long serialVersionUID = 1L;
//带参数的构造器
LRULinkedHashMap(int capacity){
//调用LinkedHashMap的构造器,传入以下参数
super(16,0.75f,true);
//传入指定的缓存最大容量
this.capacity=capacity;
}
//实现LRU的关键方法,如果map里面的元素个数大于了缓存最大容量,则删除链表的顶端元素
@Override
public boolean removeEldestEntry(Map.Entry<K, V> eldest){
System.out.println(eldest.getKey() + "=" + eldest.getValue());
return size()>capacity;
}
}17、LinkedHashMap
1)Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。
(2)注意,如果在映射中重新插入 键,则插入顺序不受影响。(如果在调用 m.put(k, v) 前 m.containsKey(k) 返回了 true,则调用时会将键 k 重新插入到映射 m 中。)
(3)此实现可以让客户避免未指定的、由 HashMap(及 Hashtable)所提供的通常为杂乱无章的排序工作,同时无需增加与 TreeMap 相关的成本。使用它可以生成一个与原来顺序相同的映射副本,而与原映射的实现无关:
(4) 提供特殊的构造方法来创建链接哈希映射,该哈希映射的迭代顺序就是最后访问其条目的顺序,从近期访问最少到近期访问最多的顺序(访问顺序)。这种映射很适合构建 LRU 缓存。调用 put 或 get 方法将会访问相应的条目(假定调用完成后它还存在)。putAll 方法以指定映射的条目集迭代器提供的键-值映射关系的顺序,为指定映射的每个映射关系生成一个条目访问。任何其他方法均不生成条目访问。特别是,collection 视图上的操作不 影响底层映射的迭代顺序。 removeEldestEntry(Map.Entry)
18、Java的四种引用,强弱软虚,以及用到的场景
- 强引用:强引用有引用变量指向时永远不会被垃圾回收,JVM宁愿抛出OutOfMemory错误也不会回收这种对象。
- 软引用(SoftReference):如果一个对象具有软引用,内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。
- 弱引用(WeakReference):弱引用也是用来描述非必需对象的,当JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。在java中,用java.lang.ref.WeakReference类来表示。
- 虚引用和前面的软引用、弱引用不同,它并不影响对象的生命周期。在java中用java.lang.ref.PhantomReference类表示。如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。
Java的四种引用,强弱软虚,用到的场景
19、java 异常体系
Throwable
|-Error
|-Exception
|-RuntimeException
Thorwable类(表示可抛出)是所有异常和错误的超类,两个直接子类为Error和Exception,分别表示错误和异常。其中异常类Exception又分为运行时异常(RuntimeException)和非运行时异常, 这两种异常有很大的区别,也称之为不检查异常(Unchecked Exception)和检查异常(Checked Exception)。下面将详细讲述这些异常之间的区别与联系:
1、Error与Exception
Error是程序无法处理的错误,它是由JVM产生和抛出的,比如OutOfMemoryError、ThreadDeath等。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
Exception是程序本身可以处理的异常,这种异常分两大类运行时异常和非运行时异常。程序中应当尽可能去处理这些异常。
2、运行时异常和非运行时异常
运行时异常都是RuntimeException类及其子类异常,如NullPointerException、IndexOutOfBoundsException等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
非运行时异常是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
3.异常链化:以一个异常对象为参数构造新的异常对象。新的异对象将包含先前异常的信息。这项技术主要是异常类的一个带Throwable参数的函数来实现的。这个当做参数的异常,我们叫他根源异常(cause)
public class Throwable implements Serializable {
private Throwable cause = this;
public Throwable(String message, Throwable cause) {
fillInStackTrace();
detailMessage = message;
this.cause = cause;
}
public Throwable(Throwable cause) {
fillInStackTrace();
detailMessage = (cause==null ? null : cause.toString());
this.cause = cause;
}
//........
}21、Java中关键字throw和throws的区别
1、throws出现在方法函数头;而throw出现在函数体。
2、throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常对象。
3、两者都是消极处理异常的方式(这里的消极并不是说这种方式不好),只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
Java中关键字throw和throws的区别
22、泛型:super,extends
23、传统的IO和NIO的区别其本质就是阻塞和非阻塞的区别
阻塞概念:应用程序在获取网络数据的时候,如果网络传输很慢,那么程序就会一直处于等待状态,直到数据传输结束为止。
非阻塞概念:应用程序直接可以获取已经准备好的网络数据,无需等待。
io为同步阻塞的形式nio为同步非阻塞的形式。NIO1.0并没有实现异步的概念,在jdk1.7之后的NIO2.0才真正的实现了异步非阻塞的概念。
同步时:应用程序会直接参与IO读写操作,并且我们的程序会直接阻塞到某一个方法上,直到数据准备就绪。或者采用轮询的策略实时检查数据的就绪状态,如果就绪则获取数据。
异步时:就是所用IO操作交给操作系统处理,我们编写的应用程序不参与IO的操作,我们的程序不需要关心IO的读写,当操作系统完成了IO的读写操作时,会给我们的应用程序发送通知,我们的应用程序直接拿走数据即可。
24、AIO编程
AIO的特点:
1. 读完了再通知我
2. 不会加快IO,只是在读完后进行通知
3. 使用回调函数,进行业务处理
在理解了NIO的基础上,看AIO,区别在于AIO是等读写过程完成后再去调用回调函数。
NIO是同步非阻塞的
AIO是异步非阻塞的
由于NIO的读写过程依然在应用线程里完成,所以对于那些读写过程时间长的,NIO就不太适合。
而AIO的读写过程完成后才被通知,所以AIO能够胜任那些重量级,读写过程长的任务。
25、java nio
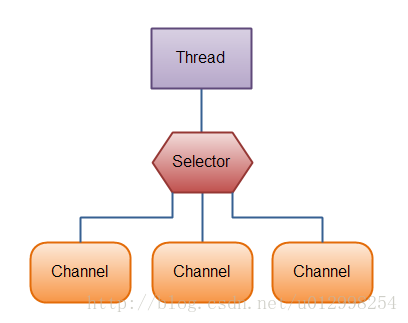
- Channel,Buffer 和 Selector(多路复用器) 构成了核心的API。其它组件,如Pipe和FileLock
- Channel:FileChannel,DatagramChannel,SocketChannel,ServerSocketChanne
- Buffer:ByteBuffer,CharBuffer,DoubleBuffer,FloatBuffer,IntBuffer,LongBuffer,ShortBuffer
- 数据可以从Channel读到Buffer中,也可以从Buffer 写到Channel中
- Selector允许单线程处理多个 Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,
26、字符流和字节流
- Java中的字节流处理的最基本单位为单个字节,它通常用来处理二进制数据。两个字节流类是InputStream和OutputStream,它们分别代表了组基本的输入字节流和输出字节流。
- 字符流:Java中的字符流处理的最基本的单元是Unicode码元(大小2字节),它通常用来处理文本数据。
- 字符流与字节流的区别
a,字节流操作的基本单元为字节;字符流操作的基本单元为Unicode码元。
b,字节流默认不使用缓冲区;字符流使用缓冲区。
c,字节流通常用于处理二进制数据,实际上它可以处理任意类型的数据,但它不支持直接写入或读取Unicode码元;字符流通常处理文本数据,它支持写入及读取Unicode码元。