工作中遇到一则很奇怪的真实案例,有一个统计sql,统计结果在190-200之间时,耗时基本上维持在1.6S,统计结果在此数据范围外的统计耗时,基本上维持在0.1-0.3S之间,
按照惯例,explain查看执行计划。
为方便阐述,约定如下 :
数据范围在190-200,耗时1.6S的叫 sql1,数据范围不在此范围,耗时0.1-0.3S的叫sql2
sql1执行计划:

sql2执行计划:

两条完全相同的sql就筛选条件中换了一个departid的值,sql1 191条记录,sql2 256条记录,把sql2的departid换成一个记录数比较多或者比较少的时候,执行计划都不变。
为什么唯独190-200条记录之前,mysql会采用不同的索引呢?
为了搞清楚这个问题,借用optimizer trace功能
mysql默认不开启优化器跟踪功能,开启方法如下
set gloal optimizer_tracer='enabled=on,one_line=on'; # 开启优化器跟踪,并只记录最后一条sql的跟踪。关闭将两个on修改成off即可
查询优化器的信息:
select trace from information_schema.optimizer_trace
执行过程中发现trace字段记录不全,可通过调大参数optimizer_trace_max_mem_size来设置
以下是sql1和sql2的部分trace信息
sql1

sql2

上述trace可以看出,SQL1优化器内部评估cost=249.6是成本最小的执行计划,走idx_duura索引,access_type采用了ref,sql2优化内部评估302.4是成本最低的走了idx_duur索引,access_type采用了range,本来sql2的应该是ref,但是优化器认为采用range会使用上index上更多的索引键(“users_more_keyparts”),这是mysql自身的优化。
在回到上面的执行计划,sql1的key_len=46,ref=const,const,const,46是怎么得来的呢。下面给出计算公式:
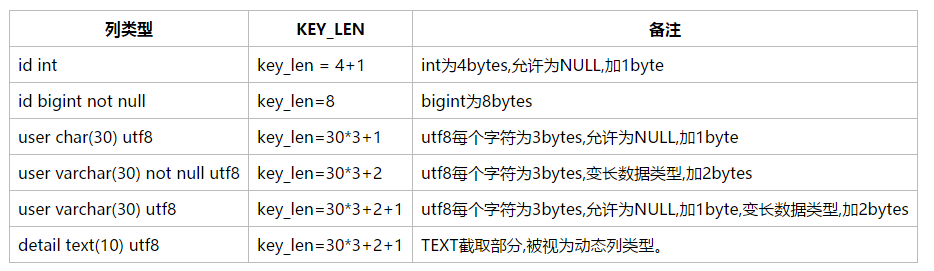
表结构:

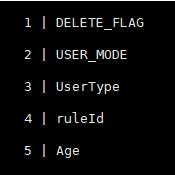
索引idx_duura
索引idx_duur

sql中where条件用到了delete_flag,user_mode,user_type,ruleid
sql1执行计划中的key_len计算方法:1 * 3 + 2 + 10 * 3 + 1 + 2 + 2 * 3 + 2 = 46,用到了三个值,与ref=const,const,const相符
sql2执行计划中的key_len计算方法:1 * 3 + 2 + 10 * 3 + 1 + 2 + 2 * 3 + 2 + 40 * 3 + 2 = 168,同时使用了四个字段,过滤性更好。
以上已经知道了这怪异现象的原因,那应该如何解决呢?
1,根据实际业务场景考虑是否使用force index
2,结合业务修改sql