
前言
这已经是我第二次编写Git原理方面的博文了。之前走了不少弯路,对于很多问题的理解也浮于表面,所以决定重新整理一次。其实之前的弯路很大一部分原因是读了劣质的资料导致的,所以强烈建议除了ProGit以外其他的国产资料仅做参考。
分布式
版本控制的概念不多做解释了,我们常用的SVN属于集中化的版本控制系统,而Git属于分布式版本控制系统(Distributed Version Control System,简称 DVCS)。在这类系统中客户端并不只提取最新版本的文件快照,而是把代码仓库完整地镜像下来。 这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。 因为每一次的克隆操作,实际上都是一次对代码仓库的完整备份。
更进一步,许多这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,你就可以在同一个项目中,分别和不同工作小组的人相互协作。 你可以根据需要设定不同的协作流程,比如层次模型式的工作流,而这在以前的集中式系统中是无法实现的。
版本文件管理
Git在对待数据版本管理上的做法,与其他版本控制系统不同。其他系统存储版本变更信息,就像用一个记事本记录下了文件的变化情况。而Git采用保存“快照流”的方式管理文件,就像是把原来的文件放到抽屉里,然后在新的复印件上做出修改。
存储版本变更信息方式:

快照流方式:
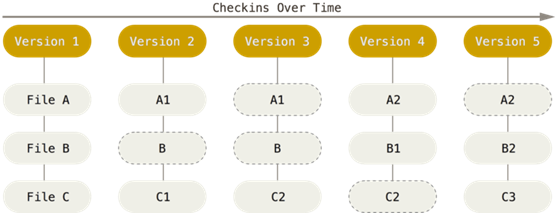
这里要强调一下,只有被修改过的文件才会在对应版本产生出新的快照。所以每次提交所产生的快照不是整个文件系统,而是被修改过的那部分文件。(上图虚线圈出的文件表示没有生成新的快照)
本地执行
Git在每个用户机器上都有一份完整的版本库,所以我们在集中式版本控制系统通常所做的提交代码、比较代码、分支合并等工作在本地就可以完成,而且速度极快。
但是不同开发者之间的代码协作,还是需要通过网络连接远程仓库进行交换的。
文件状态(已修改和已暂存、已提交)
Git管理的文件存在三个状态即已提交(committed)、已修改(modified)和已暂存(staged) 已提交表示数据已经安全的保存在本地数据库中。 已修改表示修改了文件,但还没保存到数据库中。 已暂存表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
由此引入 Git 项目的三个工作区域的概念:Git 仓库、工作目录以及暂存区域。
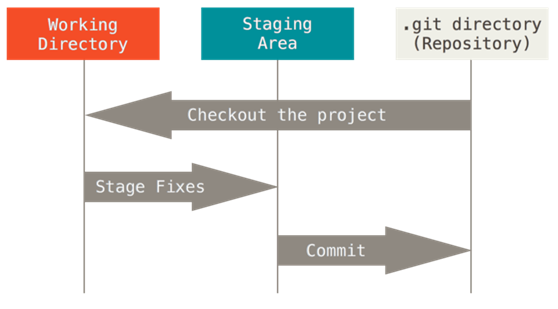
Git 仓库目录是 Git 用来保存项目的元数据和对象数据库的地方。 这是 Git 中最重要的部分,从其它计算机克隆仓库时,拷贝的就是这里的数据。
工作目录是对项目的某个版本独立提取出来的内容。 这些从 Git 仓库的压缩数据库中提取出来的文件,放在磁盘上供你使用或修改。
暂存区域是一个文件,保存了下次将提交的文件列表信息,一般在 Git 仓库目录中。 有时候也被称作`‘索引’',不过一般说法还是叫暂存区域。
基本的 Git 工作流程如下:
-
在工作目录中修改文件。
-
暂存文件,将文件的快照放入暂存区域。
-
提交更新,找到暂存区域的文件,将快照永久性存储到 Git 仓库目录。
如果 Git 目录中保存着的特定版本文件,就属于已提交状态。 如果作了修改并已放入暂存区域,就属于已暂存状态。 如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态。
标签(tag)
像其他版本控制系统(VCS)一样,Git 可以给历史中的某一个提交打上标签,以示重要。 比较有代表性的是人们会使用这个功能来标记发布结点(v1.0 等等)。
Git 使用两种主要类型的标签:轻量标签(lightweight)与附注标签(annotated)。
一个轻量标签很像一个不会改变的分支 - 它只是一个特定提交的引用。(这点与svn不同svn的标签是会移动的)
然而,附注标签是存储在 Git 数据库中的一个完整对象。 它们是可以被校验的;其中包含打标签者的名字、电子邮件地址、日期时间;还有一个标签信息;并且可以使用 GNU Privacy Guard (GPG)签名与验证。 通常建议创建附注标签,这样你可以拥有以上所有信息;但是如果你只是想用一个临时的标签,或者因为某些原因不想要保存那些信息,轻量标签也是可用的。
提交(commit)
在进行提交操作时,Git 会保存一个提交对象(commit object)。知道了 Git 保存数据的方式,我们可以很自然的想到——该提交对象会包含一个指向暂存内容快照的指针。 但不仅仅是这样,该提交对象还包含了作者的姓名和邮箱、提交时输入的信息以及指向它的父对象的指针。首次提交产生的提交对象没有父对象,普通提交操作产生的提交对象有一个父对象,而由多个分支合并产生的提交对象有多个父对象。
从单次提交角度来看,提交(commit)指向了一个快照文件目录树(tree),目录树指向了多个文件快照(blob)。这样我们就可以通过提交找到本次提交的所有文件快照了。
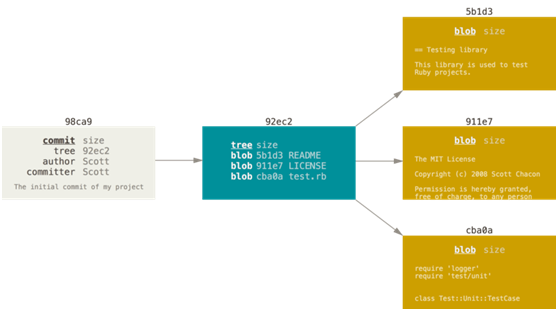
从提交流角度来看,提交对象会包含一个指向上次提交对象(父对象)的指针。
下图展示了提交即关联自己的快照又关联父提交。
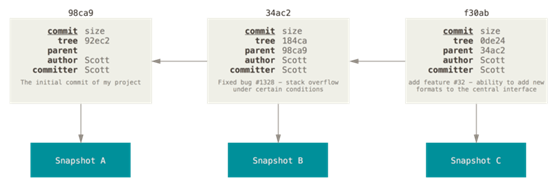
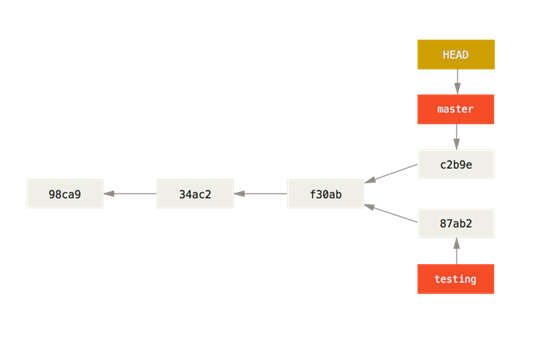
提交的这些模式最终组成了Git的提交树结构。
每个仓库拥有唯一的提交树结构,分支和标签只不过是指向某个节点的指针而已。
分支(branch)
几乎所有的版本控制系统都以某种形式支持分支。 使用分支意味着你可以把你的工作从开发主线上分离开来,以免影响开发主线。 在很多版本控制系统中(svn),这是一个略微低效的过程——常常需要完全创建一个源代码目录的副本。对于大项目来说,这样的过程会耗费很多时间。
结合提交部分的说明,我们知道Git仅有一个提交树。而Git 的分支其实本质上仅仅是指向提交对象的可变指针。 Git 的默认分支名字是 master。 在多次提交操作之后,你其实已经有一个指向最后那个提交对象的 master 分支。 它会在每次的提交操作中自动向前移动。
Git 是怎么创建新分支的呢? 很简单,它只是为你创建了一个可以移动的新的指针。
那么,Git 又是怎么知道当前在哪一个分支上呢? 也很简单,它有一个名为 HEAD 的特殊指针。 请注意它和许多其它版本控制系统(如 Subversion 或 CVS)里的 HEAD 概念完全不同。 在 Git 中,它是一个指针,指向当前所在的本地分支(译注:将 HEAD 想象为当前分支的别名)。
切换分支就是将HEAD指针指向另一另一个本地分支。
如果我们从一次提交创建不同分支,之后又分别在这些分支上做出了新的提交。这时项目将会产生分叉提交历史,多个提交将指向同一个父提交。这些分叉如果想要最终合并回原来的分支,我们就要通过合并或变基操作来解决。
远程分支
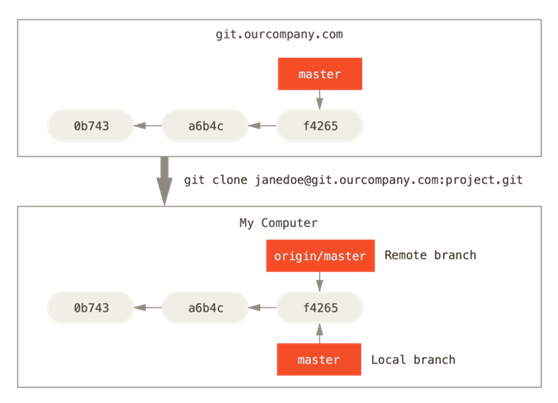
远程引用是对远程仓库的引用(指针),包括分支、标签等等。
远程跟踪分支是远程分支状态的引用。 它们是你不能移动的本地引用,当你做任何网络通信操作时,它们会自动移动。 远程跟踪分支像是你上次连接到远程仓库时,那些分支所处状态的书签。
它们以 (remote)/(branch) 形式命名。 例如,如果你想要看你最后一次与远程仓库 origin 通信时 master
分支的状态,你可以查看 origin/master 分支。
跟踪分支
从一个远程跟踪分支检出一个本地分支会自动创建一个叫做 “跟踪分支”(有时候也叫做 “上游分支”)。 跟踪分支是与远程分支有直接关系的本地分支。 如果在一个跟踪分支上输入 git pull或git push,Git 能自动地识别去哪个服务器上抓取、合并到哪个分支。
当克隆一个仓库时,它通常会自动地创建一个跟踪 origin/master 的 master 分支。 然而,如果你愿意的话可以设置其他的跟踪分支 - 其他远程仓库上的跟踪分支,或者不跟踪 master 分支。
跟踪分支信息一般保存在local级别的配置文件当中
branch.master.remote=origin
branch.master.merge=refs/heads/master
branch.dev_5.2.remote=origin
branch.dev_5.2.merge=refs/heads/dev_5.2合并(merge)
我们想将出现分叉提交的分支整合在一起时,可以使用合并(merge)操作来完成。
Git 会使用两个分支的末端所指的快照以及这两个分支的工作祖先,做一个简单的三方合并。
和之前将分支指针向前推进所不同的是,Git 将此次三方合并的结果做了一个新的快照并且自动创建一个新的提交指向它。 这个被称作一次合并提交,它的特别之处在于他有不止一个父提交。
需要指出的是,Git 会自行决定选取哪一个提交作为最优的共同祖先,并以此作为合并的基础;这和更加古老的 CVS 系统或者 Subversion (1.5 版本之前)不同,在这些古老的版本管理系统中,用户需要自己选择最佳的合并基础。 Git 的这个优势使其在合并操作上比其他系统要简单很多。
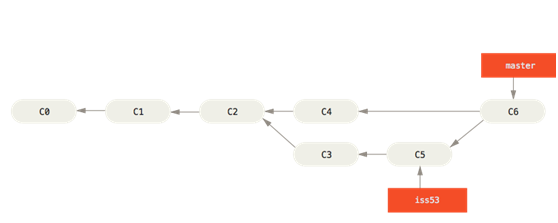
所以我们可以将合并理解为,从分叉提交中提取全部快照整合在一起,最后做一次新的提交。并且新提交拥有多个父提交。
快进合并(fast-forward)
当你试图合并两个分支时,如果顺着一个分支走下去能够到达另一个分支,那么 Git 在合并两者的时候,只会简单的将指针向前推进(指针右移),因为这种情况下的合并操作没有需要解决的分歧——这就叫做 “快进(fast-forward)”。

master只要向前推进就可以完成与iss53的合并,所以会使用快进合并。
合并冲突
有时候合并操作不会如此顺利。 如果你在两个不同的分支中,对同一个文件的同一个部分进行了不同的修改,Git 就没法干净的合并它们。在合并它们的时候就会产生合并冲突。
此时 Git 做了合并,但是没有自动地创建一个新的合并提交。 Git 会暂停下来,等待你去解决合并产生的冲突。等你手动解决之后,Git 会询问刚才的合并是否成功。 如果你回答是,Git 会暂存那些文件以表明冲突已解决。
如果你对结果感到满意,并且确定之前有冲突的的文件都已经暂存了,这时你可以输入 git commit 来完成合并提交。 从而产生一次新的合并提交。
与无冲突合并的区别主要有:
1、需要手动解决冲突并标记已解决。
2、需要自己提交新的合并提交。
变基(rebase)
在 Git 中整合来自不同分支的修改主要有两种方法:merge 以及 rebase。
你可以提取在一个分支中引入的补丁和修改,然后在另一个分支的基础上应用一次。 在 Git 中,这种操作就叫做 变基。 你可以使用变基将提交到某一分支上的所有修改都移至另一分支上,就好像“重新播放”一样。
它的原理是首先找到这两个分支(即当前分支、变基操作的目标基底分支)的最近共同祖先,然后对比当前分支相对于该祖先的历次提交,提取相应的修改并存为临时文件,然后将当前分支指向目标基底, 最后以此将之前另存为临时文件的修改依序应用。

| 呃,奇妙的变基也并非完美无缺,要用它得遵守一条准则: 不要对在你的仓库外有副本的分支执行变基。 如果你遵循这条金科玉律,就不会出差错。 否则,人民群众会仇恨你,你的朋友和家人也会嘲笑你,唾弃你。 (也就是说已经推送到远程分支的内容就不要进行变基了,否则会对别人的造成困扰) |
交互式变基(interactive)
交互式变基主要用于将多次提交合并成一次提交。
我们通常会在完成一个功能时,合并杂乱的提交从而使提交树更加简洁。
交互式变基允许我们自由的选择提交,并且重新编辑提交说明。
变基 vs. 合并
至此,你已在实战中学习了变基和合并的用法,你一定会想问,到底哪种方式更好。 在回答这个问题之前,让我们退后一步,想讨论一下提交历史到底意味着什么。
有一种观点认为,仓库的提交历史即是 记录实际发生过什么。 它是针对历史的文档,本身就有价值,不能乱改。 从这个角度看来,改变提交历史是一种亵渎,你使用_谎言_掩盖了实际发生过的事情。 如果由合并产生的提交历史是一团糟怎么办? 既然事实就是如此,那么这些痕迹就应该被保留下来,让后人能够查阅。
另一种观点则正好相反,他们认为提交历史是 项目过程中发生的事。 没人会出版一本书的第一版草稿,软件维护手册也是需要反复修订才能方便使用。 持这一观点的人会使用 rebase 及 filter-branch 等工具来编写故事,怎么方便后来的读者就怎么写。
现在,让我们回到之前的问题上来,到底合并还是变基好?希望你能明白,这并没有一个简单的答案。 Git 是一个非常强大的工具,它允许你对提交历史做许多事情,但每个团队、每个项目对此的需求并不相同。 既然你已经分别学习了两者的用法,相信你能够根据实际情况作出明智的选择。
总的原则是,只对尚未推送或分享给别人的本地修改执行变基操作清理历史,从不对已推送至别处的提交执行变基操作,这样,你才能享受到两种方式带来的便利。
应用提交(cherry-pick)
cherry-pick允许我们提取一个或多个现有的提交,并使用这些提交的快照来创建新的提交。
也就是说我们能够提取某一次提交的变更,应用在其他分支当中。
这个功能在处理生产bug时将会非常有用。如果我们在开发分支正在进行开发时出现了一个生产bug,就需要创建一个bug分支。但是bug分支即要合并到开发分支进行测试,又要合并到生产分支解决问题,显然使用分支合并方式无法完美的解决这个问题。
上面这种情况使用cherry-pick正合适。在bug分支修改完之后,我们可以将修复bug的提交分别cherry-pick到生产和开发分支。由于使用cherry-pick创建的提交标识名都是一致的,在生产上线时执行变基操作并不会产生冲突,会完美的合并成一次提交。
储藏(stash)
有时,当你在项目的一部分上已经工作一段时间后,所有东西都进入了混乱的状态,而这时你想要切换到另一个分支做一点别的事情。 问题是,你不想仅仅因为过会儿回到这一点而为做了一半的工作创建一次提交。 针对这个问题的答案是 git stash 命令。
储藏会处理工作目录的脏的状态 - 即,修改的跟踪文件与暂存改动 - 然后将未完成的修改保存到一个栈上,而你可以在任何时候重新应用这些改动。