1.4.1下载网页
这是《
用python写网络爬虫》中的一小节,都是书上的内容(后面的代码分析也是基于这本书的),只不过书上是python2,我改成了python3
简单修改后的代码是这样的:
import urllib.request def download(url,num_retries=2): #url是网址参数,num_retries是对于那些5xx错误,重试下载的次数 print('Downloading:',url) try: html=urllib.request.urlopen(url).read() except urllib.request.URLError as e: print('Download error:',e.reason) html=None if num_retries>0: if hasattr(e,'code') and 500<=e.code<600: return download(url,num_retries-1) return html download('http:httpstat.us/500')把它敲进了pycharm
代码简介
要想爬取网页,首先要将其下载下来;
函数download的基本功能使把传入的URL参数对应的网页下载并返回其HTML;
但是,在下载网页时,可能会遇到一些无法控制的错误,比如请求的页面可能不存在,对于一些临时性的错误,比如服务器过载时返回的503ServiceUnavailable错误,我们可以重新下载,因为这个服务器问题现在可能已被解决了。对于一些无法通过重新请求下载的错误,比如404NotFound,说明是该网页目前并不存在,再试一次还是一样的结果,所以就需要对这种错误予以“跳过”的操作,不再尝试;
我们知道,4xx错误发生在请求存在问题时,5xx错误发生在服务端存在问题时;
所以,我们只需要确保download函数发生在5xx错误使重新下载即可
当download函数遇到5xx错误码时,将会递归调用函数自身进行重试,此外,该函数还增加了一个参数,用于设定重试下载的次数,其默认值为两次。我们在这里限制网页下载的尝试次数,是因为服务器可能暂时没有解决。
程序运行
首先在pycharm运行结果:
Downloading: http:httpstat.us/500
Download error: no host given
Process finished with exit code 0
Download error: no host given
Process finished with exit code 0
拷屏:
![]()

如上图可知,程序并没有按照预期的方式运行,觉得不对,于是用shell再试试
在shell中运行
代码没有改动
代码以及结果拷屏:
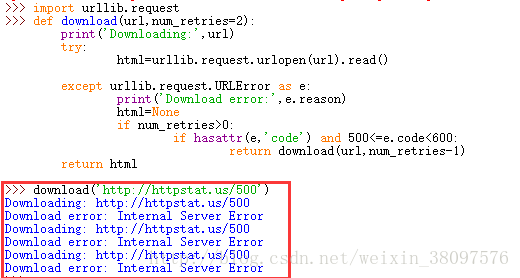
如图中红框中结果所示,和书中的结果一致,当然我还是不知道pycharm中运行的结果为什么只有一次加载,也许……好吧我不瞎说了,有知道的请您留言
本博客说明:
写完期末的爬虫作业,想想自己都大三了,还没学过python,对其一窍不通,python又这么有用,买了《用python写网络爬虫》这本书,边学习爬虫原理,也了解一下python的语法,相信对以后深入学习python会有用
我是个菜鸡,这也是我在CSDN博客的第一篇文章,内容简单,相信很多人已经看过那本书并且对python爬虫了解颇多。如果我的内容和其他人有雷同,请见谅,我写文章是为了记录自己的学习内容,也是激励自己,向大佬们学习,和伙伴们一起进步
当时买了这本书,这今天考试不多了,就拿来学习,发现其基于python2,我安装的是python3,也不换了,现在python的书大多数是python2的,就想着反正逻辑都是一样的,就用这本书呗,把代码都用python3的语法运行一遍,也是一个很好的学习过程