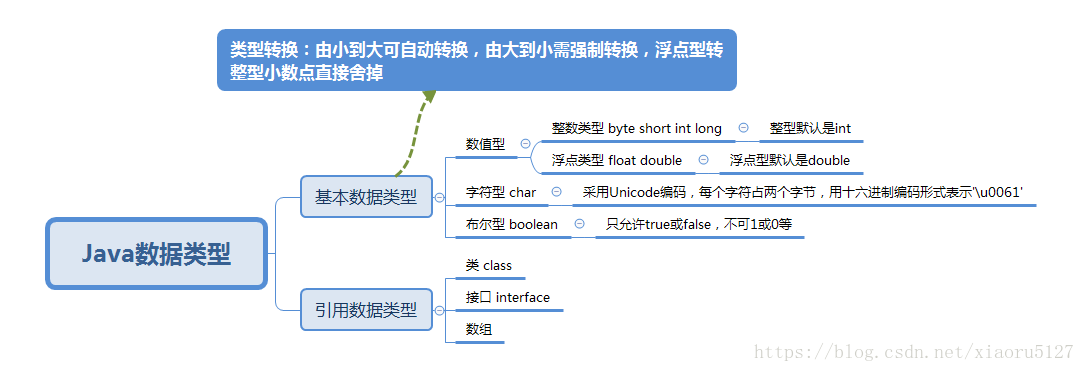
基本类型

精度丢失和溢出:
精度丢失一般发生在浮点型存储数值或类型强制转换的时候。我们知道计算机存储数值实际存储的是二进制,举个粟子
double r1 = 1 - 0.99;
double r2 = 2 - 0.99 result的值是0.010000000000000009,r2的值为1.01,因为0.99转换成二进制的时候就已经精度丢失了。小数二进制和十进制的转换方法,类似于十进制无法表达1/3一样。所以进行计算后有可能计算出来的数值不正确(是否正确主要看二者进行二进制的运算后再转换回十进制是否正确了)
溢出一般发生在赋值超出了目标类型所能表达的范围
如byte表达范围在【-128~127】之间,如果赋值130的话则
//130的二进制
0000 0000 0000 0000 0000 0000 1000 0010
//强制类型转换后
1000 0010
//第一位为1的为负数,负数用补码表示,所以要显示原码,要取反加1,即
0111 1110
//转换成十进制,加上符号位就是-126PS:精度损失在计算中的解决方法,使用String来保存数值,计算时使用BigDecimal来进行计算。
转换问题:
1. 类型由小到大自动转换,由大到小需强制转换,小数部分直接舍掉。
//需强制转换且a的值为10
int a = (int)10.8- 整型字面常量的大小超出目标类型所能表示范围也需要强转,溢出
//需强制转换,b1为-128,b2为-127
byte b1 = (byte)128;
byte b2 = (byte)129;- 复合运算符(+=、-=、*=、/=、%=)是可以将右边表达式的类型自动强制转换成左边的类型
int a = 8;
short s = 5;
s += a;
s += a+5; - char是无符号类型,其他类型转换成char都需要显式强制转换,赋值负数也需要强制转换
PS:Java中类属性变量会默认赋初始值,局部变量则需要手动初始化,引用数据类型不管在哪都会被赋予初始值null,String类型的初始值也是null
数据结构概述
基本组成
数组:
优点:内存空间连续,查询快,相对其他结构消耗内存空间小
缺点:初始化时就需要分配数组(内存)大小,不支持动态扩充,插入和删除慢
一维数组是在内存连续分配的一段存储空间,多维则如下
数组声明后会便会在连续内存空间中进行内存分配,并赋初始值

//此时,int[1] = 0
int[] array = new int[3];- 链表:内存空间不连续,插入删除快,查询慢
单向链表,双向链表,循环单向链表,循环双向链表
一种双向链表的实现
public class DoublePointLinkedList {
private Node head;//头节点
private Node tail;//尾节点
private int size;//节点的个数
private class Node{
private Object data;
private Node next;
public Node(Object data){
this.data = data;
}
}
public DoublePointLinkedList(){
size = 0;
head = null;
tail = null;
}
//链表头新增节点
public void addHead(Object data){
Node node = new Node(data);
if(size == 0){//如果链表为空,那么头节点和尾节点都是该新增节点
head = node;
tail = node;
size++;
}else{
node.next = head;
head = node;
size++;
}
}
//链表尾新增节点
public void addTail(Object data){
Node node = new Node(data);
if(size == 0){//如果链表为空,那么头节点和尾节点都是该新增节点
head = node;
tail = node;
size++;
}else{
tail.next = node;
tail = node;
size++;
}
}
//删除头部节点,成功返回true,失败返回false
public boolean deleteHead(){
if(size == 0){//当前链表节点数为0
return false;
}
if(head.next == null){//当前链表节点数为1
head = null;
tail = null;
}else{
head = head.next;
}
size--;
return true;
}
//判断是否为空
public boolean isEmpty(){
return (size ==0);
}
//获得链表的节点个数
public int getSize(){
return size;
}
}PS:空的双向循环链表如下

- 栈:后进先出,栈顶可操作,栈底不可操作,不允许对栈中指定位置做增删操作。底层数组
一种简单的实现
public class SqStack<T> {
private T data[];//用数组表示栈元素
private int maxSize;//栈空间大小(常量)
private int top;//栈顶指针(指向栈顶元素)
@SuppressWarnings("unchecked")
public SqStack(int maxSize){
this.maxSize = maxSize;
this.data = (T[]) new Object[maxSize];//泛型数组不能直接new创建,需要使用Object来创建(其实一开始也可以直接使用Object来代替泛型)
this.top = -1;//有的书中使用0,但这样会占用一个内存
}
//判断栈是否为空
public boolean isNull(){
boolean flag = this.top<=-1?true:false;
return flag;
}
//判断是否栈满
public boolean isFull(){
boolean flag = this.top==this.maxSize-1?true:false;
return flag;
}
//压栈
public boolean push(T vaule){
if(isFull()){
//栈满
return false;
}else{
data[++top] = vaule;//栈顶指针加1并赋值
return true;
}
}
//弹栈
public T pop(){
if(isNull()){
//栈为空
return null;
}else{
T value = data[top];//取出栈顶元素
--top;//栈顶指针-1
return value;
}
}
}- 队列:先进先出。底层数组
一种简单的实现
public class SqQueue<T>{
private T[] datas;//使用数组作为队列的容器
private int maxSize;//队列的容量
private int front;//头指针
private int rear;//尾指针
//初始化队列
public SqQueue(int maxSize){
if(maxSize<1){
maxSize = 1;
}
this.maxSize = maxSize;
this.front = 0;
this.rear = 0;
this.datas = (T[])new Object[this.maxSize];
}
//两个状态:队空&队满
public boolean isNull(){
if(this.front == this.rear)
return true;
else
return false;
}
public boolean isFull(){
if((rear+1)%this.maxSize==front)
return true;
else
return false;
}
//初始化队列
public void initQueue(){
this.front = 0;
this.front = 0;
}
//两个操作:进队&出队
public boolean push(T data){
if(isFull())
return false;//队满则无法进队
else{
datas[rear] = data;//进队
rear = (rear+1) % maxSize;//队尾指针+1.
return true;
}
}
public T pop(){
if(isNull())
return null;//对空无法出队
else{
T popData = datas[front++];//出队
front = (front+1) % maxSize;//队头指针+1
return popData;
}
}
//get()
public T[] getDatas() {
return datas;
}
public int getMaxSize() {
return maxSize;
}
public int getFront() {
return front;
}
public int getRear() {
return rear;
}
}- 二叉树(ps:还有一个红黑树,2-3-4树)
class Node {
int value;
Node leftChild;
Node rightChild;
Node(int value) {
this.value = value;
}
public void display() {
System.out.print(this.value + "\t");
}
@Override
public String toString() {
// TODO Auto-generated method stub
return String.valueOf(value);
}
}
class BinaryTree {
private Node root = null;
BinaryTree(int value) {
root = new Node(value);
root.leftChild = null;
root.rightChild = null;
}
public Node findKey(int value) {} //查找
public String insert(int value) {} //插入
public void inOrderTraverse() {} //中序遍历递归操作
public void inOrderByStack() {} //中序遍历非递归操作
public void preOrderTraverse() {} //前序遍历
public void preOrderByStack() {} //前序遍历非递归操作
public void postOrderTraverse() {} //后序遍历
public void postOrderByStack() {} //后序遍历非递归操作
public int getMinValue() {} //得到最小(大)值
public boolean delete(int value) {} //删除
}
堆(底层是完全二叉树,可以实现优先级队列。ps:此堆是一种特殊的二叉树与堆内存不是一个概念)
- 优先级队列(底层二叉树):最大优先队列(取出的是权值最大的元素)、最小优先队列(取出的是权值最小的元素)
Hash表:Hash值相同的对象不一定相同,但是相同的对象Hash值一定相同。线程不安全。
Hash地址的构建
- 直接取址法:取k 或k 的某个线性函数为Hash地址,这样取的值都不一样,但所需容量庞大
- 数字分析法:知晓k的数字规律,取产生冲突概率小的的值作为Hash地址
- 平方取中法:取k值平方数,取该平方数的中间几位,较常用
- 折叠法:分割k值,做叠加之类的处理
- 随机数法
PS:Hash函数的构造算法可能导致Hash地址的两个极限,Hash地址都一样则链表非常长,查询性能下降;Hash地址都不一样则HashMap(内部通过数组保存数据)可能会经过多次扩容,容量大增。
JDK Hash冲突的解决办法:JDK1.8之前采用链地址法(即用链表来保存下一个元素);JDK1.8增加了一个策略,使用常量TREEIFY_THRESHOLD(冲突的元素个数超过该常量)来控制是否切换到平衡树来存储
- 图(ps:还有带权图)
常见集合
java集合框架大致可以分为以下几个部分:List列表、Set集合、Map映射、迭代器(Iterator、Enumeration)、工具类(Arrays、Collections;Arrays和Collections是用来操作数组、集合的两个工具类)。

List特点:有序,元素都有索引,允许重复
ArrayList:底层是数组(动态数组,新增时数组不够会动态扩容),线程不同步
通过下标索引直接查找到指定位置的元素,因此查找、修改效率高,但每次插入或删除元素,就要大量地移动元素,因此插入删除元素的效率低。
LinkedList:底层是链表(其实就是一个双向循环链表),线程不同步,增删快,查询效率低
Queue:队列,先进先出,底层单向链表或数组
Stack:栈,后进先出, 底层单向链表或数组
操作有:建栈(建立空栈)、入栈、出栈、取栈顶元素
Set特点:只能通过迭代器Iterator取出
HashSet:底层是哈希表,线程不安全,无序,高效,元素唯一
- LinkedHashSet:有序
TreeSet:底层是二叉树,有序,线程不安全
Map特点:Map一次存一对元素
Hashtable:底层是哈希表,线程安全(synchronized),键和值均不可为null
HashMap:底层是数组+链表(key-value保存在一个Entry中,Entry为单向链表结构,通过key算出hash值,hash值即数组下标可得Entry,如果Entry这个链表不止一个则遍历这个链表),使用哈希算法,线程不安全,键值可为null;多线程可使用ConcurrentHashMap 线程安全的
性能影响因素:初始容量(即HashMap数组的初始化容量大小)和加载因子(用以判断HashMap是否扩容,当前数组大小 >= 当前容量*加载因子)。加载因子默认0.75,过大则冲突增加,链表加长,查询效率降低;过小则空间浪费
PS:Hash地址的产生用位运算,这样效率较高
TreeMap:底层是二叉树,可排序
Android集合
ArrayMap:替代HashMap,使用Hash算法,底层是两个数组,mHash数组保存每个key的Hash值,mArray数组用连续的两个元素保存key-value。利用key的hash值计算其所在数组的下标index,如存在冲突则index往下移。key 不为null。
性能方面,查找使用二分法,增删时会对数据进行重新整理,清除数据后会自动收缩数据,释放空间。以时间换空间,消耗小,但效率没HashMap高
SparseArray:替代HashMap,SparseArray并不是用Hash算法来做的,底层采用两个数组来存储key-value,适用于数据量在千级以下。
性能方面,
key只能是int类型,避免了自动装箱
内部对数据还采取了压缩的方式来表示稀疏数组的数据
在存储和读取数据时候,使用的是二分查找法
遍历与排序
List和Map都可以用add/get来存储数据或者Iterator;Set只能用Iterator
List可以用Collections.sort来排序:
List E中有默认实现的compareTo,也可重写,调用Collections.sort(List list)即可排序;如果想重写定义排序规则也可以用Collections.sort(List list,Comparator c)
//按照价格排序
Collections.sort(list, new Comparator<Object>() {
@Override
public int compare(Object o1, Object o2) {
Book book1 = (Book)o1;
Book book2 = (Book)o3;
return book1.price.compareTo(book2.price);
}
});Set和Map是无序的,部分底层是二叉树实现的可以是有序的,内部已经实现自动排序了。