输入
input():接收命令行下输入
1)在py2下:如果你输的是一串文字,要用引号''或者""引起来,如果是数字则不用。
2)在py3下:相当于py2的raw_input(),得到的都是字符串,而非数值
if语法
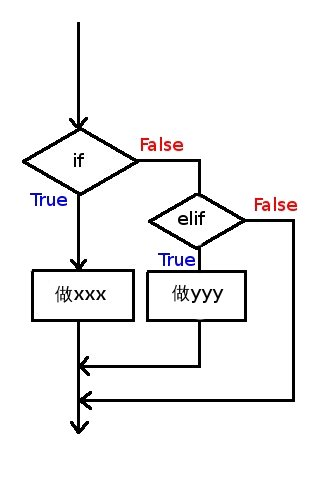
if 条件:
选择执行的语句
elif 条件:
选择执行的语句
else:
选择执行的语句
特别说明:条件后面的冒号不能少,同样必须是英文字符。
特别特别说明:if内部的语句需要有一个统一的缩进,一般用4个空格。python用这种方法替代了其他很多编程语言中的{}。你也可以选择1/2/3...个空格或者按一下tab键,但必须整个文件中都统一起来。千万不可以tab和空格混用,不然就会出现各种莫名其妙的错误。所以建议都直接用4个空格。
以缩进代替{},第一个缩进 为{,第一个不缩进为}
例:
thisIsLove = input()
if thisIsLove:
print "再转身就该勇敢留下来"
break:跳出循环
continue:进入下次循环
while语法
while 条件:
选择执行的语句
注意:循环体内的语句,缩进相同。if也是如此。
break:跳出循环
continue:进入下次循环
for循环语法
for 变量 in 序列 :
循环执行体
for i in range(1, 101):
print i
for ... in ... #for循环的本质是对一个序列中的元素进行递归
for i in range(a, b) #从a循环至b-1
for count in range(0,n) #循环n次
range(1, 101)表示从1开始,到101为止(不包括101),取其中所有的整数
示例 :
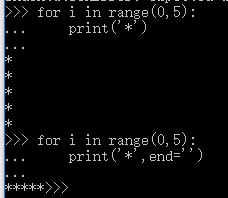
如果想让这5个*在同一行,python2的话就在print语句后面加上逗号
for i in range(0, 5):
print '*',
python3需要加上end参数:
for i in range(0, 5):
print('*', end=' ')
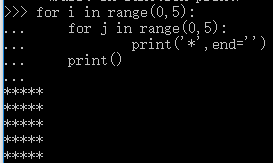
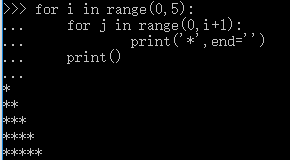
示例:
第二个print的缩进和内层的for是一样的,这表明它是外层for循环中的语句,每次i的循环中,它会执行一次。
print()没有写任何参数,是起到换行的作用
模块
通过函数,可以在程序里重用代码;通过模块,则可以重用别的程序中的代码。
模块可以理解为是一个包含了函数和变量的py文件。在你的程序中引入了某个模块,就可以使用其中的函数和变量。
1、import 模块名
import random:import语句告诉python,我们要用random模块中的内容。然后便可以使用random中的方法(调用方式“模块名.方法名”),比如:
random.randint(1, 10)
random.choice([1, 3, 5])
想知道random有哪些函数和变量,可以用dir()方法:dir(random)
2、 from 模块名 import 方法或变量名
from 模块名 import 方法或变量名 as 方法或变量别名
场景:如果只是用到模块中的一个函数或变量时
调用方式:方法名(或变量名),不需要加模块名。
例:
1)from math import pi
print(pi)
2)from math import pi as math_pi
print(math_pi)
random
from 模块名 import 方法名
from random import randint
randint产生随机数:
randint(5, 10)将会产生一个5到10之间(包括5和10)的随机整数
变量
变量命名规则:
1、必须以字母或下划线(_)开头,其余部分可以是字母、下划线(_)或数字(0-9)
2、大小写敏感
判断变量的数据类型的两种方法
一、Python中的数据类型有数字、字符串,列表、元组、字典、集合等。有两种方法判断一个变量的数据类型
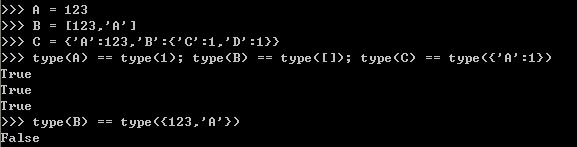
1、isinstance(变量名,类型)
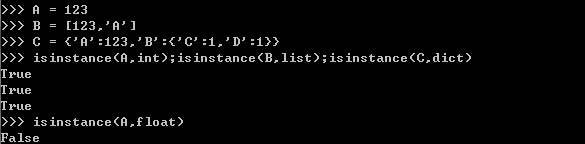
2、通过与其他已知类型的常量进行对比:type()
转义符\,三个引号(''')
\的用途:1)转义,2)在源码换行(在代码中换行,而不影响输出的结果)
在源码中换行,比如:
"this is the\
same line"
这个字符串仍然只有一行,和"this is thesame line"是一样的,只是在代码中换了行。当你要写一行很长的代码时,这个会派上用场(只是在源码中换行,实际数据不换行)。
三个引号(''')或者("""):在三个引号中,可以方便地使用单引号和双引号(不需要转义符\),并且可以直接换行(实际数据中换行)
'''
"What's your name?" I asked.
"I'm Han Meimei."
'''
字符串格式化
1、str():将数字转化为字符串
num = 18
print ('My age is' + num)
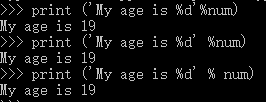
2、%:对字符串进行格式化
1)%d:替换整数,%dw会被%后面的整数替换
num=19
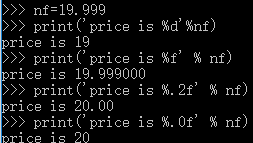
2)%f:替换小数,%.2f会保留2位小数
3)%s:替换字符串
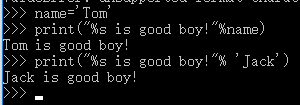
4)使用tuple元组替换多个。

类型转换
int(x) #把x转换成整数
float(x) #把x转换成浮点数
str(x) #把x转换成字符串
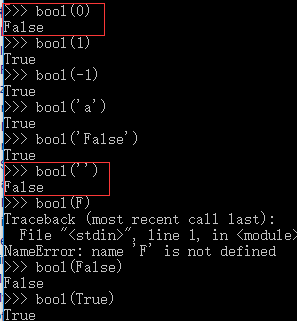
bool(x) #把x转换成bool值
在python中,其他类型转成 bool 类型时,以下值会被认为是False:
为0的数字,包括0,0.0
空字符串,包括'',""
表示空值的None
空集合,包括(),[],{}
其他的值都认为是True
None是python中的一个特殊值,表示什么都没有,它和0、空字符、False、空集合都不一样。
在if、while等条件判断语句里,判断条件会自动进行一次bool的转换。比如
a = '123'
if a:
print 'this is not a blank string'
这在编程中是很常见的一种写法。效果等同于
if bool(a) 或者 if a != ''
函数
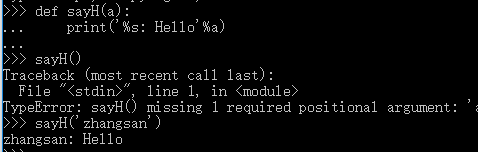
关键字def,格式如下:
def sayHello():
print 'hello world!'
return是函数的结束语句,return后面的值被作为这个函数的返回值。函数中任何地方的return被执行到的时候,这个函数就会结束。
函数参数默认值
def hello(name = 'world'):
print 'hello ' + name
以上函数,name 参数可忽略
函数的参数传递
def func(arg1, arg2):
print arg1, arg2
1、按参数位置匹配。如:func(3, 7)
2、指定形参的名称。如:func(arg2=3, arg1=7)
3、如果参数有默认值,则可只传部分参数,按位置匹配(在前)和按参数名匹配可以结合使用。如:
def func(arg1=1, arg2=2, arg3=3):
print arg1, arg2, arg3
调用:
func(2, 3, 4)
func(5, 6)
func(arg2=8)
func(arg3=9, arg1=10)
func(11, arg3=12)
4、任意数量的参数 def func(*args),把参数作为 tuple 传入函数内部。如:
def calcSum(*args):
sum = 0
for i in args:
sum += i
print sum
调用:
calcSum(1,2,3)
calcSum(123,456)
calcSum()
输出:
6
579
0
在变量前加上星号前缀(*),调用时的参数会存储在一个 tuple(元组)对象中,赋值给形参。在函数内部,需要对参数进行处理时,只要对这个 tuple 类型的形参(这里是 args)进行操作就可以了。因此,函数在定义时并不需要指明参数个数,就可以处理任意参数个数的情况。需要注意,tuple 是有序的,所以 args 中元素的顺序受到赋值时的影响。
5、func(**kargs) 把参数以键值对字典的形式传入。如:
def printAll(**kargs):
for k in kargs:
print k, ':', kargs[k]
调用:
printAll(a=1, b=2, c=3)
printAll(x=4, y=5)
输出:
a : 1
c : 3
b : 2
y : 5
x : 4
字典是无序的,所以在输出的时候,并不一定按照提供参数的顺序。同样在调用时,参数的顺序无所谓,只要对应合适的形参名就可以了。于是,采用这种参数传递的方法,可以不受参数数量、位置的限制。
6、参数调用方式混合使用。例:
def func(x, y=5, *a, **b):
print x, y, a, b
在混合使用时,首先要注意函数的写法,必须遵守先后顺序:无默认值形参,默认值形参,元组形参,字典形参。
带有默认值的形参(arg=)须在无默认值的形参(arg)之后;元组参数(*args)须在带有默认值的形参(arg=)之后;字典参数(**kargs)须在元组参数(*args)之后。可以省略某种类型的参数,但仍需保证此顺序规则。
调用时也需要遵守先后顺序 :不指定参数名,指定参数名。
指定参数名称的参数要在无指定参数名称的参数之后;不可以重复传递,即按顺序提供某参数之后,又指定名称传递。
在函数被调用时,参数的传递过程为:不指定参数名匹配,指定参数名匹配,多余的不指定参数名为元组参数,多余的指定参数名为字典参数。
1.按顺序把无指定参数的实参赋值给形参;
2.把指定参数名称(arg=v)的实参赋值给对应的形参(非元组、非字典);
3.将多余的无指定参数的实参打包成一个 tuple 传递给元组参数(*args);
4.将多余的指定参数名的实参打包成一个 dict 传递给字典参数(**kargs)。
示例:
def func(x, y=5, *a, **b):
print x, y, a, b
调用:
func(1)
func(1,2)
func(1,2,3)
func(1,2,3,4)
func(x=1)
func(x=1,y=1)
func(x=1,y=1,a=1)
func(x=1,y=1,a=1,b=1) --a=1是字典参数
func(1,y=1)
func(1,2,3,4,a=1)
func(1,2,3,4,k=1,t=2,o=3)
输出:
1 5 () {}
1 2 () {}
1 2 (3,) {}
1 2 (3, 4) {}
1 5 () {}
1 1 () {}
1 1 () {'a': 1}
1 1 () {'a': 1, 'b': 1}
1 1 () {}
1 2 (3, 4) {'a': 1}
1 2 (3, 4) {'k': 1, 't': 2, 'o': 3}
列表list
list是以[]包围、逗号分隔的一组数据,数据之间的类型可以不同。
l = [1, 1, 2, 3, 5, 8, 13]
l = [365, 'everyday', 0.618, True]
列表以for遍历: for i in l:
range(1,10)在py2中产生一个list;在py3中返回一个可以循环遍历的range对象,可以通过list()函数转换成列表。
1、以索引访问,从0开始
print(I[0])
I[0]='a'
1)如果索引为负数,则表示从后往前倒数:
l[-1]表示l中的最后一个元素。
l[-3]表示倒数第3个元素。
2)切片操作符,以:分隔的一对数字
冒号前的数字表示开始位置(从0开始),冒号后的数字表示 结束位置。[起始位置:结束位置),即包含起始位置,不包含结束位置
l = [365, 'everyday', 0.618, True]
l[1:3]得到的结果是['everyday', 0.618]
如果不指定第一个数,切片就从列表第一个元素开始。
如果不指定第二个数,就一直到最后一个元素结束。
都不指定,则返回整个列表的一个拷贝。
l[:3]
l[1:]
l[:]
切片中的数字可以为负数。
l[1:-1] 得到['everyday', 0.618]
2、向list添加元素:append()方法
I.append('xx')
3、删除list中的元素:del命令
del I[2]
list与字符串
字符串分隔成list: split()
split默认是按照空白字符(包括空格、换行符\n、制表符\t)进行分割,得到一个list。另外可以揎分割符。

list连接成字符串:join()
join()是连接符的方法,参数是list
s = ';'
li = ['apple', 'pear', 'orange']
fruit = s.join(li)
print(fruit)
得到结果'apple;pear;orange'。
';'.join(['apple', 'pear', 'orange'])
字符串的遍历与访问,与list类似
遍历
通过for...in可以遍历字符串中的每一个字符。
word = 'helloworld'
for c in word:
print c
索引访问
通过[]加索引的方式,访问字符串中的某个字符。
print word[0]
print word[-2]
切片
通过两个参数,截取一段子串,具体规则和list相同。
print word[5:7]
print word[:-5]
print word[:]
连接字符
join方法也可以对字符串使用,作用就是用连接符把字符串中的每个字符重新连接成一个新字符串。
newword = ','.join(word)
字典
基本格式是(key是键,value是值):
d = {key1 : value1, key2 : value2 }
键要注意的是:
1.键必须是唯一的;
2.键只能是简单对象,比如字符串、整数、浮点数、bool值。lis就不能作为键,但是可以作为值。
访问规则:
1、python字典中的键/值对没有顺序,无法用索引访问字典中的某一项,而是要用键来访问。
d[key]
d.get(key)
字典类的get方法是按照给定key寻找对应项,如果不存在这样的key,就返回空值None。
2、通过for...in遍历(遍历的变量中存储的是字典的键):
for name in score:
print score[name]
例:
score = {
'萧峰': 95,
'段誉': 97,
'虚竹': 89
}
改变某一项的值:score['虚竹'] = 91
增加一项(给一个新键赋值):score['慕容复'] = 88
删除一项:del score['萧峰']
新建一个空的字典:d = {}
元组
元组(tuple)也是一种序列,和list类似,只是元组中的元素在创建之后就不能被修改。
如:
postion = (1, 2)
geeks = ('Sheldon', 'Leonard', 'Rajesh', 'Howard')
都是元组的实例。它有和list同样的索引、切片、遍历等操作
例:
def get_pos(n):
return (n/2, n*2)
得到这个函数的返回值有两种形式,一种是根据返回值元组中元素的个数提供变量:
x, y = get_pos(50)
print x
print y
还有一种方法是用一个变量记录返回的元组:
pos = get_pos(50)
print pos[0]
print pos[1]
异常处理 try ... except ...
try:
f = file('non-exist.txt')
print 'File opened!'
f.close()
except:
print 'File not exists.'
文件操作
打开文件:f = open('data.txt')
open('文件名')
文件名可以用文件的完整路径,也可以是相对(代码的)路径。
python默认是以只读模式打开文件。如果想要写入内容,在打开文件的时候需要指定打开模式为写入:f = open('output.txt', 'w')
- 'w'就是writing,以这种模式打开文件,原来文件中的内容会被你新写入的内容覆盖掉,如果文件不存在,会自动创建文件。
- 不加参数时,open为你默认为'r',reading,只读模式,文件必须存在,否则引发异常。
- 还有一种模式是'a',appending。它也是一种写入模式,但你写入的内容不会覆盖之前的内容,而是添加到文件中。
注:py2里可以使用 open 或 file 方法打开文件,py3 只能使用 open
读取文件:data = f.read()
read() #把文件内所有内容读进一个字符串中
readline() #读取一行内容
readlines() #把内容按行读取至一个list中
写入文件:f.write('a string you want to write')
必须以w或a模式打开文件,才能写入
关闭文件:f.close()
pass语句
pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句。
实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 输出 Python 的每个字母 for letter in 'Python': if letter == 'h': pass print '这是 pass 块' print '当前字母 :', letter print "Good bye!"
以上实例执行结果:
当前字母 : P
当前字母 : y 当前字母 : t 这是 pass 块 当前字母 : h 当前字母 : o 当前字母 : n Good bye!