从1970年关系数据库理论被提出,到2006云计算概念的诞生,半个世纪以来IT行业的科技革新不断引领着时代潮流。作为IT技术的核心领域之一,数据库如何在云计算的大时代背景下持续进化,开拓创新。
10月12日的云栖大会·阿里云自研数据库POLARDB专场,阿里云研究员余锋带来了《展望云计算新时代数据库计算力的进化》主题分享,探讨了阿里云数据库团队自研数据库POLARDB的设计理念,并一起展望了新一代云数据库的未来。
云数据库的进化
数据库是计算,是存储,也涉及网络和内存,但它们都是非常密集的基础软件。事实上,过去大家所接触的诸如中间件、转化器之类的都在做流量,而数据库是真正的知识密集型事务。一个数据库的好坏,取决于它是否是一个能把计算能力、存储能力、网络能力还有内存能力发挥到极致的综合软件。因此,POLARDB所有的进化和发展都是围绕的这三方面。

全世界范围内的流行数据库有几百种,但它们都是计算、存储、网络这三个基础东西的综合体,每当计算的硬件、存储或是网络发生变化时都是数据库变革的契机,每一个变化也都蕴含着各种各样的机会。
现在,在阿里云或者在其它云厂家都可以很方便地拿到一台内存T级别的固定机,这也体现了内存方面极为恐怖的增长速度。网络也是如此,RDMA网络就已经发生了非常大的变化,虽然对于个人来说因为成本考量一般是不会购买使用的,但是IT公司就会去拥抱这些东西,这是硬件上的变化。然后从计算的角度,多核CPU、128核已经十分普及。现在还有很多基于GPU的数据库,阿里云POLARDB在这一块也有研究和探索。存储同样也是,比如SSD和英特尔研发的Ethernet。内存也不例外,今天一台机器就会有几T的内存,太为普遍。网络上的InfiniBand虽然还是很高端,但相信未来大家一定能够很方便地获取使用。
硬件的变化必然会伴随着软件的变化。不同于数据库服务,数据库更像是汽车上的引擎,而数据库服务就需要提供一辆整车,还要提供4S和整个生态服务。整个DB引擎在云数据库环境里其实是很小的一部分,需要像Docker隔离,所以如果隔离技术应用不够,随之带来的使用体验就会非常差。比如“双11”,过去一个包从客户机器到达DB后端可能需要百八十微秒,现在则只需要三十微秒左右,能够使得整个云服务更有竞争力、使用更便捷,在各个环节追求极致。围绕计算、存储和网络,POLARDB也在致力于成就极致的体验。
新一代云数据库POLARDB
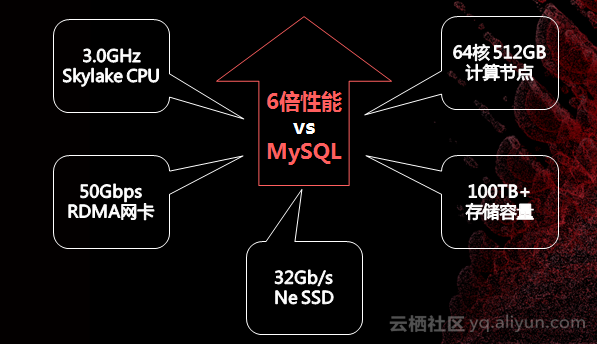
对比MySQL,POLARDB拥有了6倍的性能提升——这是它最核心的一点,目前也已经开放测试。那么6倍的性能提升是如何实现的呢?有几样东西是共见的:第一,最新的硬件;第二,从头构建的存储、引擎。POLARDB百分百兼容MySQL,这也就是意味着原来怎么做,现在同样遵守,区别只是更大更好更便宜,关键在于它使用了高CPU、网络网卡、RDMA和规格,能够解决最重要的痛点。过去的MySQL单机2到3TB,实际上的POLARDB却有高达100TB的盘。
我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。
当发生灾难时数据通常无法快速转移,所以就会带来一个疑惑:为什么需要去做POLARDB?事实上POLARDB的研究已经历经了两三年,客户产品使用中所遇到的很多问题和困难在现有的方案和架构上并不能很好地解决,但是POLARDB却能够完美地满足客户最大诉求。
虽然看起来,似乎只要有好的硬件均可以满足这一要求,然而其实并没有那么简单。最早的MySQL标准都是一主一从结构,所以SQL写入时的数据流基本是单向流进,会有八个数据流流动。数据流动一多,也就意味着IO消耗会过大,延迟变大。除去这个原生模式外,RDS和AWS采取的做法都是将官方版本放于云上,提供存储以及更好的弹性。POLARDB则是为云而生,其所有的弹性、隔离、IO存储均是针对云的特点所设计的。
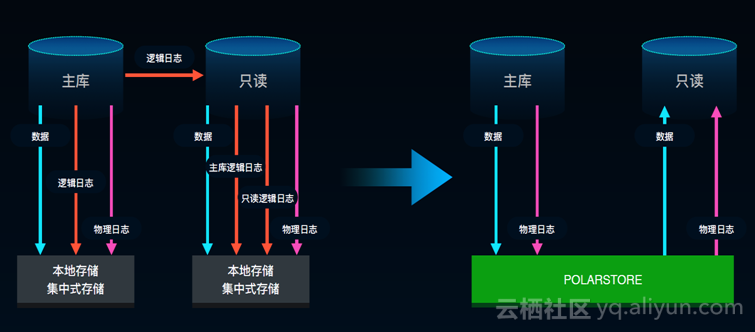
在系统的演进中,团队对整体业务有了很深的了解,今天的数据流已经是极大简化后的版本。如上图所示,左边是单向的,右边则是双向数据流,比如准备发生同步时数据会主动推给中间节点,所以这对于技术要求会很高。此外,过去是集中式存储,数据同步中的Copy成本很高,并且会造成很多不可见的问题。在MySQL的使用上,过去因为一些数据不可用所以很少有人会把它用于关键场合,而POLARDB的设计具有金融级别的可靠性,能在硬件基础上把很多事情简化做好,让它更可靠、更简单。
如果有一个好的数据库却不知道如何使用,或者说配套不完整,这些都是空谈。POLARDB所提供的数据库服务则具有完整的生命周期,从上云端到扩容、缩容全覆盖。淘宝“双11”让团队明确了互联网高可用的使用,因此对于容灾、扩容、弹性、存版都了解得非常清楚,所以在设计POLARDB时即针对这些场景,后续又逐渐叠加了金融、政企等场景。
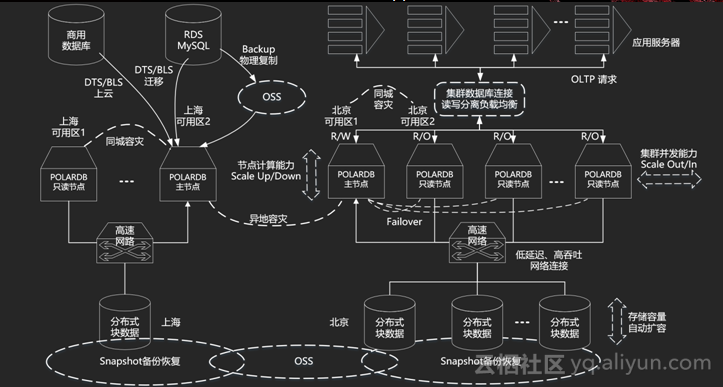
在设计之初,POLARDB的计算和存储就是分离的,如上所示的图中可以看到非常明显的三层:首先是用户应用层,然后是计算层,最后是存储层。过去的计算存储不分离,就会导致在节点恢复时需要数据秒搬,但一般很少有系统可以做到这一点,比如几个T的数据需要搬一至两天,不可能突破物理极限。在计算、存储完全分离后系统还设置了一个中间件,读写分离的情况它的写能力是非常强的,中间件也会帮助做读写能力和自动识别读写能力,同时成本也很低。
系统设计需要非常可靠数据,这是数据库最核心的东西也是底线。通过计算以后,存储分离的情况下数据都在后端,就形成了一个标准的分布式数据库,可以在生命周期里扩容、缩容、读写分离以及容灾。但是下面还需要考虑服务迁移的问题,可以用商业数据库或MySQL解决:诸如DTS、BS的商业数据库能够用逻辑复制拉取过来;MySQL则可以用物理设置。POLARDB能够实现节点同步,即逻辑复制就是一条复制一次,物理复制就是一批拿过去,效果会更高。
数据如果通过物理复制以及OSS的方式中转上来,速度会非常之快。根据银行要求,未来的运营数据需要保留较长时间,所以可以把数据导入到OSS上等需要的时候再导出。RDS是一个完整的体系,能够百分之百兼容所有生态,也希望POLARDB能和生态一起演化。
国际化、智能化、持续创新
PPOLARDB最重要一点是它的数据库可以和国际接轨。有一些国内外的合规要求不太一样,比如之前新加坡邮政所做的项目对合规要求就非常高,但这些东西属于输出的核心功能,RDS里就有的,所以系统能够很容易地继承过来并做得更好。未来,相信POLARDB会朝着信息化、互联网化、国际化、智能化、创新化的方向不断进化。