所有的说明大概在主题说明里面都有。

我毛华望QQ849886241,个人博客http://blog.csdn.net/my_share
企业视图:是一种企业数据库,
必须在某个 Clementine 服务器主机上定义同名的 ODBC 数据源。
数据库:
数据库源节点可用于使用 ODBC(开放数据库连接)从多种其他数据包中导入数据,这些数据包包括 Microsoft SQL Server、DB2、Oracle 等。
可变文件:可以输入的文件类型很多,但是像图片这种就不支持啦,估计转变成2进制就支持啦。
固定文件:
可以使用固定文件节点从固定字段文本文件(其字段没有被分隔,但开始位置相同且长度固定)中导入数据。机器生成的数据或遗存数据通常以固定字段格式存储。使用固定文件节点的“文件”选项卡,可以轻松地指定数据中列的位置和长度。也就是说机器生产的txt文件数据。
SPSS文件:软件自带的数据文件就是这种.sav文件。
dimensione:
SPSS 的 Dimensions 软件保存文件。
可从平面、表格 VDATA 格式或层级 HDATA 格式中的源读取调查数据。
SAS文件:
适用于 Windows/OS2 的 SAS (
.sd2
)
UNIX 的 SAS (
.ssd
)
SAS 传输文件 (
.tpt
)
SAS 版本 7/8/9 (
.sas7bdat
)
excel:适用于windows等系统.xls文件
用户输入:测试的时候,自己写的特定的数据。方便调试。也
可以从流的任何非终端节点生成用户输入节点。

选择:
可以使用选择节点,根据某个特定的条件
选择或丢弃数据流中的部分记录。双击后,可以用函数构建器来完成选择函数。选出前段特定的数据。
样本:另一个说法,叫抽样节点。顾名思义就是从整个样本中抽出特定的部分。随机抽取等。选择呢?是对数据特征选择。抽样呢?是对整个数据集进行的切割。
平衡:
平衡是通过复制记录,然后根据指定的条件丢弃记录完成执行的。
例如,假设某个数据集只有两个值(
low
或
high
),并且 90% 的观测值为
low
,而只有 10% 的观测值为
high
。很多建模技术处理此类偏置数据都有困难,因为它们倾向于只研究这些
low
的结果,而忽略
high
的结果(因为这些结果数目极少)。
汇总:数据合成,数据量减少,减少的方法也是数学方法,比如说求和。选择是丢失数据,汇总是合成数据。
RFM 汇总:
通过近因、频数、货币 (RFM) 汇总节点,您可以利用客户的历史交易数据,去除所有无用的数据,然后将他们的所有剩余交易数据合并到一行并以唯一的客户 ID 作为关键字,从而列出他们最后一次与您交易的时间(近因),交易的次数(频数)以及这些交易的总值(货币)。
排序:只有两个选择升序和降序。
合并:
采用多个输入记录,然后创建一个包含全部或其中部分输入字段的输出记录。一般是两个文件的合并。
追加:是两个一样的数据表格,合成一个的过程。
区分:
删除重复的记录,方法是,将第一个区分记录传递到数据流,或丢弃第一个记录而将任何重复记录传递到数据流。

类型:描述数据一些属性情况,指明输入和输出,是否有数据缺失等。
过滤:对数据的某一个属性进行剥离分析,剥离那些不太重要的属性。
导出:导出符合要求的记录,导出条件为数学表达式。
整体:大概就是一个字段,让多个模型调用的过程。
填充:
替换字段值和更改存储类型。您可以选择基于指定的 CLEM 条件(如
@BLANK(FIELD)
)替换值。或者,也可以选择将所有空值或 Null 值替换为特定值。
匿名化:将一些敏感性数据转变成和成型数据,或者字符表示的过程。
重新分类:从字面理解就可以了,从两个数据属性中,提取出一类,或者两个属性的数据,重新拆解分类。
分箱:
根据一个或多个现有数值范围字段的值自动创建新的集合字段,
例如,可以将收入水平字段转换为包含若干等宽收入组的新的分类字段
RFM分析:
通过近因、频数和货币 (RFM) 分析节点,您可以检查客户最近一次购买您产品或服务的时间(近因)、客户购买的频率(频数)以及客户支付的所有交易金额(货币),确定可能成为最佳客户的数量。(没懂)
分区:把数据分出两个区,训练区和测试区。
设为标志:为数据中的某个属性数据,设定标志。比如说,血压就把高的标志出来,作为提醒。
重新结构化:
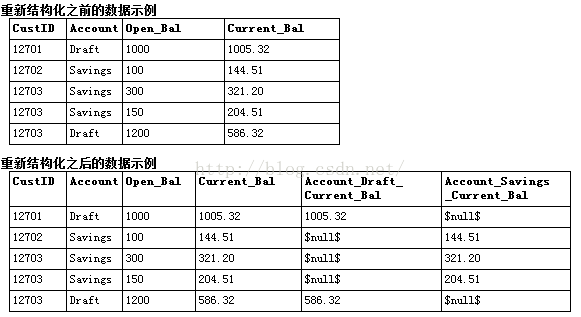
转置:
默认情况下,列为字段,而行为记录或观测值。如有必要,可使用转置节点交换行和列中的数据,使字段变为记录、记录变为字段。
时间区间:
使用时间区间节点,可以为用于时间序列建模节点或时间散点图节点的时间序列数据指定间隔并生成标签,以便于估计或预测。支持全部范围的时间间隔,从秒到年。
历史:好像是从整个时间顺序中的数据集里面,分段落选取数据。
spss转换:
SPSS 命令语法完成数据变换。这样便有可能完成 Clementine 不支持的若干变换,并实现复杂多步变换的自动化
字段重排:
使用字段重排节点,可以定义用于显示下游字段的自然顺序。此顺序将影响字段在多个位置的显示方式,如表格、列表和字段选择器

图形板:
通过图形板节点,您可以从单个节点上的许多不同图形输出(分布图、饼图、直方图、散点图和热图等)中进行选择。
图:二维直角坐标系显示图。
分布:

直方图:
集合:
多重散点图:

网络:
时间散点图:
评估:

表:按照excel的表格形式输出的。
自定义表格:只是可以自己设计的表格。(和前面没有多少差别)
矩阵:
它最常用于显示两个分类字段、之间的关系(这种矩阵一般只对比两个变量)
分析:文本报告输出,里面有比较出来的情况和分析评定等。
数据审校:
“审核”选项卡显示所有字段的缩略图、存储图标以及统计量,而“质量”选项卡显示有关离群值、极值和缺失值的信息。总体上是来评审数据质量的。
变换:
对一行一列的数据进行三角变换,指数变化,逆变换等。
统计量:是数据里面的平均数,中卫数,总数,众数,方差。
均值:字段或者整个数据集的平均。
报告:是文本报告,需要编程来描述报告的形态。
设置全局节点:
设置全局节点扫描数据并计算可在 CLEM 表达式中使用的汇总值。(不是输出,好像是选择字段)
spss输出:以文本的方式输出一些报告。不规则表格等。

这些是输出节点:差不多和输入是一样的。
数据库:导出的文件是以数据库为格式的,
平面文件:导出的文件是以txt格式的文件。
SPSS导出:导出的是.sav格式的文件。、
dimensions:
SAS导出:
excel:
发布者:很多格式都有excel,spss只是结构不可以控制。
这里唯独缺少了建模,也就是最重要的机器学习模块。其实这些现在写出来的都是机器学习模块的辅助工具,选择哪种也没有特别的讲究,知道就可以了。
可是建模就不一样了,对数据的情况呀,算法本身的特点都需要了解。所以不是一时半会能明白的。
后面就是对机器学习算法的学习了。