近期一直在从事一些paas平台能力搭建的工作,主要是进行监控能力的搭建,最近工作有了些许成果,用一篇文章记录一下自己这阶段的工作与学习,并简单介绍一下监控能力的一些总结。
监控的能力旨在提高平台之上应用的服务质量,首先最重要的是确定监控的数据模型,也就是要确定使用哪些监控指标去衡量一个系统的服务质量,比如说这个系统的访问量(counter),访问一个服务的时长(latency),访问的时候有多少次报错(error)等等,然后去思考如何去拿到这些信息,去进行逻辑的计算加工,进而得出能够反映一个系统优良的监控指标。
Monitor-first-version
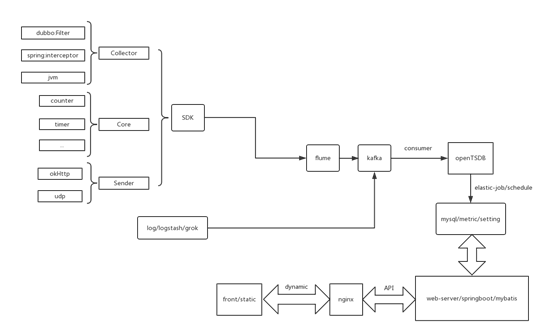
在第一版的监控设计中,我们采用了SDK依赖引入的的方式,通过自定义注解@monitor-config自定义注解将必要的组件通过DI注入到IOC容器中,其实本质的原理是使用AOP切面编程,给应用程序加一个interceptor,但是针对不同的应用架构这个interceptor不同,无论是request还是response我们都可以拦截到,这样我们就可以对这个应用系统的整体有整体的把控,比如加一个counter计数器,每有一个request,counter++;加一个timer计时器,计算一个请求和相应之间的时间等等,然后将这些数据进行一些统计学的算法进行合理的计算,发送出来,这就在interceptor内部形成了一条完整的应用链。
最初的时候我们上述的功能都是写在一起的,后来我们对程序进行了解耦,将其分为collector,core,sender三部分,分别进行数据的收集,计算和发送,最初的发送方式是使用udp,但是后来发现udp的连接因为内部网络原因并不稳定,于是又扩展了http发送方式。数据通过http的方式发送到了flume中,进行一些简单的运算逻辑将数据输送kafka中,在flume内部集成kafka的API,这样你就不需要自己去定义一个kafka producer了,并且flume的性能也不错,同时也减小了SDK的大小,毕竟如果你想直接将数据输送到kafka,producer的逻辑就要写在SDK中了。另外一部分,因为一些项目的历史原因我们没法对其进行SDK方式的监控(因为有的项目用的jdk1.5,跟1.6及以上有很大不同,我们并不想开发两套SDK),于是我们用logstash进行一些项目日志的收集,通过定义他的grok表达式对日志文件信息进行筛选和处理,然后输送到kafka。
在第一版中,监控数据的存储是基于openTSDB--一款时序数据库,算是Hbase的一款应用,以及mysql(因为业务量并不是很大,mysql还是很不错的)。他将监控指标数据以时间点的维度记录下来,这些数据是通过kafka consumer去消费kafka的数据然后组装成openTSDB我们自己定义的数据类型进行传入。
OpenTSDB提供了自己的可视化界面,以及javaAPI的查询语句,于是我们使用elastic-job框架写了一个定时任务,每小时、每天、每月去拉取openTSDB中的时间点数据进行聚合存储到mysql中,剩下的事情就简单多了,用监控数据去做你想做的事情就好了,web-server使用的springboot整合mybatis去操作mysql中数据,包括项目信息,机器信息,监控指标数据等等,web-server对外提供了数据显示的API供前端调用,至于前端采用的是动静分离的处理方法,静态资源可以从front中读取,动态资源通过nginx代理范文web-server的API就可以。同时,当业务量更大时,可以通过nginx达到负载均衡的作用。
问题与挑战:
第一版的系统在业务量逐渐增大之后,我们就发现了一些问题:
- openTSDB这个数据库的性能无法承受较大的业务量,在我们采用读写分离的优化后,主从节点也并不是非常稳定,并且需要有人专门维护,同时,我们也发现了一款较为成熟的监控软件—prometheus,提供更多扩展的应用。
- 接入方式的单一让我们没有办法适应所有的系统,有些系统是通过将war包扔进tomcat来运行的,他并不适用于SDK和日志的监控方式,并且我们发现logstash太重了,在整个架构中不够轻量。
- 监控的配置信息和监控数据都是存储在mysql中的,没有一个独立的权限控制服务让我们维护系统信息时很吃力,于是我们想把配置和权限信息抽出来,这样只需要一个可以查询监控数据的地方就可以,mysql这种关系型数据对于只查询来说太重,也太慢,不如使用NoSql型数据库的表现好。
- 监控平台的能力包含里应用监控,机器监控,告警,小程序等等,但是这些应用并没有一个统一的入口。
针对以上问题,我们对第一版的监控进行了改进和扩展。
Monitor-second-version
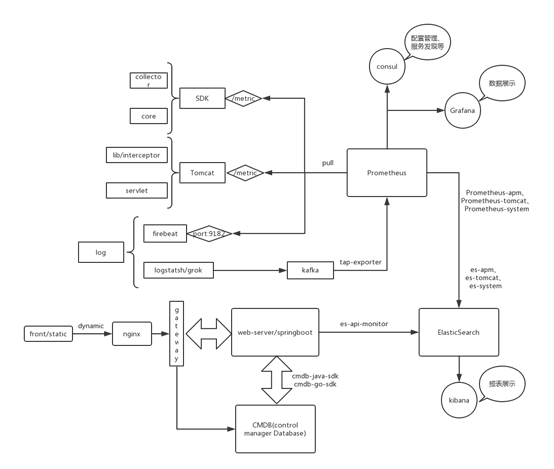
第二版的监控使用成熟的监控产品prometheus取代了openTSDB作为整个监控的核心组件,但是prometheus并不是一个持久化存储的地方,只能保存两周的监控数据(后来将其增大到1个月),我们就需要一个将监控数据持久化存储的地方,而NoSql型数据库要更好,于是我们选用了ElasticSearch做持久化存储。
监控数据的获取模型在第一版中是一个push模型,是应用程序主动上报,但是在第二版中,我们选用prometheus的poll模型,由prometheus去指定的地方拉取监控数据,于是我们改进了SDK的方式,将sender发送监控数据的方式转变成监控数据放在一个指定接口上,用prometheus定期去该位置上拉取监控信息。同时,针对war包跑在tomcat中的系统,我们扩展了tomcat方式的监控,在lib中因为必要的jar加载组件,其实本质也是一个拦截器,然后加了一个servlet将监控数据从内存中取出然后暴露出去,例如用/metric目录暴露。同时,也增加了一种日志监控方式,毕竟logstash太重了,我们选用firebeat去收集日志,他的输出方式可以直接选用prometheus,只需要给prometheus暴露一个端口即可。
但是这样的poll模型有个问题,就是prometheus需要知道去哪里拉取监控数据,原始的时候是使用yml的方式来配置,但是这样我们需要去一直维护一个yml有些麻烦,于是我们引入了consul来做配置管理和服务发现,prometheus会从consul中获取配置信息,然后到指定的端口或者路径拉取收集的监控信息。同时,之前的数据一直存在kafka中,我们需要将历史数据也放到prometheus中,而且有些项目仍然会使用着第一版的方式,我们并不能丢掉kafka中的数据,所以写了一个tap-exporter专门将kafka中的数据转成prometheus的数据格式,传到prometheus中。
剩下的事情,需要做监控数据的持久化存储,利用prometheus和elasticsearch的一些api做数据的转储,web-server也进行权限配置和监控数据的分离,将配置信息和权限管理信息单独拿出来配置在CMDB中,web-server从CMDB中读写取项目、机器等信息,从elasticsearch读取监控指标信息,当然CMDB和elasticsearch的查询都是重新封装过得,这样通用一些。我们还在web-server前边加了一层gateway,因为监控平台的能力包含了应用监控,机器监控,告警,移动端等等,想将监控做的产品化,没有一个同意的入口会出现数据不对等的问题,所以gateway是所有应用的入口,对于web-server而言,权限的控制是在gateway中做的,通过从cmdb中获取权限信息,进而对后台进行权限控制。
另外有一些用于展示的扩展,比如prometheus的插件Grafana可以做更炫酷的数据展示,elasticsearch的插件Kibana可以做更直观的报表展示等。
Extend
- 后来我们对监控增加了扩展了一些指标,例如应用的PV/UV,可用性,应用重启次数等等。其中的可用性指标是基于consul开发的拨测功能,consul除了进行配置管理和服务发现,还有健康检查功能(check),可以在consul中配置一些项目重要站点的check信息,定时访问一个站点,prometheus也会定时去拉取consul健康检查返回的结果,统计他的可用率,或者在站点不可用的时候进行及时的告警。
- 监控平台的功能远不如此,还有机器监控和告警功能。机器监控是通过ansiable在机器上自动安装脚本收集cpu,内存,磁盘的信息,放到指定端口,由prometheus定时去拉取这些信息。而告警功能则是制定了一些告警规则,通过监控的数据去进行相应的告警,由于告警是一个单独的模块,我并不是很了解,在这里就不在赘述,如果后续进行告警方面的工作,也会记录下来。