缓冲区(Buffer)
缓冲区(Buffer)就是在内存中预留指定大小的存储空间用来对输入/输出(I/O)的数据作临时存储,这部分预留的内存空间就叫做缓冲区:
使用缓冲区有这么两个好处:
1、减少实际的物理读写次数
2、缓冲区在创建时就被分配内存,这块内存区域一直被重用,可以减少动态分配和回收内存的次数
举个简单的例子,比如A地有1w块砖要搬到B地
由于没有工具(缓冲区),我们一次只能搬一本,那么就要搬1w次(实际读写次数)
如果A,B两地距离很远的话(IO性能消耗),那么性能消耗将会很大
但是要是此时我们有辆大卡车(缓冲区),一次可运5000本,那么2次就够了
相比之前,性能肯定是大大提高了。
而且一般在实际过程中,我们一般是先将文件读入内存,再从内存写出到别的地方
这样在输入输出过程中我们都可以用缓存来提升IO性能。
所以,buffer在IO中很重要。在旧I/O类库中(相对java.nio包)中的BufferedInputStream、BufferedOutputStream、BufferedReader和BufferedWriter在其实现中都运用了缓冲区。java.nio包公开了Buffer API,使得Java程序可以直接控制和运用缓冲区。
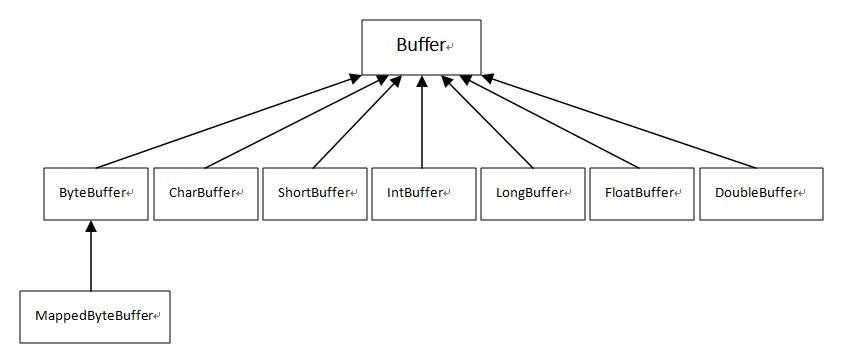
在Java NIO中,缓冲区的作用也是用来临时存储数据,可以理解为是I/O操作中数据的中转站。缓冲区直接为通道(Channel)服务,写入数据到通道或从通道读取数据,这样的操利用缓冲区数据来传递就可以达到对数据高效处理的目的。在NIO中主要有八种缓冲区类(其中MappedByteBuffer是专门用于内存映射的一种ByteBuffer):
Fields
所有缓冲区都有4个属性:capacity、limit、position、mark,并遵循:mark <= position <= limit <= capacity,下表格是对着4个属性的解释:
属性 描述| Capacity | 容量,即可以容纳的最大数据量;在缓冲区创建时被设定并且不能改变 |
| Limit | 表示缓冲区的当前终点,不能对缓冲区超过极限的位置进行读写操作。且极限是可以修改的 |
| Position | 位置,下一个要被读或写的元素的索引,每次读写缓冲区数据时都会改变改值,为下次读写作准备 |
| Mark | 标记,调用mark()来设置mark=position,再调用reset()可以让position恢复到标记的位置 |
Methods
1、实例化
java.nio.Buffer类是一个抽象类,不能被实例化。Buffer类的直接子类,如ByteBuffer等也是抽象类,所以也不能被实例化。
但是ByteBuffer类提供了4个静态工厂方法来获得ByteBuffer的实例:
方法 描述| allocate(int capacity) | 从堆空间中分配一个容量大小为capacity的byte数组作为缓冲区的byte数据存储器 |
| allocateDirect(int capacity) | 是不使用JVM堆栈而是通过操作系统来创建内存块用作缓冲区,它与当前操作系统能够更好的耦合,因此能进一步提高I/O操作速度。但是分配直接缓冲区的系统开销很大,因此只有在缓冲区较大并长期存在,或者需要经常重用时,才使用这种缓冲区 |
| wrap(byte[] array) | 这个缓冲区的数据会存放在byte数组中,bytes数组或buff缓冲区任何一方中数据的改动都会影响另一方。其实ByteBuffer底层本来就有一个bytes数组负责来保存buffer缓冲区中的数据,通过allocate方法系统会帮你构造一个byte数组 |
| wrap(byte[] array, int offset, int length) |
在上一个方法的基础上可以指定偏移量和长度,这个offset也就是包装后byteBuffer的position,而length呢就是limit-position的大小,从而我们可以得到limit的位置为length+position(offset) |
我写了这几个方法的测试方法,大家可以运行起来更容易理解
public static void main(String args[]) throws FileNotFoundException {
System.out.println("----------Test allocate--------");
System.out.println("before alocate:"
+ Runtime.getRuntime().freeMemory());
// 如果分配的内存过小,调用Runtime.getRuntime().freeMemory()大小不会变化?
// 要超过多少内存大小JVM才能感觉到?
ByteBuffer buffer = ByteBuffer.allocate(102400);
System.out.println("buffer = " + buffer);
System.out.println("after alocate:"
+ Runtime.getRuntime().freeMemory());
// 这部分直接用的系统内存,所以对JVM的内存没有影响
ByteBuffer directBuffer = ByteBuffer.allocateDirect(102400);
System.out.println("directBuffer = " + directBuffer);
System.out.println("after direct alocate:"
+ Runtime.getRuntime().freeMemory());
System.out.println("----------Test wrap--------");
byte[] bytes = new byte[32];
buffer = ByteBuffer.wrap(bytes);
System.out.println(buffer);
buffer = ByteBuffer.wrap(bytes, 10, 10);
System.out.println(buffer);
} 2、另外一些常用的方法
方法 描述| limit(), limit(10)等 | 其中读取和设置这4个属性的方法的命名和jQuery中的val(),val(10)类似,一个负责get,一个负责set |
| reset() | 把position设置成mark的值,相当于之前做过一个标记,现在要退回到之前标记的地方 |
| clear() | position = 0;limit = capacity;mark = -1; 有点初始化的味道,但是并不影响底层byte数组的内容 |
| flip() | limit = position;position = 0;mark = -1; 翻转,也就是让flip之后的position到limit这块区域变成之前的0到position这块,翻转就是将一个处于存数据状态的缓冲区变为一个处于准备取数据的状态 |
| rewind() | 把position设为0,mark设为-1,不改变limit的值 |
| remaining() | return limit - position;返回limit和position之间相对位置差 |
| hasRemaining() | return position < limit返回是否还有未读内容 |
| compact() | 把从position到limit中的内容移到0到limit-position的区域内,position和limit的取值也分别变成limit-position、capacity。如果先将positon设置到limit,再compact,那么相当于clear() |
| get() | 相对读,从position位置读取一个byte,并将position+1,为下次读写作准备 |
| get(int index) | 绝对读,读取byteBuffer底层的bytes中下标为index的byte,不改变position |
| get(byte[] dst, int offset, int length) | 从position位置开始相对读,读length个byte,并写入dst下标从offset到offset+length的区域 |
| put(byte b) | 相对写,向position的位置写入一个byte,并将postion+1,为下次读写作准备 |
| put(int index, byte b) | 绝对写,向byteBuffer底层的bytes中下标为index的位置插入byte b,不改变position |
| put(ByteBuffer src) | 用相对写,把src中可读的部分(也就是position到limit)写入此byteBuffer |
| put(byte[] src, int offset, int length) | 从src数组中的offset到offset+length区域读取数据并使用相对写写入此byteBuffer |
以下为一些测试方法:
public static void main(String args[]){
System.out.println("--------Test reset----------");
buffer.clear();
buffer.position(5);
buffer.mark();
buffer.position(10);
System.out.println("before reset:" + buffer);
buffer.reset();
System.out.println("after reset:" + buffer);
System.out.println("--------Test rewind--------");
buffer.clear();
buffer.position(10);
buffer.limit(15);
System.out.println("before rewind:" + buffer);
buffer.rewind();
System.out.println("before rewind:" + buffer);
System.out.println("--------Test compact--------");
buffer.clear();
buffer.put("abcd".getBytes());
System.out.println("before compact:" + buffer);
System.out.println(new String(buffer.array()));
buffer.flip();
System.out.println("after flip:" + buffer);
System.out.println((char) buffer.get());
System.out.println((char) buffer.get());
System.out.println((char) buffer.get());
System.out.println("after three gets:" + buffer);
System.out.println("\t" + new String(buffer.array()));
buffer.compact();
System.out.println("after compact:" + buffer);
System.out.println("\t" + new String(buffer.array()));
System.out.println("------Test get-------------");
buffer = ByteBuffer.allocate(32);
buffer.put((byte) 'a').put((byte) 'b').put((byte) 'c').put((byte) 'd')
.put((byte) 'e').put((byte) 'f');
System.out.println("before flip()" + buffer);
// 转换为读取模式
buffer.flip();
System.out.println("before get():" + buffer);
System.out.println((char) buffer.get());
System.out.println("after get():" + buffer);
// get(index)不影响position的值
System.out.println((char) buffer.get(2));
System.out.println("after get(index):" + buffer);
byte[] dst = new byte[10];
buffer.get(dst, 0, 2);
System.out.println("after get(dst, 0, 2):" + buffer);
System.out.println("\t dst:" + new String(dst));
System.out.println("buffer now is:" + buffer);
System.out.println("\t" + new String(buffer.array()));
System.out.println("--------Test put-------");
ByteBuffer bb = ByteBuffer.allocate(32);
System.out.println("before put(byte):" + bb);
System.out.println("after put(byte):" + bb.put((byte) 'z'));
System.out.println("\t" + bb.put(2, (byte) 'c'));
// put(2,(byte) 'c')不改变position的位置
System.out.println("after put(2,(byte) 'c'):" + bb);
System.out.println("\t" + new String(bb.array()));
// 这里的buffer是 abcdef[pos=3 lim=6 cap=32]
bb.put(buffer);
System.out.println("after put(buffer):" + bb);
System.out.println("\t" + new String(bb.array()));
} buffer order(大端模式,小端模式,中端模式)
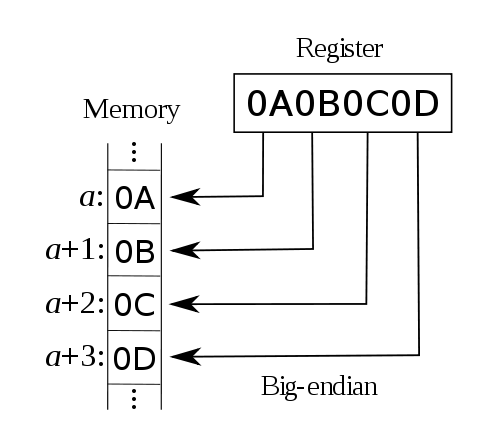
在一个32位的CPU中“字长”为32个bit,也就是4个byte。在这样的CPU中,总是以4字节对齐的方式来读取或写入内存,那么同样这4个字节的数据是以什么顺序保存在内存中的呢?例如,
现在我们要向内存地址为a的地方写入数据0x0A0B0C0D,那么这4个字节分别落在哪个地址的内存上呢?这就涉及到字节序的问题了。
每个数据都有所谓的“有效位(significant byte)”,它的意思是“表示这个数据所用的字节”。例如一个32位整数,它的有效位就是4个字节。而对于0x0A0B0C0D来说,它的有效位从高到低便是0A、0B、0C及0D——这里您可以把它作为一个256进制的数来看(相对于我们平时所用的10进制数)。
而所谓大字节序(big endian),便是指其“最高有效位(most significant byte)”落在低地址上的存储方式。例如像地址a写入0x0A0B0C0D之后,在内存中的数据便是:
而对于小字节序(little endian)来说就正好相反了,它把“最低有效位(least significant byte)”放在低地址上。例如:
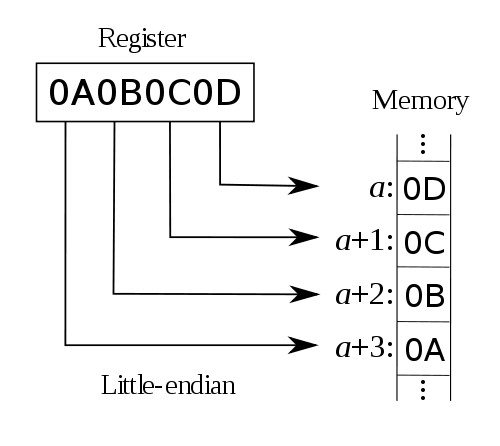
对于我们常用的CPU架构,如Intel,AMD的CPU使用的都是小字节序,而例如Mac OS以前所使用的Power PC使用的便是大字节序(不过现在Mac OS也使用Intel的CPU了)。此外,除了大字节序和小字节序之外,还有一种很少见的中字节序(middle endian),它会以2143的方式来保存数据(相对于大字节序的1234及小字节序的4321)。
在java.nio中,字节顺序由ByteOrder类封装。package java.nio;
public final class ByteOrder
{
public static final ByteOrder BIG_ENDIAN
public static final ByteOrder LITTLE_ENDIAN
public static ByteOrder nativeOrder( )
public String toString( )
}ByteOrder类定义了决定从缓冲区中存储或检索多字节数值时使用哪一字节顺序的常量。这个类的作用就像一个类型安全的枚举。它定
义了以其本身实例预初始化的两个public区域。只有这两个ByteOrder实例总是存在于JVM中,因此它们可以通过使用--操作符进行比
较。如果您需要知道JVM运行的硬件平台的固有字节顺序,请调用静态类函数nativeOrder()。它将返回两个已确定常量中的一个。调用
toString()将返回一个包含两个文字字符串BIG_ENDIAN或者LITTLE_ENDIAN之一的String。
假设一个叫buffer的ByteBuffer对象处于下图的状态: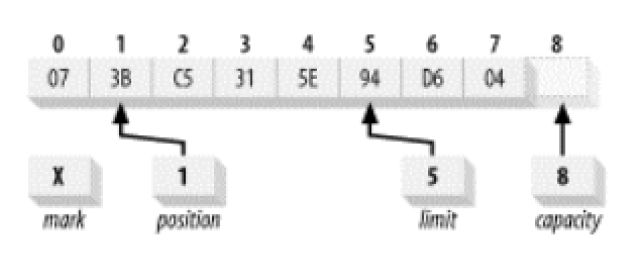
这段代码:
int value = buffer.getInt( );
会返回一个由缓冲区中位置1-4的byte数据值组成的int型变量的值。实际的返回值取决于缓冲区的当前的比特排序(byte-order)设置。
更具体的写法是:
int value = buffer.order (ByteOrder.BIG_ENDIAN).getInt( );
这将会返回值0x3BC5315E,
同时:
int value = buffer.order (ByteOrder.LITTLE_ENDIAN).getInt( );
返回值0x5E31C53B。
方法详细
1、public static ByteBuffer allocateDirect(int capacity) 分配新的直接字节缓冲区。 新缓冲区的位置将为零,其界限将为其容量,其标记是不确定的。无论它是否具有底层实现数组,其标记都是不确定的。
参数:capacity - 新缓冲区的容量,以字节为单位
返回:新的字节缓冲区
抛出: IllegalArgumentException - 如果capacity 为负整数
2、public static ByteBuffer allocate(int capacity) 分配一个新的字节缓冲区。新缓冲区的位置将为零,其界限将为其容量,其标记是不确定的。它将具有一个底层实现数组,且其数组偏移量将为零。
参数:capacity - 新缓冲区的容量,以字节为单位
返回:新的字节缓冲区
抛出: IllegalArgumentException - 如果capacity 为负整数
3、public static ByteBuffer wrap(byte[] array,int offset,int length) 将 byte 数组包装到缓冲区中。
新的缓冲区将由给定的 byte 数组支持;也就是说,缓冲区修改将导致数组修改,反之亦然。新缓冲区的容量将为array.length,其位置将为offset,其界限将为 offset + length,其标记是不确定的。其底层实现数组将为给定数组,并且其数组偏移量将为零。
参数:array - 支持新缓冲区的数组
offset - 要使用的子数组的偏移量;必须为非负且不大于array.length。将新缓冲区的位置设置为此值。
length - 要使用的子数组的长度;必须为非负且不大于array.length - offset。将新缓冲区的界限设置为offset + length。
返回:新的字节缓冲区
抛出:IndexOutOfBoundsException - 如果关于offset 和length 参数的前提不成立
4、public static ByteBuffer wrap(byte[] array) 将 byte 数组包装到缓冲区中。
新的缓冲区将由给定的 byte 数组支持;也就是说,缓冲区修改将导致数组修改,反之亦然。新缓冲区的容量和界限将为array.length,其位置将为零,其标记是不确定的。其底层实现数组将为给定数组,并且其数组偏移量将为零。
array
- 实现此缓冲区的数组返回:新的字节缓冲区
5、public abstract ByteBuffer slice() 创建新的字节缓冲区,其内容是此缓冲区内容的共享子序列。
新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的位置将为零,其容量和界限将为此缓冲区中所剩余的字节数量,其标记是不确定的。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
6、public abstract ByteBuffer duplicate() 创建共享此缓冲区内容的新的字节缓冲区。
新缓冲区的内容将为此缓冲区的内容。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的容量、界限、位置和标记值将与此缓冲区相同。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
7、public abstract ByteBuffer asReadOnlyBuffer() 创建共享此缓冲区内容的新的只读字节缓冲区。
新缓冲区的内容将为此缓冲区的内容。此缓冲区内容的更改在新缓冲区中是可见的,但新缓冲区将是只读的并且不允许修改共享内容。两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的容量、界限、位置和标记值将与此缓冲区相同。
如果此缓冲区本身是只读的,则此方法与 duplicate 方法完全相同。
8、public abstract byte get() 相对 get 方法。读取此缓冲区当前位置的字节,然后该位置递增。 返回: 缓冲区当前位置的字节抛出:
BufferUnderflowException
- 如果该缓冲区的当前位置不小于其界限
9、public abstract ByteBuffer put(byte b) 相对 put 方法 (可选操作) 。 将给定的字节写入此缓冲区的当前位置,然后该位置递增。 参数:
b
- 要写入的字节返回:此缓冲区 抛出:
BufferOverflowException
- 如果此缓冲区的当前位置不小于其界限
ReadOnlyBufferException
- 如果此缓冲区是只读缓冲区
10、public abstract byte get(int index) 绝对 get 方法。读取指定索引处的字节。
-
参数:
index- 将从中读取该字节的索引 - 返回:给定索引处的字节
-
抛出:
IndexOutOfBoundsException- 如果 index 为负或不小于缓冲区界限 -
- 11、public abstract ByteBuffer put(int index,byte b) 绝对 put 方法 (可选操作)。 将给定字节写入此缓冲区的给定索引处。
-
参数:
index- 将在该位置写入字节的索引 -
b- 要写入的字节值 - 返回: 此缓冲区
-
抛出:
IndexOutOfBoundsException- 如果 index 为负或不小于缓冲区界限 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区 -
- 12、 public ByteBuffer get (byte[] dst, int offset, int length)
此方法将此缓冲区的字节传输到给定的目标数组中。如果此缓冲中剩余的字节少于满足请求所需的字节(即如果 length > remaining()),则不传输字节且抛出BufferUnderflowException。
否则,此方法将此缓冲区中的 length 个字节复制到给定数组中,从此缓冲区的当前位置和数组中的给定偏移量位置开始复制。然后此缓冲区的位置将增加length。
换句话说,调用此方法的形式为 src.get(dst, off, len),效果与以下循环语句完全相同:
for (int i = off; i < off + len; i++)
dst[i] = src.get();
区别在于它首先检查此缓冲区中是否具有足够的字节,这样可能效率更高。
- 参数:
-
dst- 向其中写入字节的数组 -
offset- 要写入的第一个字节在数组中的偏移量;必须为非负且不大于 dst.length -
length- 要写入到给定数组中的字节的最大数量;必须为非负且不大于 dst.length - offset - 返回:
- 此缓冲区
- 抛出:
-
BufferUnderflowException- 如果此缓冲区中的剩余字节少于 length -
IndexOutOfBoundsException- 如果关于 offset 和 length 参数的前提不成立
-
相对批量
get 方法。
此方法将此缓冲区的字节传输到给定的目标数组中。调用此方法的形式为 src.get(a),该调用与以下调用完全相同:
src.get(a, 0, a.length)
-
- 返回:
- 此缓冲区
- 抛出:
-
BufferUnderflowException- 如果此缓冲区中的剩余字节少于 length
此方法将给定源缓冲区中的剩余字节传输到此缓冲区中。如果源缓冲区中的剩余字节多于此缓冲区中的剩余字节,即如果 src.remaining() > remaining(),则不传输字节且抛出BufferOverflowException。
否则,此方法将给定缓冲区中的 n = src.remaining() 个字节复制到此缓冲区中,从每个缓冲区的当前位置开始复制。然后这两个缓冲区的位置都增加n。
换句话说,调用此方法的形式为 dst.put(src),效果与以下循环语句完全相同:
while (src.hasRemaining())
dst.put(src.get());
区别在于它首先检查此缓冲区中是否有足够空间,这样可能效率更高。
- 参数:
-
src- 要从中读取字节的源缓冲区;不能为此缓冲区 - 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区没有足够的空间来容纳源缓冲区中剩余的字节 -
IllegalArgumentException- 如果源缓冲区是此缓冲区 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
此方法将把给定源数组中的字节字传输到此缓冲区中。如果要从该数组中复制的字节多于此缓冲区中的剩余字节,即如果 length > remaining()),则不传输字节且将抛出BufferOverflowException。
否则,此方法将给定数组中的 length 个字节复制到此缓冲区中,从数组中给定偏移量位置和此缓冲区的当前位置开始复制。然后此缓冲区的位置将增加length。
换句话说,调用此方法的形式为 dst.put(src, off, len),效果与以下循环语句完全相同:
for (int i = off; i < off + len; i++)
dst.put(a[i]);
区别在于它首先检查此缓冲区中是否有足够空间,这样可能效率更高。
- 参数:
-
src- 要从中读取字节的数组 -
offset- 要读取的第一个字节在数组中的偏移量;必须为非负且不大于 array.length -
length- 要从给定数组读取的字节的数量;必须为非负且不大于 array.length - offset - 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区没有足够空间 -
IndexOutOfBoundsException- 如果关于 offset 和 length 参数的前提不成立 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
此方法将给定的源 byte 数组的所有内容传输到此缓冲区中。调用此方法的形式为 dst.put(a),该调用与以下调用完全相同:
dst.put(a, 0, a.length)
- 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区没有足够空间 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
-
判断是否可通过一个可访问的 byte 数组实现此缓冲区。
如果此方法返回 true,则可以安全地调用
array和arrayOffset方法。 -
- 返回:
- 当且仅当存在实现此缓冲区的数组,并且此缓冲区不是只读缓冲区时,返回 true
-
返回实现此缓冲区的 byte 数组
(可选操作)。
此缓冲区的内容修改将导致返回的数组内容修改,反之亦然。
调用此方法之前要调用
hasArray方法,以确保此缓冲区具有可访问的底层实现数组。 -
- 返回:
- 实现此缓冲区的数组
- 抛出:
-
ReadOnlyBufferException- 如果存在实现此缓冲区的数组,但缓冲区是只读的 -
UnsupportedOperationException- 如果不存在某个可访问的数组实现此缓冲区
-
返回此缓冲区中的第一个元素在缓冲区的底层实现数组中的偏移量
(可选操作)。
如果存在实现此缓冲区的数组,则缓冲区位置 p 对应于数组索引 p + arrayOffset()。
调用此方法之前要调用
hasArray方法,以确保此缓冲区具有可访问的底层实现数组。 -
- 指定者:
-
类
Buffer中的arrayOffset
-
- 返回:
- 此缓冲区的第一个元素在缓冲区数组中的偏移量
- 抛出:
-
ReadOnlyBufferException- 如果存在实现此缓冲区的数组,但缓冲区是只读的 -
UnsupportedOperationException- 如果不存在某个可访问的数组实现此缓冲区
-
压缩此缓冲区
(可选操作)。
将缓冲区的当前位置和界限之间的字节(如果有)复制到缓冲区的开始处。即将索引 p = position() 处的字节复制到索引 0 处,将索引p + 1 处的字节复制到索引 1 处,依此类推,直到将索引limit() - 1 处的字节复制到索引 n = limit() - 1 - p 处。然后将缓冲区的位置设置为n+1,并将其界限设置为其容量。如果已定义了标记,则丢弃它。
将缓冲区的位置设置为复制的字节数,而不是零,以便调用此方法后可以紧接着调用另一个相对 put 方法。
从缓冲区写入数据之后调用此方法,以防写入不完整。例如,以下循环语句通过 buf 缓冲区将字节从一个信道复制到另一个信道:
buf.clear(); // Prepare buffer for use while (in.read(buf) >= 0 || buf.position != 0) { buf.flip(); out.write(buf); buf.compact(); // In case of partial write } -
- 返回:
- 此缓冲区
- 抛出:
-
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
23、public int hashCode()返回此缓冲区的当前哈希码。
字节缓冲区的哈希码仅取决于其中剩余的元素;也就是说,取决于从 position() 开始一直到(包括)limit() - 1 处的元素。
因为缓冲区哈希码与内容有关,因此建议不要在哈希映射或其他类似数据结构中将缓冲区用作键,除非知道其内容不会发生更改。
- 返回:
- 此缓冲区的当前哈希码。
当且仅当满足以下条件时两个字节缓冲区相同:
它们具有相同的元素类型,
它们具有相同数量的剩余元素,并且
两个剩余元素序列(与它们的起始位置无关)逐点相同。
字节缓冲区与任何其他类型的对象都不同。
- 参数:
-
ob- 此缓冲区要比较的对象 - 返回:
- 当且仅当此缓冲区与给定对象相同时,返回 true
-
将此缓冲区与另一个缓冲区进行比较。
比较两个字节缓冲区的方法是按字典顺序比较它们的剩余元素序列,而不考虑每个序列在其对应缓冲区中的起始位置。
字节缓冲区不能与任何其他类型的对象进行比较。
-
- 指定者:
-
接口
Comparable<ByteBuffer>中的compareTo
-
- 参数:
-
that- 要比较的对象。 - 返回:
- 当此缓冲区小于、等于或大于给定缓冲区时,返回负整数、零或正整数
BIG_ENDIAN
。
27、public final ByteBuffer order( ByteOrder bo) 修改此缓冲区的字节顺序。 参数:
bo
- 新的字节顺序,要么是
BIG_ENDIAN
,要么是
LITTLE_ENDIAN
返回:
此缓冲区
28、public abstract char getChar() 用于读取 char 值的相对 get 方法。
读取此缓冲区的当前位置之后的两个字节,根据当前的字节顺序将它们组成 char 值,然后将该位置增加 2。
- 返回:
- 缓冲区当前位置的 char 值
- 抛出:
-
BufferUnderflowException- 如果此缓冲区中的剩余字节数少于 2
-
用来写入 char 值的相对
put 方法
(可选操作)。
将两个包含指定 char 值的字节按照当前的字节顺序写入到此缓冲区的当前位置,然后将该位置增加 2。
-
- 参数:
-
value- 要写入的 char 值 - 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区中的剩余字节数少于 2 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区 -
- 参数:
-
index- 将从该位置读取字节的索引 - 返回:
- 给定索引处的 char 值
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 1 所得的值
-
用于写入 char 值的绝对
put 方法
(可选操作)。
将两个包含给定 char 值的字节按照当前的字节顺序写入到此缓冲区的给定索引处。
-
- 参数:
-
index- 将在该位置写入字节的索引 -
value- 要写入的 char 值 - 返回:
- 此缓冲区
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 1 所得的值 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的位置将为零,其容量和界限将为此缓冲区中所剩余的字节数的二分之一,其标记是不确定的。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
- 返回:
- 新的 char 缓冲区
-
用于读取 short 值的相对
get 方法。
读取此缓冲区的当前位置之后的两个字节,根据当前的字节顺序将它们组成 short 值,然后将该位置增加 2。
-
- 返回:
- 缓冲区当前位置的 short 值
- 抛出:
-
BufferUnderflowException- 如果此缓冲区中的剩余字节数少于 2
将两个包含指定 short 值的字节按照当前的字节顺序写入到此缓冲区的当前位置,然后将该位置增加 2。
- 参数:
-
value- 要写入的 short 值 - 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区中的剩余字节数少于 2 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
-
用于读取 short 值的绝对
get 方法。
读取给定索引处的两个字节,根据当前的字节顺序将它们组成 short 值。
-
- 参数:
-
index- 将从该位置读取字节的索引 - 返回:
- 给定索引处的 short 值
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 1 所得的值
将两个包含给定 short 值的字节按照当前的字节顺序写入到此缓冲区的给定索引处。
- 参数:
-
index- 将在该位置写入字节的索引 -
value- 要写入的 short 值 - 返回:
- 此缓冲区
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 1 所得的值 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
-
创建此字节缓冲区的视图,作为 short 缓冲区。
新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的位置将为零,其容量和界限将为此缓冲区中所剩余的字节数的二分之一,其标记是不确定的。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
-
- 返回:
- 新的 short 缓冲区
-
用于读取 int 值的相对
get 方法。
读取此缓冲区的当前位置之后的 4 个字节,根据当前的字节顺序将它们组成 int 值,然后将该位置增加 4。
-
- 返回:
- 缓冲区当前位置的 int 值
- 抛出:
-
BufferUnderflowException- 如果此缓冲区中的剩余字节数少于 4
将 4 个包含给定 int 值的字节按照当前的字节顺序写入到此缓冲区的当前位置,然后将该位置增加 4。
- 参数:
-
value- 要写入的 int 值 - 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区中的剩余字节数少于 4 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
读取给定索引处的 4 个字节,根据当前的字节顺序将它们组成 int 值。
- 参数:
-
index- 将从该位置读取字节的索引 - 返回:
- 给定索引处的 int 值
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 3 所得的值
-
用于写入 int 值的绝对
put 方法
(可选操作)。
将 4 个包含给定 int 值的字节按照当前的字节顺序写入到此缓冲区的给定索引处。
-
- 参数:
-
index- 将在该位置写入字节的索引 -
value- 要写入的 int 值 - 返回:
- 此缓冲区
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 3 所得的值 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
-
创建此字节缓冲区的视图,作为 int 缓冲区。
新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的位置将为零,其容量和界限将为此缓冲区中所剩余的字节数的四分之一,其标记是不确定的。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
-
- 返回:
- 新的 int 缓冲区
-
用于读取 long 值的相对
get 方法。
读取此缓冲区的当前位置之后的 8 个字节,根据当前的字节顺序将它们组成 long 值,然后将该位置增加 8。
-
- 返回:
- 缓冲区当前位置的 long 值
- 抛出:
-
BufferUnderflowException- 如果此缓冲区中的剩余字节数少于 8
-
用于写入 long 值
(可先操作) 的相对
put 方法。
将 8 个包含给定 long 值的字节按照当前的字节顺序写入到此缓冲区的当前位置,然后将该位置增加 8。
-
- 参数:
-
value- 要写入的 long 值 - 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区中的剩余字节数少于 8 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
-
用于读取 long 值的绝对
get 方法。
读取给定索引处的 8 个字节,根据当前的字节顺序将它们组成 long 值。
-
- 参数:
-
index- 将从该位置读取字节的索引 - 返回:
- 给定索引处的 long 值
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 7 所得的值
-
用于写入 long 值的绝对
put 方法
(可选操作)。
将 8 个包含给定 long 值的字节按照当前的字节顺序写入到此缓冲区的给定索引处。
-
- 参数:
-
index- 将在该位置写入字节的索引 -
value- 要写入的 long 值 - 返回:
- 此缓冲区
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 7 所得的值 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的位置将为零,其容量和界限将为此缓冲区中所剩余的字节数的八分之一,其标记是不确定的。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
- 返回:
- 新的 long 缓冲区
读取此缓冲区的当前位置之后的 4 个字节,根据当前的字节顺序将它们组成 float 值,然后将该位置增加 4。
- 返回:
- 缓冲区当前位置的 float 值
- 抛出:
-
BufferUnderflowException- 如果此缓冲区中的剩余字节数少于 4
-
用于写入 float 值的相对
put 方法
(可选操作)。
将 4 个包含给定 float 值的字节按照当前的字节顺序写入到此缓冲区的当前位置,然后然后将该位置增加 4。
-
- 参数:
-
value- 要写入的 float 值 - 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区中的剩余字节数少于 4 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
读取给定索引处的 4 个字节,根据当前的字节顺序将它们组成 float 值。
- 参数:
-
index- 将从该位置读取字节的索引 - 返回:
- 给定索引处的 float 值
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 3 所得的值
将 4 个包含给定 float 值的字节按照当前的字节顺序写入到此缓冲区的给定索引处。
- 参数:
-
index- 将在该位置写入字节的索引 -
value- 要写入的 float 值 - 返回:
- 此缓冲区
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 3 所得的值 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的位置将为零,其容量和其界限将为此缓冲区中剩余字节数的四分之一,其标记是不确定的。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
- 返回:
- 新的 float 缓冲区
-
用于读取 double 值的相对
get 方法。
读取此缓冲区的当前位置之后的 8 个字节,根据当前的字节顺序将它们组成 double 值,然后将该位置增加 8。
-
- 返回:
- 缓冲区当前位置的 double 值
- 抛出:
-
BufferUnderflowException- 如果此缓冲区中的剩余字节数少于 8
将 8 个包含给定 double 值的字节按照当前的字节顺序写入到此缓冲区的当前位置,然后将该位置增加 8。
- 参数:
-
value- 要写入的 double 值 - 返回:
- 此缓冲区
- 抛出:
-
BufferOverflowException- 如果此缓冲区中的剩余字节数少于 8 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
读取给定索引处的 8 个字节,根据当前的字节顺序将它们组成 double 值。
- 参数:
-
index- 将从该位置读取字节的索引 - 返回:
- 给定索引处的 double 值
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 7 所得的值
将 8 个包含给定 double 值的字节按照当前的字节顺序写入到此缓冲区的给定索引处。
- 参数:
-
index- 将在该位置写入字节的索引 -
value- 要写入的 double 值 - 返回:
- 此缓冲区
- 抛出:
-
IndexOutOfBoundsException- 如果 index 为负数,或者不小于该缓冲区的界限 - 7 所得的值 -
ReadOnlyBufferException- 如果此缓冲区是只读缓冲区
-
创建此字节缓冲区的视图,作为 double 缓冲区。
新缓冲区的内容将从此缓冲区的当前位置开始。此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
新缓冲区的位置将为零,其容量和界限将为此缓冲区中所剩余的字节数的八分之一,其标记是不确定的。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当且仅当此缓冲区为只读时,新缓冲区才是只读的。
-
- 返回:
- 新的 double 缓冲区