散列又称词典(dictionary),在讨论这部分内容时我们将看到散列实际上并不是一种简单的技术,从某种意义上讲它甚至是一种思想,是一种赖以高效组织数据,并实现相关算法的重要思想。接下来我们就会看到,在这种思想背后的原理,是如此的直观和简单。毕竟,任何表面复杂的技术背后的原理都是十分简洁而优美的。
要先对散列有一个概观:被称为散列(hashing)的技术实际上是散列表结构的实现,是一种用于以O(1)时间插入、删除和查找的技术。由于它是根据某种具体规则散步的,就像集束炸弹落地,对!我觉得这是最贴切的一个比喻了,把某一个实体散列到存储空间里,过程恰似集束炸弹落地前的子炸弹分解hhhhhh。
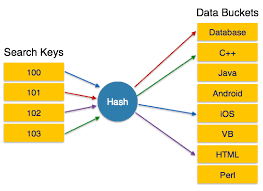

由于它并没有一个线性顺序,所以那些需要元素间任何排序信息的操作就不能进行了,比如FindMin,FindMax,还有按顺序打印整个表都是散列所不支持的。
下面来探究为什么要引入散列这种技术,现有的一些结构不够用么?我们的故事要从服务电话说起,当你需要获得某个公司或者部门的服务应该如何通过电话来找到他们呢?查电话簿,但有时候电话簿太厚以至于你没有足够的耐心去查阅,在智能手机兴起之前,大部分公司有相当多的客户都是因为这种纠结而流失掉的,而优秀的公司应该为它的服务取一个更加便于记忆的电话号码,与此同时还要突出公司特点,这就不能是简单的123456,8888888能做到的了,而且这样太掉档次。。。

来看看经典的做法,对于IBM来说,他的电话是这样的
在此之前,对于每一个键大部分人只留意了其中的数字部分,而实际上当时大部分的键盘都是这种形式

其中的每个键上 除了有一个数字,同时还拥有若干个英文字母。我们可以理解为:一个键既可能对应于一个数字,也可能同时对应于若干个字母。比如这里的IBM-4YOU对应的拨号过程就是426-968。请留意体会这种方式的巧妙之处,不仅记住了一个公司的特点,而且拨打的电话依然是由数字组成,这背后蕴含着某种深刻的思想。实际上这就是散列的一个应用:按下字母,实际效果指向各自对应的数字。所以我们可以想象得到,哈希的具体做法或许是给定一个关键字,然后返回一个对应的索引。当然也可能引发冲突,多个关键字映射到同一个索引上,比如这里的A,B,C都hashing到了2这个索引,这也是后续我们解决散列问题的一个关键点。
我们不妨就访问数据的方式来做一对比,对于不同的数据结构,在此之前都根据其如何访问数据,进行过分类,有寻秩访问call by rank,比如向量;还有寻位置访问call by position,这方面的典型例子是列表list;而以BST为典型代表的这类数据结构呢,都属于寻关键码访问call by key,树根是0,左孩子1,右孩子2,往下依次类推这样。反观我们这里对电话号码的访问,如果说访问的对象是公司的服务,那么刚才这种获取服务的方式,又属于其中的哪种呢?首先这种方式既不是寻秩,也不是寻位置访问——所有的公司的各项服务之间并不存在某种线性次序。那么它是寻关键码访问吗?
要说明一点:这里的“关键码”指的是那串电话号码,下面提到的“值”指的是某个字母本身,可能有人会误解,之前就有人问我:号码不才应该是“值”么?你看都是数值。但实际上在这个案例中,某个字母对应的哪个数字,只是它的一个索引,我们在脑海中的思维活动,关注点还在字母本身,电话号只是键盘处理过的结果。就像二叉树里,树根编号是0,但它结构里面有个具体的数,那是值,那是他这个对象本身,而0仅仅是记录位置的一个关键码。
这里的确有关键码,也就是每个服务所对应的那个电话号码。然而即便是按照刚才的方式去拨打某个特定的电话,在你的脑海里除了那个公司和服务的助记符号之外,完全不出现任何形式的数字电话号码,在整个过程中我们都是想着那串单词去拨打的,因此我们关注的是具体的字母,也就是你所需要找到的那个对象本身。我们称之为value 数值,因此将新的这种访问方式称作寻值访问。我们刚才已经领略到了这种新的访问方式的威力,若能加以充分利用,这种访问方式将使我们的计算效率进一步得以提高,而这样的一种典型的技巧就是所谓的Hashing。中文可以根据含义译作杂凑;也可以根据发音译作哈希,但是我们要信达雅!所以译作散列哈哈哈哈哈