该文章是根据多个学习视频和各个优秀博客和自己的一些总结,内容如有侵犯,务必私聊。
上次我们讲到了-遗传算法。这次我们会分享另一个学习大自然规律来的算法--粒子群优化,一个学习鸟类捕食的优化算法。
一、先来讲个故事:如果在一片大森林里面,可能藏有若干的食物。有一群刚来到的鸟,它们都还不知道食物在哪里,但是他们会感应得到食物大概在哪里。然后离最近的小鸟会广播出去,自己的位置。然后整个鸟类群都会改变方向,沿着最近的那只小鸟的方向,以它们自己的速度飞过去。然后不断重复,直到他们找到食物为止。(好大公无私~~)
二、那么粒子群是怎么模仿的呢?
pso会在可行解空间中初始化一群粒子,每个粒子都代表极值优化问题的一个潜在最优解。用位置、速度和适应度三项指标表示该粒子的特征。
粒子在解空间中运动,通过根据个体极值Pbest和群体极值Gbest更新个体的位置。个体极值Pbest是指所经历位置中,计算得到的适应度值最优位置。群体极值Gbest是指种群中的所有粒子搜索到的适应度最优值。
粒子每更新一次位置,就计算一次适应度值,并且通过比较新粒子的适应度值和个体极值、群体极值的适应度值更新个体极值Pbest和Gbest的位置。
三、那么位置和速度是怎么样更新的呢?
首先假设在一个D维空间中,有N个粒子。
粒子i的位置:x[i]=(x[i1],x[i2],...x[iD]),将xi带入适应函数f(xi)求适应值。
粒子速度:Vi=(V[i1],V[i2],...V[iD])
最好的个体位置:Pbest[i]=(p[i1],p[i2]...p[iD])
种群所经历过最好的位置:Gbest[i]=(g[1],g[2]...g[D])
通常,在第d(1<=d<=D)维的位置变化范围限定在[xmin[d],xmax[d]]内,速度[vmin[d],vmax[d]]内。
更新的公式:
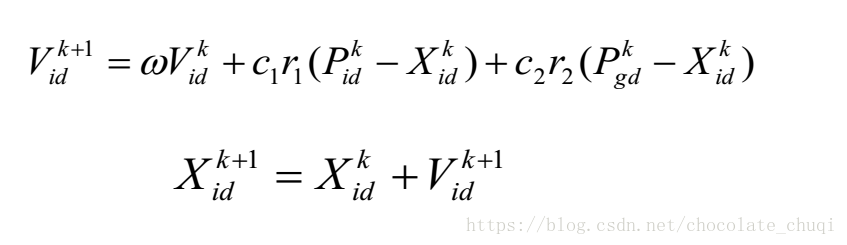
四、粒子群算法的构成要素
1.群体大小m
m是一个整形参数
m很小:会陷入局部最优的可能性大大增加
m很大:pso的优化能力很好,但是其实当群体数目增长到一定水平时,再增长将不会有显著作用,反倒会拉慢运算。
2.权重因子中的惯性因子w
惯性权重w体现的是粒子继承先前的速度的能力,shi.Y最先将惯性权重w引入到pso算法中,并分析指出一个较大的惯性权值有利于全局搜索,而一个较小的权值则更利于局部搜索。为了更好地平衡算法的全局搜索以及局部搜索能力,shi.Y提出了线性递减惯性权重LDIW(linear Decreasing Inertia Weight),公式如下:
W(k)=Wstart-(Wstart-Wend)(Tmax-k)*(Tmax^-1)
其中Wstart为初始惯性权重,Wend为迭代至最大次数时的惯性权重。k为当前迭代数,Tmax为最大迭代数。一般来说,惯性权值取值为Wstart=0.9,Wend=0.4时算法性能最好。就开始先用较大的惯性权重去满足全局搜索能力,后用较小的惯性权重去满足局部搜索能力。但是,线性惯性权重只是一种经验做法,常用的惯性权重的选择还包括如下几种:
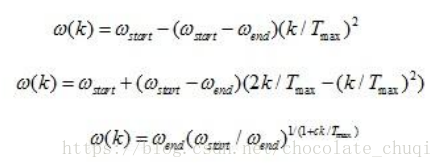
为什么大的惯性权重会比较利于全局呢?因为它受极值影响会比较小,比较自由去选择
为什么小的惯性权重会比较利于局部呢?因为会受到极值的影响比较大,会慢慢向极值靠拢
再者 w=1,是基本粒子群算法;
w=0,就失去了粒子本身的速度记忆。
3.学习因子c1,c2

4.最大速度 Vm
作用:在于维护算法的搜索能力与开发能力的平衡。
1.Vm较大时,搜索能力增强,但是容易飞过头,错过最优解
2.Vm较小时,开发能力较强,但是荣誉陷入局部出不来
所以一般取值为每维变量变化范围的10%-20%
5.领域的拓扑结构
粒子群算法的邻域拓扑结构包括两种:1.将群体内所有个体都作为粒子的邻域;2.只将部分个体作为离子的邻域
我们根据这个拓扑结构,把粒子群算法分为:1.全体粒子群算法;2.局部粒子群算法
邻域拓扑结构决定群体历史最优位置。
全局模型 |
名称 |
局部模型 |
粒子自己历史最优值 |
Pbest |
粒子自己历史最优值 |
粒子群体的全局最优值 |
Gbest |
粒子邻域内粒子的最优值 |
收敛速度快 |
优点 |
不容易陷入局部最优解 |
容易陷入局部最优解 |
缺点 |
收敛速度慢 |
6.停止准则
1.最大迭代步数
2.可接受满意解
7.粒子空间的初始化
较好的初始结果,可以大大缩减收敛时间。
五、粒子群VS遗传
相同点:1.都需要种群随机初始化
2.适应度函数值与目标最优解之间的映射
不同点:1.PSO算法没有选择、交叉、变异等操作算子
2.PSO有记忆的功能
3.信息共享机制不同,遗传算法是互相共享信息,整个种群的移动是比较均匀地向最优区域移动,而在pso中,只有Gbest或Pbest给出信息给其他粒子,属于单向的信息流动,整个搜索更新过程是跟随当前最优解的过程。因此一般情况下,PSO收敛速度更快。
(遗传就是有50个人,选择20个比较好的,然后交叉他们基因,再改造一下他们基因。然后再选出10个,重复到最好)
(粒子群就是有50个人,选择最好的,广播出来,一起走向那个美好的世界,不会淘汰人)
虽然说,粒子群算法比较简单,没有了选择、交叉、变异,也因为这样容易陷入局部最优,后期可以结合一些遗传算法的东西,进行改进。
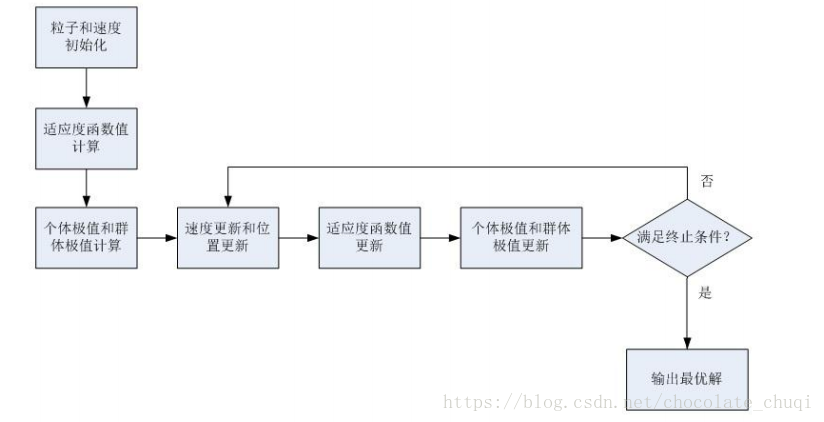
六、流程图
七、代码