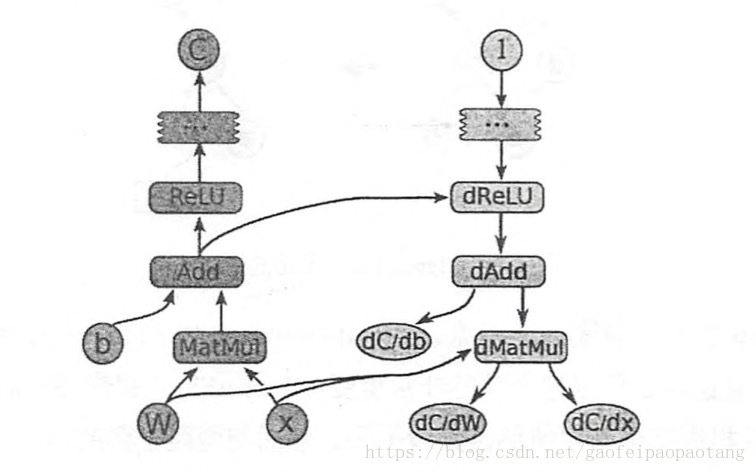
梯度的计算是频繁的任务。在所有的的learning algorithm里几乎都用到了梯度。可以参考这片训练算法总结。本文中我具体介绍各式各样的训来拿算法,而把焦点聚焦在梯度计算这个子任务上。
梯度的定义
对于一个 的函数: , 它的梯度可以定义为:
微分的计算
梯度的计算涉及到函数微分的计算,一般来说主要有三种方式来计算函数的微分。
- Numerical Differentiation
- Symbolic Differentiation
- Automatic Differentiation
Numertical differentiation
这种方式是通过微分的定义直接来计算的:
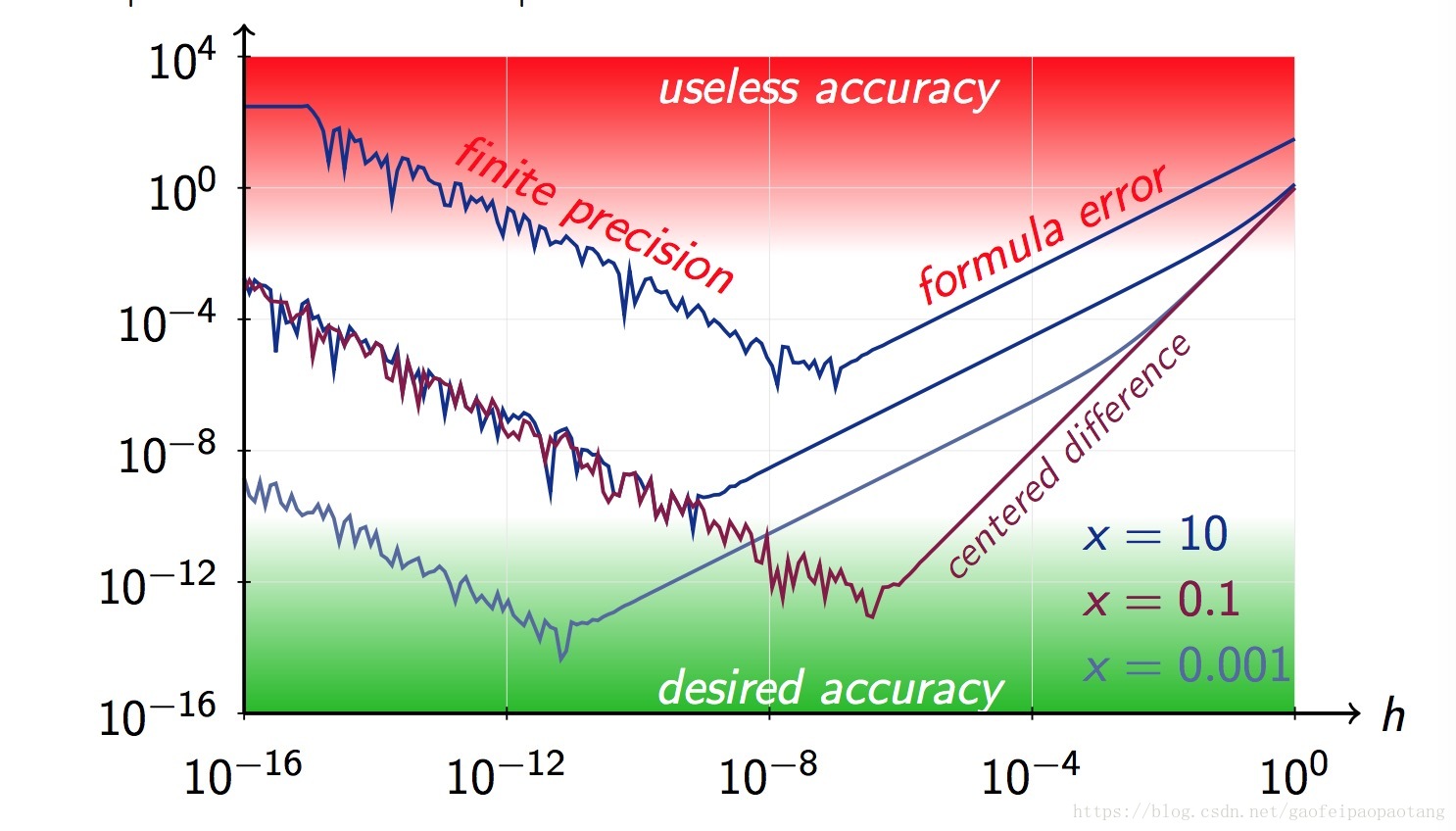
实际计算中我们去一个较小的值 ,用这种方式计算的结果近似实际的微分值。这种方式的优点是即使不知道是什么函数也能计算微分值,缺点也是很明显的,就是h的值取多大才能满足误差的需求呢,还有就是计算中的各种误差累积的结果可能导致最终的误差比较大。
我们来通过一个例子看一下误差与h的取值的关系.
比如对于函数 , 误差为:
横轴表示h,纵轴表示误差值 .
Symbolic Differentitation
这种方式必须首先知道函数的表达式,然后通过法则推出导数的表达式来计算微分值。
例如,我们需要计算函数
的微分,根据法则,我们得到:
随着模型规模的增大,实际中TF中的函数可能非常复杂,推导出微分的表达式非常困难。
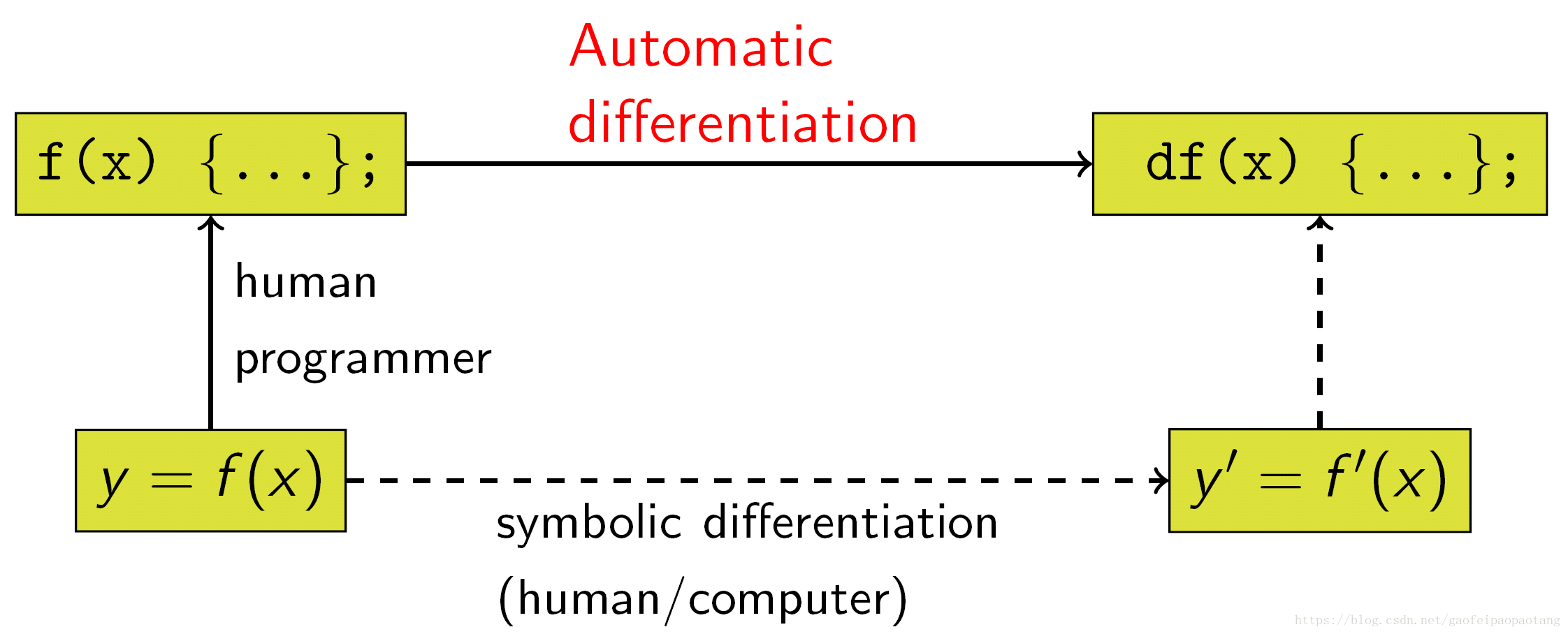
Automatic Differentiation
我们来看一下这种方式与其他方式的关系:
在介绍TF中auto differentiation的具体实现之前,先介绍一下链式法则:
- case 1:
假设有可微函数 ,则:
- case 2:
假设有可微分的函数 ,则:
- case 3:
假设有可微函数 , 则:
- case 4:
更一般的情况,假设有可微分函数 , 则:
由此我们得出微分计算的两种方式:
- 正向计算:
- 逆向计算:
梯度的计算
下面介绍梯度的计算,以 函数为例,假设有函数 , 由微分的链式计算得出公式:
grad L(z) = dL/dz = 1
grad L(y) = dL/dy = dL/dz * dz/dy = grad L(z) * dz/dy
grad L(x) = dL/dx = dL/dy * dy/dx = grad L(y) * dy/dx
则个过程被称为梯度的逆向传播。由微分的计算公式,很容易推导出 函数梯度的传播公式,以后有时间再补充。
复变函数的梯度计算
以上的讨论的函数,都是在实数范围内,现在有很多基于复数模型,TF中也支持compplex64和complex128复数变量类型。对于复变函数来说,也存在计算梯度的问题,而且TF中复变函数的梯度计算容易引起误解,比如我们来看一个问题:
我在问题的回复中解释的也比较详细了,这里再复述一遍。
还是以最简单的函数 来介绍。对于复变函数,如果我们沿用实数函数梯度的定义方式,则上面的梯度链式计算方式就不适用了,为了满足链式计算方式,我们为复变函数定义梯度如下:
- 对于一个复变函数 , 我们定义两个梯度,分别是实梯度 ,虚梯度为 .
类似的,我们来看一下复变函数的梯度是如何传播的:
假设有复变函数: 都是复数。
grad_real L(z) = (dz_real/dz_real + i * dz_real/dz_imag) = (1, 0)
grad_imag L(z) = (dz_imag/dz_real + i * dz_imag/dz_real) = (0, i)
grad_real L(y) = (dz_real/dy_real + i * dz_real/dy_imag)
= (1, 0) * (dz_real/dy_real + i * dz_real/dy_imag)
And we know that for a analytic fucntion z = z(y) , wo get Cauchy–Riemann equations:
dz_real/dy_real = dz_imag/dy_imag
dz_real/dy_imag = - dz_imag/dz_real
and we know that :
dz/dy = dz_real/dy_real + i * dz_imag/dz_real
= dz_real/dy_real - i * dz_real/dy_imag
= dz_imag/dy_imag + i * dz_imag/dy_real
= dz_imag/dy_imag - i * dz_real/dy_imag
so,
grad_real L(y) = (1, 0) * (dz_real/dy_real + i * dz_real/dy_imag)
= grad_real(z) * conjugate(dz_real/dy_real - i * dz_real/dy_imag)
= grad_real(z) * conjugate(dz/dy)
grad_imag L(y) = (dz_imag/dy_real + i * dz_imag/dy_imag)
= (0, i) * (dz_imag/dy_imag - i * dz_imag/dy_real)
= grad_imag(z) * conjugate(dz_imag/dy_imag + i * dz_imag/dy_real)
= grad_imag(z) * conjugate(dz/dy)
grad_real L(x) = dz_real/dx_real + i * dz_real/dx_imag
= (dz_real/dy_real * dy_real/dx_real + dz_real/dy_imag * dy_imag/dx_real) + i * (dz_real/dy_real*dy_real/dx_imag + dz_real/dy_imag * dy_imag/dx_imag)
= dz_real/dy_real * (dy_real/dx_real + i * dy_real/dx_imag) + dz_real/dy_imag * (dy_imag/dx_real + i * dy_imag/dx_imag)
= dz_real/dy_real * (dy_real/dx_real + i * dy_real/dx_imag) + i * dz_real/dy_imag * (dy_imag/dx_imag - i * dy_imag/dx_real)
= dz_real/dy_real * conjugate(dy_real/dx_real - i * dy_real/dx_imag) + i * dz_real/dy_imag * conjugate(dy_imag/dx_imag + i * dy_imag/dx_real)
= dz_real/dy_real * conjugate(dy/dx) + i * dz_real/dy_imag * conjugate(dy/dx)
= (dz_real/dy_real + i * dz_real/dy_imag) * conjugate(dy/dx)
= grad_real L(y) * conjugate(dy/dx)
grad_real L(x) = dz_imag/dx_real + i * dz_imag/dx_imag
= (dz_imag/dy_real * dy_real/dx_real + dz_imag/dy_imag * dy_imag/dx_real) + i * (dz_imag/dy_real * dy_real/dx_imag + dz_imag/dy_imag * dy_imag/dx_imag)
= dz_imag/dy_real * (dy_real/dx_real + i * dy_real/dx_imag) + dz_imag/dy_imag * (dy_imag/dx_real + i * dy_imag/dx_imag)
= dz_imag/dy_real * (dy_real/dx_real + i * dy_real/dx_imag) + i * dz_imag/dy_imag * (dy_imag/dx_imag - dy_imag/dx_real)
= dz_imag/dy_real * conjugate(dy_real/dx_real - i * dy_real/dx_imag) + i * dz_imag/dy_imag * conjugate(dy_imag/dx_imag + dy_imag/dx_real)
= dz_imag/dy_real * conjugate(dy/dx) + i * dz_imag/dy_imag * conjugate(dy/dx)
= (dz_imag/dy_real + i * dz_imag/dy_imag) * conjugate(dy/dx)
= grad_imag L(y) * conjugate(dy/dx)因为实数的共轭复数永远是自己本身,所以以上的实数函数和复变函数的梯度计算公式可以合并成如下的形式:
Grad L(y) = Grad L(z) * conjugate(dz/dy)
Grad L(x) = Grad L(y) * conjugate(dy/dx)TF中的实现
TF为每个需要计算梯度的基本操作都注册一个相对应的梯度函数,TF的会通过自动添加梯度函数来实现梯度自动计算。