1.Task_struct结构体
inux系统中的每个进程都有一个名为task_struct的数据结构,它相当于“进程控制块(PCB)”。
内核在为每个进程分配Task_struct结构的内存空间时,实际上一次性分配两个连续的 内存页面(共8KB),其底部约1KB空间存放Task_struct结构,上面的7KB空间存放进程系统空间堆栈。 如图所示 :
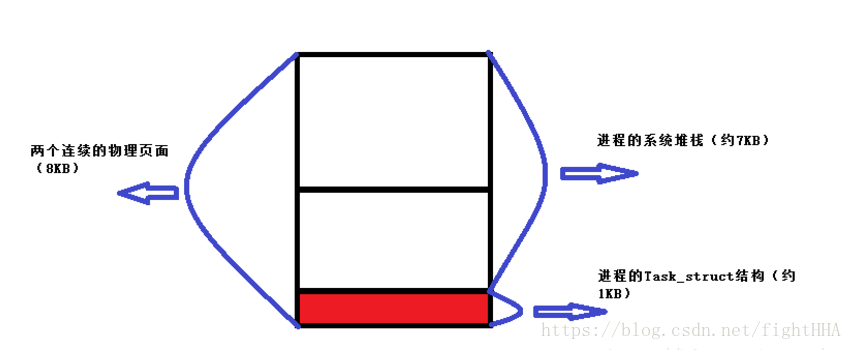
在进行剖析task_struct的定义之前,我们先按照我们的理论推一下它的结构:
1、进程状态 ,将纪录进程在等待,运行,或死锁
2、调度信息, 由哪个调度函数调度,怎样调度等
3、进程的通讯状况
4、因为要插入进程树,必须有联系父子兄弟的指针, 当然是task_struct型
5、时间信息, 比如计算好执行的时间, 以便cpu 分配
6、标号 ,决定改进程归属
7、可以读写打开的一些文件信息
8、 进程上下文和内核上下文
9、处理器上下文
10、内存信息
(1)long state //任务的运行状态(-1 不可运行,0 可运行(就绪),>0 已停止)。
(2)long counter //任务运行时间计数(递减)(滴答数),运行时间片。
(3)long priority //运行优先数。任务开始运行时counter = priority,越大运行 越长。
(4)long signal //信号。是位图,每个比特位代表一种信号,信号值=位偏移值+1。
(5)struct sigaction sigaction[32] //信号执行属性结构,对应信号将要执行的操作和标志信息。
(6)long blocked //进程信号屏蔽码(对应信号位图)。
(1) volatile long states;
表示进程的当前状态:
* TASK_RUNNING:正在运行或在就绪队列run-queue中准备运行的进程,实际参与进程调度。
* TASK_INTERRUPTIBLE:处于等待队列中的进程,待资源有效时唤醒,也可由其它进程通过信号(signal)或定时中断唤醒后进入就绪队列 run-queue。
* TASK_UNINTERRUPTIBLE:处于等待队列中的进程,待资源有效时唤醒,不可由其它进程通过信号(signal)或定时中断唤醒。

* TASK_ZOMBIE:表示进程结束但尚未消亡的一种状态(僵死状态)。此时,进程已经结束运行且释放大部分资源,但尚未释放进程控制块。
*TASK_STOPPED:进程被暂停,通过其它进程的信号才能唤醒。导致这种状态的原因有二,或者是对收到SIGSTOP、SIGSTP、 SIGTTIN或SIGTTOU信号的反应,或者是受其它进程的ptrace系统调用的控制而暂时将CPU交给控制进程。
* TASK_SWAPPING: 进程页面被交换出内存的进程。
(2) unsigned long flags;
进程标志:
*PF_ALIGNWARN 打印“对齐”警告信息。
*PF_PTRACED 被ptrace系统调用监控。
*PF_TRACESYS 正在跟踪。
*PF_FORKNOEXEC 进程刚创建,但还没执行。
*PF_SUPERPRIV 超级用户特权。
*PF_DUMPCORE dumped core。
*PF_SIGNALED 进程被信号(signal)杀出。
*PF_STARTING 进程正被创建。
*PF_EXITING 进程开始关闭。
*PF_USEDFPU 该进程使用FPU(SMP only)。
*PF_DTRACE delayed trace (used on m68k)。
(3) long priority;
进程优先级。 Priority的值给出进程每次获取CPU后可使用的时间(按jiffies计)。优先级可通过系统调用sys_setpriorty改变(在 kernel/sys.c中)。
(4) unsigned long rt_priority;
rt_priority 给出实时进程的优先级,rt_priority+1000给出进程每次获取CPU后可使用的时间(同样按jiffies计)。实时进程的优先级可通过系统 调用sys_sched_setscheduler()改变(见 kernel/sched.c)。
(5) long counter;
在轮转法调度时表示进程当前还可运行多久。在进程开始运行是被赋为priority的值,以后每隔一个tick(时钟中断)递减1,减到0时引起新一轮调 度。重新调度将从run_queue队列选出counter值最大的就绪进程并给予CPU使用权,因此counter起到了进程的动态优先级的作用 (priority则是静态优先级)。
(6) unsigned long policy;
该进程的进程调度策略,可以通过系统调用sys_sched_setscheduler()更改(见kernel/sched.c)。调度策略有:
*SCHED_OTHER 0 非实时进程,基于优先权的轮转法(round robin)。
*SCHED_FIFO 1 实时进程,用先进先出算法。
*SCHED_RR 2 实时进程,用基于优先权的轮转法。
2.虚拟内存
大多数进程都使用虚拟内存空间。Linux系统必须了解如何将虚拟内存映射到系统的物理内存。
每个内存都有一个地址空间,是个虚拟地址。
从虚拟内存到到物理内存是通过页表的映射。如:
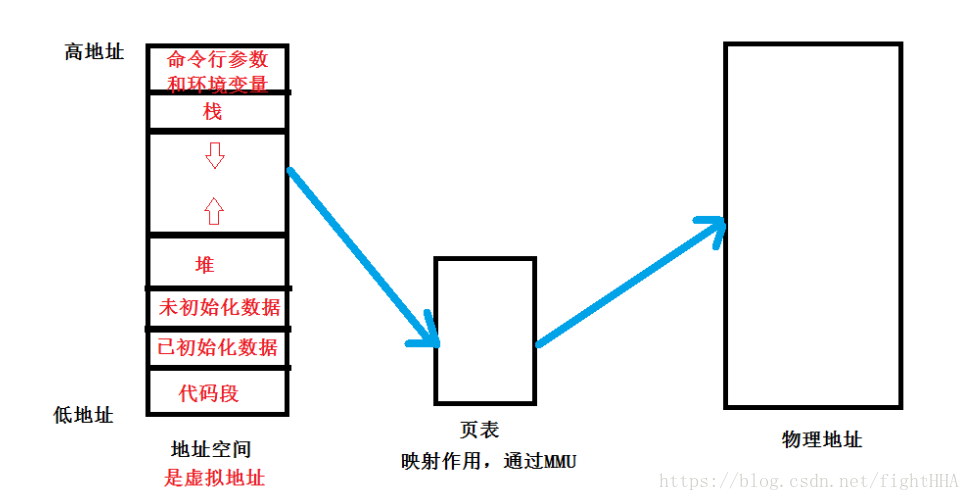
有效保护了物理内存
3.内部进程信息
Linux系统支持信号、管道、信号量等内部进程通信机制。
1)、信号机制是在软件层次上对中断机制的一种模拟。系统预先规定若干不同类型的信号,各表示发生了不同的事件,每个信号对应一个编号。进程遇到相应的事件或出现特定的要求(进程终止或出现某些错误——非法指令,地址越界等),就把一个信号写到相应进程Task_struct结构。接收信号的进程在运行中检测自身是否收到了信号,如过已收到,则转去执行预先规定好的信号处理程序。处理后,返回原先正在执行的进程。
信号实现进程间通信的过程:
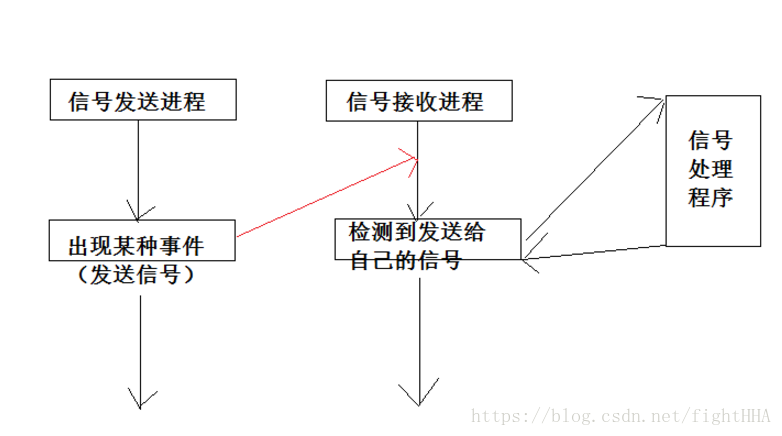
进程接到信号后,在一定时机做相应处理:
- 忽略信号
- 阻塞信号
- 由进程处理该信号
- 由系统默认处理
2)、管道文件
管道是Linux中最常用的IPC机制。一个管道就是链接两个进程的一个打开文件。
管道文件不属于用户直接命名的普通文件,它是利用系统调用的pipe()创建的、在同族进程间进行大量的信息传送的打开文件。
每个管道只有一个内存页面作缓冲区,按环缓冲方式使用。就是每读或写到页面的末端,就又回到开头。
由于管道缓冲区只限于一个页面,因此,当写进程有大量数据要写时,每写满一个页面,就要睡眠等待,等读进程从管道中读走一些数据而腾出空间时,读进程唤醒写进程,写进程就继续写入数据。对读进程,缓冲区有数据就读出,没有数据就睡眠,等待写进程向缓冲区中写数据;当写进程写入数据后,就唤醒正在等待的读进程。
3)System V IPC机制三种进程间的通信:
(1)、消息通信:一个进程可以通过系统调用建立一个消息队列,然后任何进程都可以通过系统调用向这个队列发送消息或从队列中接收消息,实现进程间信息传递。
(2)、共享内存:一个进程可以通过系统调用设立一片共享内存,然后其他进程就可以通过系统调用将该内存区映射到自己的用户地址空间。
(3)、信号量:信号量机制可以实现进程间的同步,保证若干进程对共享的临界资源的互斥。(信号量是系统内的数据结构,它的值代表着可以使用的资源的数量,可以被一个或多个进程进行检测和设置)
4.进程的调度算法
在操作系统中存在多种调度算法,其中有的调度算法适用于作业调度,有的调度算法适用于进程调度,有的调度算法两者都适用。下面介绍几种常用的调度算法。
(1)先来先服务(FCFS)调度算法
FCFS调度算法是一种最简单的调度算法,该调度算法既可以用于作业调度也可以用于进程调度。在作业调度中,算法每次从后备作业队列中选择最先进入该队列的一个或几个作业,将它们调入内存,分配必要的资源,创建进程并放入就绪队列。
在进程调度中,FCFS调度算法每次从就绪队列中选择最先进入该队列的进程,将处理机分配给它,使之投入运行,直到完成或因某种原因而阻塞时才释放处理机。
FCFS调度算法属于不可剥夺算法。从表面上看,它对所有作业都是公平的,但若一个长作业先到达系统,就会使后面许多短作业等待很长时间,因此它不能作为分时系统和实时系统的主要调度策略。但它常被结合在其他调度策略中使用。例如,在使用优先级作为调度策略的系统中,往往对多个具有相同优先级的进程按FCFS原则处理。
FCFS调度算法的特点是算法简单,但效率低;对长作业比较有利,但对短作业不利(相对SJF和高响应比);有利于CPU繁忙型作业,而不利于I/O繁忙型作业。
(2)短作业优先(SJF)调度算法
短作业(进程)优先调度算法是指对短作业(进程)优先调度的算法。短作业优先(SJF)调度算法是从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行。而短进程优先(SPF)调度算法,则是从就绪队列中选择一个估计运行时间最短的进程,将处理机分配给它,使之立即执行,直到完成或发生某事件而阻塞时,才释放处理机。
SJF调度算法也存在不容忽视的缺点:
该算法对长作业不利,由表2-3和表2-4可知,SJF调度算法中长作业的周转时间会增加。更严重的是,如果有一长作业进入系统的后备队列,由于调度程序总是优先调度那些 (即使是后进来的)短作业,将导致长作业长期不被调度(“饥饿”现象,注意区分“死锁”。后者是系统环形等待,前者是调度策略问题)。
该算法完全未考虑作业的紧迫程度,因而不能保证紧迫性作业会被及时处理。
由于作业的长短只是根据用户所提供的估计执行时间而定的,而用户又可能会有意或无意地缩短其作业的估计运行时间,致使该算法不一定能真正做到短作业优先调度。
注意,SJF调度算法的平均等待时间、平均周转时间最少。
(3)优先级调度算法
优先级调度算法又称优先权调度算法,该算法既可以用于作业调度,也可以用于进程调度,该算法中的优先级用于描述作业运行的紧迫程度。
在作业调度中,优先级调度算法每次从后备作业队列中选择优先级最髙的一个或几个作业,将它们调入内存,分配必要的资源,创建进程并放入就绪队列。在进程调度中,优先级调度算法每次从就绪队列中选择优先级最高的进程,将处理机分配给它,使之投入运行。
根据新的更高优先级进程能否抢占正在执行的进程,可将该调度算法分为:
1)非剥夺式优先级调度算法。当某一个进程正在处理机上运行时,即使有某个更为重要或紧迫的进程进入就绪队列,仍然让正在运行的进程继续运行,直到由于其自身的原因而主动让出处理机时(任务完成或等待事件),才把处理机分配给更为重要或紧迫的进程。
2)剥夺式优先级调度算法。当一个进程正在处理机上运行时,若有某个更为重要或紧迫的进程进入就绪队列,则立即暂停正在运行的进程,将处理机分配给更重要或紧迫的进程。
而根据进程创建后其优先级是否可以改变,可以将进程优先级分为以下两种:
静态优先级。优先级是在创建进程时确定的,且在进程的整个运行期间保持不变。确 定静态优先级的主要依据有进程类型、进程对资源的要求、用户要求。
动态优先级。在进程运行过程中,根据进程情况的变化动态调整优先级。动态调整优先 级的主要依据为进程占有CPU时间的长短、就绪进程等待CPU时间的长短。
(4)高响应比优先调度算法
高响应比优先调度算法主要用于作业调度,该算法是对FCFS调度算法和SJF调度算法的一种综合平衡,同时考虑每个作业的等待时间和估计的运行时间。在每次进行作业调度时,先计算后备作业队列中每个作业的响应比,从中选出响应比最高的作业投入运行。

(5)时间片轮转调度算法
时间片轮转调度算法主要适用于分时系统。在这种算法中,系统将所有就绪进程按到达时间的先后次序排成一个队列,进程调度程序总是选择就绪队列中第一个进程执行,即先来先服务的原则,但仅能运行一个时间片,如100ms。在使用完一个时间片后,即使进程并未完成其运行,它也必须释放出(被剥夺)处理机给下一个就绪的进程,而被剥夺的进程返回到就绪队列的末尾重新排队,等候再次运行。
在时间片轮转调度算法中,时间片的大小对系统性能的影响很大。如果时间片足够大,以至于所有进程都能在一个时间片内执行完毕,则时间片轮转调度算法就退化为先来先服务调度算法。如果时间片很小,那么处理机将在进程间过于频繁切换,使处理机的开销增大,而真正用于运行用户进程的时间将减少。因此时间片的大小应选择适当。
时间片的长短通常由以下因素确定:系统的响应时间、就绪队列中的进程数目和系统的处理能力。
(6)多级反馈队列调度算法(集合了前几种算法的优点)
多级反馈队列调度算法是时间片轮转调度算法和优先级调度算法的综合和发展,如图2-5 所示。通过动态调整进程优先级和时间片大小,多级反馈队列调度算法可以兼顾多方面的系统目标。例如,为提高系统吞吐量和缩短平均周转时间而照顾短进程;为获得较好的I/O设备利用率和缩短响应时间而照顾I/O型进程;同时,也不必事先估计进程的执行时间。
多级反馈队列的优势有:
终端型作业用户:短作业优先。
短批处理作业用户:周转时间较短。
长批处理作业用户:经过前面几个队列得到部分执行,不会长期得不到处理。
5.使用setenv, export getenv putenv等环境变量相关的函数和命令
setenv函数
作用:改变或增加环境变量
相关函数getenv,putenv,unsetenv,首先要说明的是,通过此函数并不能添加或修改shell进程的环境变量,或者说通过setenv函数设置的环境变量只在本进程,而且是本次执行中有效。如果在某一次运行程序时执行了setenv函数,进程终止再次运行该程序,上次的设置是无效的,上次设置的环境变量是不能读到的。

定义:int setenv(const char *name,const char *value,int overwrite);
解释:参数value则为变量内容,参数overwrite用来决定是否要改变已存在的环境变量注释stdlib.h在Linux和windows中略不同,比如setenv函数是用在linux中的,在Windows中没有setenv函数而用putenv来代替。
函数说明:setenv函数用来改变环境变量或增加环境变量的内容,参数name为环境变量名称字符串,参数value则为变量的内容,参数overwrite用来决定是否要改变已存在的环境变量。如果没有此环境变量,则无论overwrite为何值均添加此环境变量。
返回值:若此环境变量存在,overwrite不为0时,原内容会被改为参数value所指的变量内容,当overwrite为0时,则参数会被忽略。返回值执行成功则返回0,有错误发生时,返回-1
getenv()
函数名: getenv
功 能: 从环境中取字符串,获取环境变量的值
头文件: stdlib.h
用 法:char *getenv(char *envvar);
函数说明:getenv()用来取得参数envvar环境变量的内容。参数envvar为环境变量的名称,如果该变量存在则会返回指向该内容的指针。环境变量的格式为envvar=value。getenv函数的返回值存储在一个全局二维数组里,当你再次使用getenv函数时不用担心会覆盖上次的调用结果。
返回值: 执行成功则返回指向该内容的指针,找不到符合的环境变量名称则返回NULL。如果变量存在但无关联值,它将运行成功并返回一个空字符串,即该字符的第一个字节是null。
相关函数:_wgetenv、getenv_s、_wgetenv_s
putenv
首先要说明的是,通过此函数并不能添加或修改 shell 进程的环境变量,或者说通过setenv函数设置的环境变量只在本进程,而且是本次执行中有效。如果在某一次运行程序时执行了setenv函数,进程终止后再次运行该程序,上次的设置是无效的,上次设置的环境变量是不能读到的。
putenv(改变或增加环境变量)
相关函数 getenv,setenv,unsetenv
表头文件 #include