在我的博客《C语言的预处理详解》中最后一段,讲到了#pragma预处理符,其中有一个参数的使用就是#pragma pack(n)。这个参数的意义就是告诉编译器,令编译器按照n个字节进行对齐。
什么又是对齐呢?为什么会有这个东西呢?听我细细道来。
- 什么是内存对齐?
先看下面的结构体。
struct TestStruct1
{
char c1;
short s;
char c2;
int i;
};我问你这个结构体多大呢?这时候你可能就会想,char类型1字节,short2字节,int4字节,看来大小是1+2+1+4=8没跑了。
很可惜并不是这样计算的。依照这样的思维去计算地址也会是错误的结果。而造成我们错误的“元凶”正是内存对齐。
对于字,双字,四字数据来说,在自然边界上时则不需要对齐。(它们的自然边界分别是 偶数地址,可以被4整除的地址,可以被8整除的地址)。将这些数据分别对齐到自己的自然边界上,这样的过程就叫做内存对齐。
通俗的讲就是,每个数据既要保证自己的对齐字节基准(自己大小和pragma定义中的较小的一个),又要让自己的地址在边界上,最后还要保证结构体大小是所有使用过数据类型的整数倍。
- 为什么会有内存对齐?
无论如何,为了提高程序的性能,数据结构(尤其是栈)应该尽可能在自然边界上对齐。原因在于为了访问未对齐的内存处理器需要作两次内存访问的操作,对齐后则只需一次,效率大大提升。
一个字或双字操作数跨越了4字节边界,或者一个四字操作数跨越了8字节边界就认为是未对齐的。
那么我们了解了这些,现在再来看看我们的TestStruct1.

我们要对每个数据进行对齐,所有的单字数据我们给它分配2个字节,short给他分配2个字节,int分配4个。
即现在是:
char c1 - --2
short s ---2
char c2 ----2
int i ----4这样看来好像已经没问题了。但是内存对齐还有个规则就是,最终结构体的大小必须是所有使用过的数据类型的倍数(即这里取最大的int,4字节的倍数)。现在的大小是10,并不是int的4个字节的倍数啊。这样我们就只能再加2个字节空间了,那么这两个字节在哪呢?int i为了保证内存对齐需要让自己的地址是8的倍数,所以在c2后面添加2个字节(不属于c2),这样i的地址就是从2+2+2+2=8开始了。所以真正的存储结构应当是这样的:
char c1 //2
short s //2
char c2 //2
//空余两个字节,不属于任何变量
int i //4大小是2+4+2+4=12个字节。
- 关于避免内存对齐的影响
上面的TestStruct1经过了内存对齐,大小比我们原先预想的要大得多。那么有没有办法可以优化一下,让它的大小小一点同时兼顾高性能呢?
struct TestStruct2
{
char c1;
char c2;
short s;
int i;
}这样每个成员就本身都对齐在自然边界上了,可以避免编译器的自动对齐。这时TestStruct2的大小就是8.
(一个字起始地址是奇数但却没有跨越字边界被认为是对齐的。)
- #pragma pack(n) 预处理指令
#pragma pack指令可以用来调整编译器的默认对齐方式,将会按照n个字节进行对齐。若直接使用#pragma pack()而不加参数则编译器会取消自定义字节对齐方式。
但是需要注意的是,按照n个字节对齐并非是每个数据都必须是n个字节。每个成员还是按照自己的方式对齐,只不过对齐时从对齐参数(通常是该类型的大小)和n中取较小的那个。下面来看两个例子。
#pragma pack(8)
struct TestStruct3
{
char a;
long b;
};
struct TestStruct4
{
char c;
TestStruct3 d;
long long e;
};
#pragma pack()
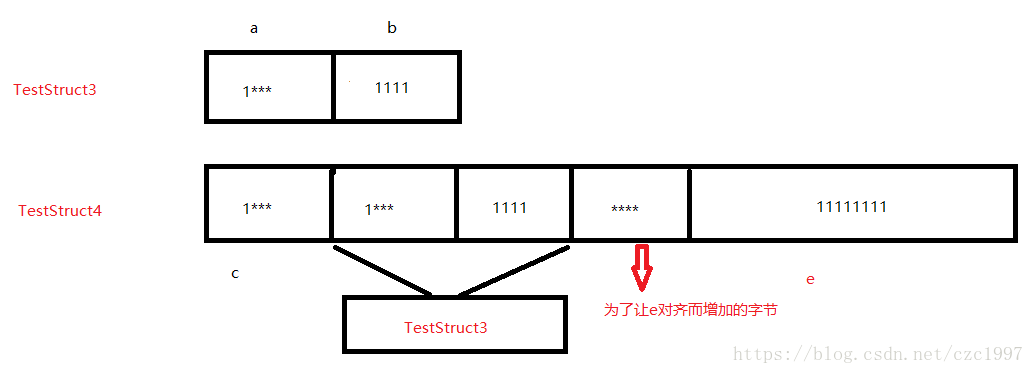
问题:sizeof(TestStruct4)=? TestStruct4里面c后面空了几个字节接着是d?
我们先看第一个问题:很容易得到TestStruct3的大小是8(char a应当分配4个字节满足内存对齐),看向TestStruct4中,由于longlong类型和TestStruct3大小一致都是8字节,同时我们定义了#pragma pack(8),都是8字节并没有比较的必要,所以TestStruct4的大小应当是8的倍数。TestStruct3作为一个结构体,它是按照什么对齐的呢?结构体的对齐是按照结构体内最大的数据类型作为参考的,即d是按照4字节对齐的。
那么答案一目了然了:为了保证d按照4字节对齐,char c分配4个字节;d的大小为8个字节,现在地址偏移量为8+4=12;但是我们要保证longlong e的8字节对齐,所以我们再加入4个字节将地址偏移量增加到16,这时可以存放e,最终大小为16+8=24。第二个问题也迎刃而解,c后面空3个字节是结构体d。具体图解如下。
现在,你应该对内存对齐有着较深的理解了。