https://blog.csdn.net/yuanlaijike/article/details/79452884
一、Lucene简介
Lucene是Apache Jakarta家族中的一个开源项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎、索引引擎和部分文本分析引擎。
Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具,是目前最为流行的基于 Java 开源全文检索工具包。
的数据总体分为两种:
结构化数据:指具有固定格式或有限长度的数据,如数据库、元数据等。非结构化数据:指不定长或无固定格式的数据,如邮件、word文档等磁盘上的文件。
对于结构化数据的全文搜索很简单,因为数据都是有固定格式的,例如搜索数据库中数据使用SQL语句即可。
对于非结构化数据,有以下两种方法:
顺序扫描法(Serial Scanning)全文检索(Full-text Search)
顺序扫描法
如果要找包含某一特定内容的文件,对于每一个文档,从头到尾扫描内容,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件,因此速度很慢。
全文检索
将非结构化数据中的一部分信息提取出来,重新组织,使其变得具有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这部分从非结构化数据中提取出的然后重新组织的信息,我们称之索引。
例如字典的拼音表和部首检字表就相当于字典的索引,通过查找拼音表或者部首检字表就可以快速的查找到我们要查的字。
这种先建立索引,再对索引进行搜索的过程就叫全文检索(Full-text Search)。
二、全文检索流程
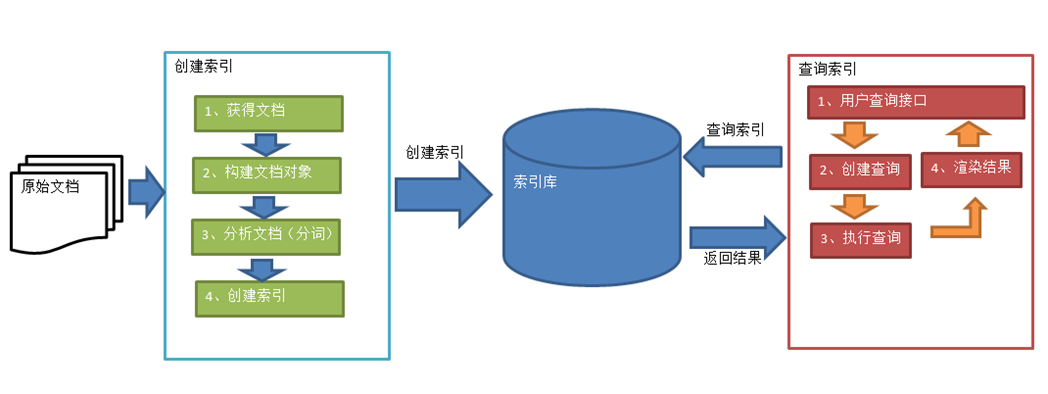
2.1 索引过程
绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
- 获得原始文档(原始内容即要搜索的内容)
- 采集文档
- 创建文档
- 分析文档
- 索引文档
2.1.1 获得原始文档
原始文档是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等等。
从互联网、数据库、文件系统中获取要搜索的原始信息,这个过程就是信息采集,信息采集的目的是对原始内容进行索引。
在互联网上采集信息的程序称为爬虫。Lucene不提供信息采集的类库,需要自己编写一个爬虫程序实现信息采集,也可以使用一些开源软件实现信息采集,如Nutch、JSoup、Heritrix等等。
对于磁盘上文件内容,可以通过IO流来读取文本文件内容,对于pdf、doc、xls等文件可以通过第三方解析工具来读取文件内容,如Apache POI等。
2.1.2 创建文档对象
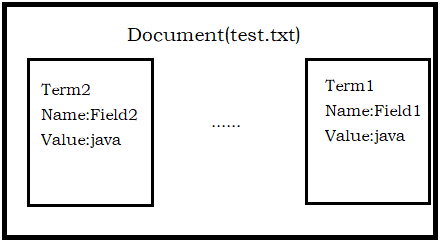
获得原始内容的目的是为了创建索引,在索引前需要将原始内容创建成文档(Document),文档中包含多个域(Field),在域中存储内容。
域可以被理解为一个原始文档的属性。例如有一个文本文件test.txt,我们将这个文本文件的内容创建成文档(Document),它就包含了许多域,比如有文件名、文件大小、最后修改时间等等,如图:

注意:每个Document可以有多个Field,不同的Document可以有不同的Field,同一个Document可以有相同的Field。
2.1.3 分析文档
将原始内容创建和包含域(Field)的文档(Document)后,需要对域中的内容进行分析,分析的过程是经过对原始文档提取单词、字母大小写转换、去除符号、去除停用词等过程后生成最终的语汇单元。
例如分析以下文档后:
Lucene is a Java full-text search engine. Lucene is not a complete application, but rather a code library and API that can easily be used to add search capabilities to applications
分析后得到的语汇单元:
lucene、java、full 、search、engine…
将每个语汇单元叫做一个term,不同的域中拆分出来的相同的语汇单元是不同的 term 。term 中包含两部分一部分是文档的域名,另一部分是内容。例如:文件名中包含 java 和文件内容中包含的 java是不同的 term 。
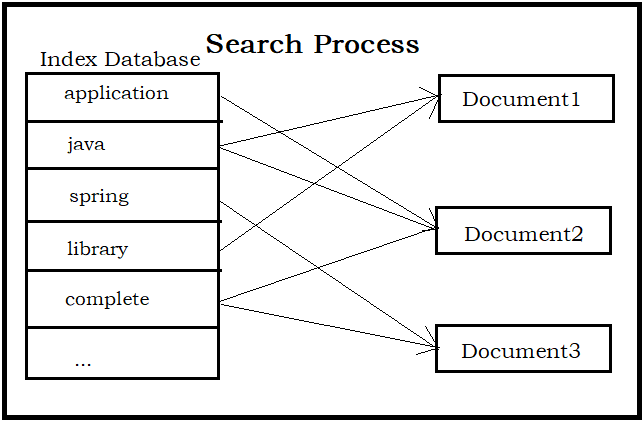
2.1.4 创建索引
对所有文档分析得出的语汇单元进行索引,最终要实现只搜索语汇单元就能够找到文档(Document)。
2.2 搜索过程
红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
- 用户通过搜索界面
- 创建查询
- 执行搜索,从索引库搜索
- 渲染搜索结果
2.2.1 用户搜索
用户通过前端页面,将要搜索的关键字传递到后端。
2.2.2 创建查询
用户输入查询关键词执行搜索前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法。
2.2.3执行查询
根据查询对象获得对应的索引,从而找到索引所对应的文档。
2.2.4 渲染结果
以一个友好的界面将查询结果展示给用户,用户根据搜索结果找自己想要的信息,为了帮助用户很快找到自己的结果,提供了很多展示的效果,比如搜索结果中将关键字高亮显示,百度提供的快照等。
三、代码实现
3.1 环境配置
Lucene官方网站点击这里,Lucene作为Java中最受欢迎的全文检索工具,更新速度令人发指,本篇文章使用Lucene v6.6.2(PS:推荐大家使用Maven构建项目,节省到处找包的麻烦)。
下载后解压文件夹,介绍下要用到的子包:
| 目录名 | 含义 |
|---|---|
| lucene-analyzers-common | 不同语言和领域通用的分析器 |
| lucene-core | Lucene核心类库 |
| lucene-highlighter | 高亮显示关键字 |
| lucene-memory | 内存文档 |
| lucene-queries | Lucene核心中用到的过滤器和查询器 |
| lucene-queryparser | 解析器和解析框架 |
3.2 Query对象
在查询过程中,需要使用到Query类,Query是一个抽象类,这个类的目的是把用户输入的查询字符串封装成Lucene能够识别的Query。Query有许多实现。
3.2.1 TermQuery
TermQuery是Query的一个子类,他同时也是Lucene支持的最为基本的一个查询类。
/**
* TermQuery参数为一个Term对象,Term对象参数为要查询的Field的名称,以及查找的关键字
*/
TermQuery query=new TermQuery(new Term("title","lucene"));- 1
- 2
- 3
- 4
3.2.2 BooleanQuery
BooleanQuery是实际开发过程中经常使用的一种查询,它其实就是一个组合的Query,在使用中的时候可以把各种Query对象添加进去并且标明它们之间的逻辑关系,逻辑关系有以下几种:
| 名称 | 含义 |
|---|---|
| BooleanClause.Occur MUST | 对于必须出现在匹配文档中的子句,使用此运算符。 |
| BooleanClause.Occur MUST_NOT | 对于不得出现在匹配文档中的子句使用此运算符。 |
| BooleanClause.Occur SHOULD | 对于应出现在匹配文档中的子句,使用此运算符。 |
| BooleanClause.Occur FILTER | Like MUST except that these clauses do not participate in scoring. |
逻辑关系含有以下几种组合:
| 名称 | 含义 |
|---|---|
| MUST和MUST | 表示”与”的关系,结果为检索子句的交集 |
| MUST和MUST_NOT | 查询结果中不能包含MUST_NOT所对应的查询子句的检索结果 |
| MUST_NOT和MUST_NOT | 无意义,检索无结果 |
| SHOULD和MUST | 无意义,结果为MUST子句的检索结果 |
| SHOULD和MUST_NOT | SHOULD功能同MUST,相当于MUST和MUST_NOT的检索结果 |
| SHOULD和SHOULD | 表示”或”的关系,结果为检索子句的并集 |
例如求两个query的交集:
TermQuery query1 = new TermQuery(new Term("title","Lucene"));
TermQuery query2 = new TermQuery(new Term("content","Lucene"));
/**
* 求query1和query2的交集
*/
BooleanQuery booleanBuery = new BooleanQuery.Builder().add(query1,Occur.MUST).add(query2,Occur.MUST).build();- 1
- 2
- 3
- 4
- 5
- 6
- 7
BooleanQuery是可以嵌套的,一个BooleanQuery可以成为另一个BooleanQuery的条件子句。布尔型的子句数目不能超过1024。
3.2.3 NumericRangeQuery
NumericRangeQuery是一个数值型的范围查询类,使用如下:
/**
* 布尔型的后面的两个参数表示是否可以将两个临界值也加入到搜索中
*/
Query query=NumericRangeQuery.newIntRange(String field,Integer min,Integer max,boolean minInclusive,boolean maxInclusive);
/**
*例如:查询id在(10000,20000]
*/
Query query=NumericRangeQuery.newIntRange("id",10000,20000,false,true);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.2.4 PrefixQuery
PrefixQuery功能是前缀查询,查询出某个字段以什么开头的信息:
Term term = new Term("content","This");
/**
* 查询content以This开头
*/
PrefixQuery query=new PrefixQuery(term); - 1
- 2
- 3
- 4
- 5
- 6
- 7
3.2.5 PhraseQuery
PhraseQuery功能是短语查询,提供了一种叫做坡度的参数,用于表示词组的两个字之间可以插入无关单词的个数:
/**
* 查询标题为《Lucene...框架》,中间不超过5个字符
*/
PhraseQuery phraseQuery=new PhraseQuery();
phraseQuery.add(new Term("title","Lucene"));
phraseQuery.add(new Term("title","框架"));
//之间的间隔最大不能超过5个
phraseQuery.setSlop(5);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.2.6 FuzzyQuery
FuzzyQuery作用是模糊查询,在参数中需要指定最小相似度(maxEdits),取值为0、1、2,数字越小,模糊度越低,当为0的时候相当于TermQuery。
Query query=new FuzzyQuery(new Term("title","Lucene"),2); - 1
3.2.7 WildcardQuery
WildcardQuery叫做通配符搜索,支持符号:
- *代表0到多个字符
- ?代表一个的字符
/**
* 查询标题为《lu...n》,中间任意多个字符
*/
Query query=new WildcardQuery(new Term("title","lu*n?")); - 1
- 2
- 3
- 4
3.2.8 MatchAllDocsQuery
MatchAllDocsQuery作用很简单,就是搜索全部。
Query query=new MatchAllDocsQuery(); - 1
3.3 第一个全文检索例子
本例子项目结构如下:

import java.io.File;
import java.io.IOException;
import java.util.Collection;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
/**
* @className FirstDemo.java
* @author jitwxs
* @version 创建时间:2018年3月4日 下午11:45:36
*/
public class SearchEnglish {
/**
* 创建索引
* @author jitwxs
* @version 创建时间:2018年3月4日 下午11:52:51
* @param indexPath 索引路径
* @param resourcePath 被索引的路径
* @throws IOException
*/
public static void createIndex(String indexPath, String resourcePath) throws IOException {
/* Step1:创建IndexWrite对象
* (1)定义词法分析器
* (2)确定索引存储位置-->创建Directory对象
* (3)得到IndexWriterConfig对象
* (4)创建IndexWriter对象
*/
// 使用标准分词器
Analyzer analyzer = new StandardAnalyzer();
Directory directory = FSDirectory.open(new File(indexPath).toPath());
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 清除以前的索引
indexWriter.deleteAll();
// 得到txt后缀的文件集合
Collection<File> txtFiles = FileUtils.listFiles(new File(resourcePath), new String[] {"txt"}, true);
for (File file : txtFiles) {
String fileName = file.getName();
String content = FileUtils.readFileToString(file, "UTF-8");
/*
* Step2:创建Document对象,将Field地下添加到Document中
* Field第三个参数选项很多,具体参考API手册
*/
Document document = new Document();
document.add(new Field("fileName", fileName, TextField.TYPE_STORED));
document.add(new Field("content", content, TextField.TYPE_STORED));
/*
*Step4:使用 IndexWrite对象将Document对象写入索引库,并进行索引。
*/
indexWriter.addDocument(document);
}
if(indexWriter != null) {
indexWriter.close();
}
}
/**
* 查询索引
* @author jitwxs
* @version 创建时间:2018年3月5日 上午12:38:05
* @param indexPath 索引路径
* @param keyword 关键字
* @throws IOException
*/
public static void queryIndex(String indexPath, String keyword) throws IOException {
/*
* Step1:创建IndexSearcher对象
* (1)创建Directory对象
* (2)创建DirectoryReader对象
* (3)创建IndexSearcher对象
*/
Directory directory = FSDirectory.open(new File(indexPath).toPath());
DirectoryReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
/*
* Step2:创建TermQuery对象,指定查询域和查询关键词
*/
TermQuery query1 = new TermQuery(new Term("fileName",keyword));
TermQuery query2 = new TermQuery(new Term("content",keyword));
/*
* Step3:创建Query对象
*/
BooleanQuery booleanBuery = new BooleanQuery.Builder().add(query1, Occur.SHOULD).add(query2, Occur.SHOULD)
.build();
/*
* Step4:根据查询条件查询结果,并遍历输出
* (1)查询结果得到TopDocs对象
* (2)根据topDocs得到ScoreDoc对象
* (3)根据scoreDoc得到Document对象
* (4)输出结果
*/
TopDocs topDocs = indexSearcher.search(booleanBuery, 100);
System.out.println("共找到 " + topDocs.totalHits + " 处匹配");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
Document doc = indexSearcher.doc(scoreDoc.doc);
String fileName = doc.get("fileName");
System.out.println("fileName: " + fileName);
}
if(reader != null) {
reader.close();
}
}
public static void main(String[] args) {
// 存放用于查找文件内容的文件夹
String resourcePath = "D:\\lucene-resource";
// Lucene索引文件夹
String indexPath = "D:\\lucene-index";
try {
createIndex(indexPath, resourcePath);
queryIndex(indexPath, "java");
}catch (IOException e) {
e.printStackTrace();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
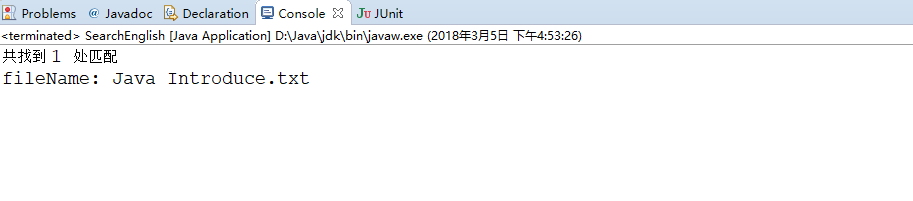
我随意写了几篇英文做了下测试:

搜索关键字java,结果如下:
3.4 中文分词
在上面的例子中,我们已经实现了一个最基本的全文检索。我们知道,全文检索的好坏和分词器(Analyzer)有着十分重要的关系,上面使用的是标准分词器(StandardAnalyzer),在处理英文中还算可以,但是处理中文,就没有了任何效果,我们亟需一个好用的中文分词器。
对于中文处理,Lucene自带了分词器,即SmartChineseAnalyzer,但是扩展性差,扩展词库、禁用词库和同义词库等不好处理。
我们可以使用一些第三方的分词器,主要有以下几种:
paoding:庖丁解牛,但是其最多只支持到Lucene3,已经过时,不推荐使用。mmseg4j:目前支持到Lucene6 ,目前仍然活跃,使用mmseg算法。IK-Analyzer:开源的轻量级的中文分词工具包,官方支持到Lucene5。
本篇文章使用IK-Analyzer来进行中文分词,不幸的是IK-Analyzer已经停止维护,其最新版本为IKAnalyzer2012_FF.jar,为了能够让IK-Analyzer支持到Lucene6,我自己对源码进行编译,现在能够支持到了Lucene6.6.2,点击下载我自行编译后的IK-Analyzer-6.6.2.jar。
注:如果要下载官方的
IKAnalyzer2012_FF.jar,点击下载,与此对应的Lucene版本为Lucene5.5.5,点击下载(本篇文章使用Lucene 6.6.2,因此不推荐官方的)。
项目结构如下:
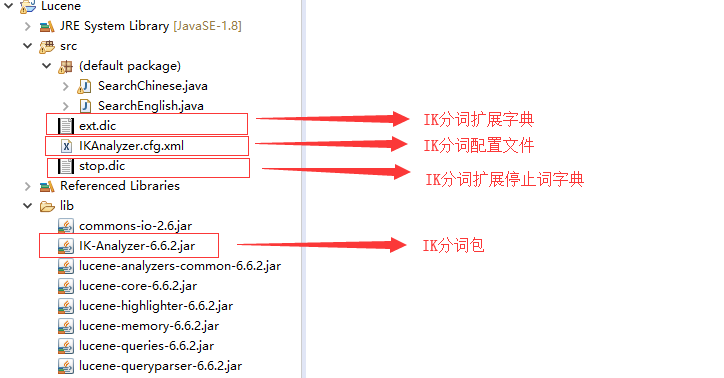
| 名称 | 含义 |
|---|---|
| IK-Analyzer.cfg.xml | IK分词的配置文件 |
| ext.dic | 扩展字典,里面放上你要添加的新词语 |
| stop.dic | 扩展停止词字典,放置例如“的 了”这样的停止词,这些词会被筛除掉 |
编辑配置文件IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<!-- 注意:下面两个文件保存编码必须为UTF-8,否则会导致无效! -->
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stop.dic;</entry>
</properties>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
编写中文分词的类:
import java.io.File;
import java.io.IOException;
import java.nio.file.FileSystems;
import java.util.Collection;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
* @className FirstDemo.java
* @author jitwxs
* @version 创建时间:2018年3月4日 下午11:45:36
*/
public class SearchChinese {
/**
* 创建索引
* @author jitwxs
* @version 创建时间:2018年3月4日 下午11:52:51
* @param indexPath 索引路径
* @param resourcePath 被索引的路径
* @throws IOException
*/
public static void createIndex(String indexPath, String resourcePath) throws IOException {
// 使用IK分词器
Analyzer analyzer = new IKAnalyzer();
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(indexPath));
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 清除以前的索引
indexWriter.deleteAll();
// 得到txt后缀的文件集合
Collection<File> txtFiles = FileUtils.listFiles(new File(resourcePath), new String[] { "txt" }, true);
for (File file : txtFiles) {
String fileName = file.getName();
// 以UTF-8编码读取文件内容,如果文件不是该编码,去掉该参数即可
String content = FileUtils.readFileToString(file, "UTF-8");
Document document = new Document();
document.add(new Field("fileName", fileName, TextField.TYPE_STORED));
document.add(new Field("content", content, TextField.TYPE_STORED));
indexWriter.addDocument(document);
printParticiple(analyzer, content);
}
if (indexWriter != null) {
indexWriter.close();
}
}
/**
* 查询索引
* @author jitwxs
* @version 创建时间:2018年3月5日 上午12:38:05
* @param indexPath 索引路径
* @param keyword 关键字
* @throws IOException
*/
public static void queryIndex(String indexPath, String keyword) throws Exception {
Directory directory = FSDirectory.open(new File(indexPath).toPath());
DirectoryReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
TermQuery query1 = new TermQuery(new Term("fileName", keyword));
TermQuery query2 = new TermQuery(new Term("content", keyword));
BooleanQuery booleanBuery = new BooleanQuery.Builder().add(query1, Occur.SHOULD).add(query2, Occur.SHOULD)
.build();
TopDocs topDocs = indexSearcher.search(booleanBuery, 100);
System.out.println("共找到 " + topDocs.totalHits + " 处匹配");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
Document doc = indexSearcher.doc(scoreDoc.doc);
String fileName = doc.get("fileName");
String content = doc.get("content");
System.out.println("fileName: " + fileName);
System.out.println("content: " + content);
}
if (reader != null) {
reader.close();
}
}
/**
* 输出分词的具体内容
* @author jitwxs
* @version 创建时间:2018年3月5日 下午11:13:09
* @param analyzer 分词器
* @param content 内容
* @throws IOException
*/
public static void printParticiple(Analyzer analyzer, String content) throws IOException {
TokenStream tokenStream = analyzer.tokenStream("", content);
// 设置一个引用(相当于指针),这个引用可以是多种类型,可以是关键词的引用,偏移量的引用等等,charTermAttribute对象代表当前的关键词
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
// 调用tokenStream的reset方法,不调用该方法,会抛出一个异常
tokenStream.reset();
// 使用while循环来遍历单词列表
while (tokenStream.incrementToken()) {
System.out.println(charTermAttribute);
}
tokenStream.close();
}
public static void main(String[] args) {
// 存放用于查找文件内容的文件夹
String resourcePath = "D:\\lucene-resource";
// Lucene索引文件夹
String indexPath = "D:\\lucene-index";
try {
createIndex(indexPath, resourcePath);
queryIndex(indexPath, "jitwxs");
} catch (Exception e) {
e.printStackTrace();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
这次只准备一个文件测试下即可:
测试下分词效果:
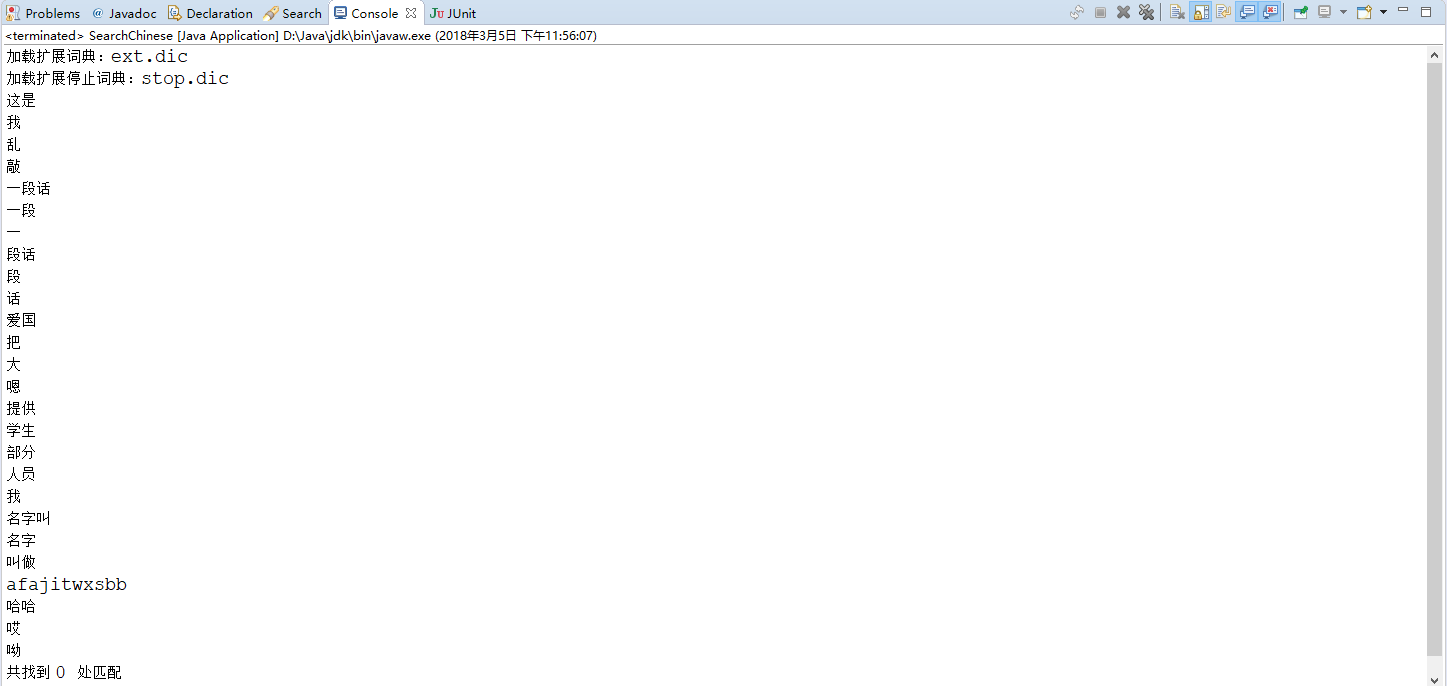
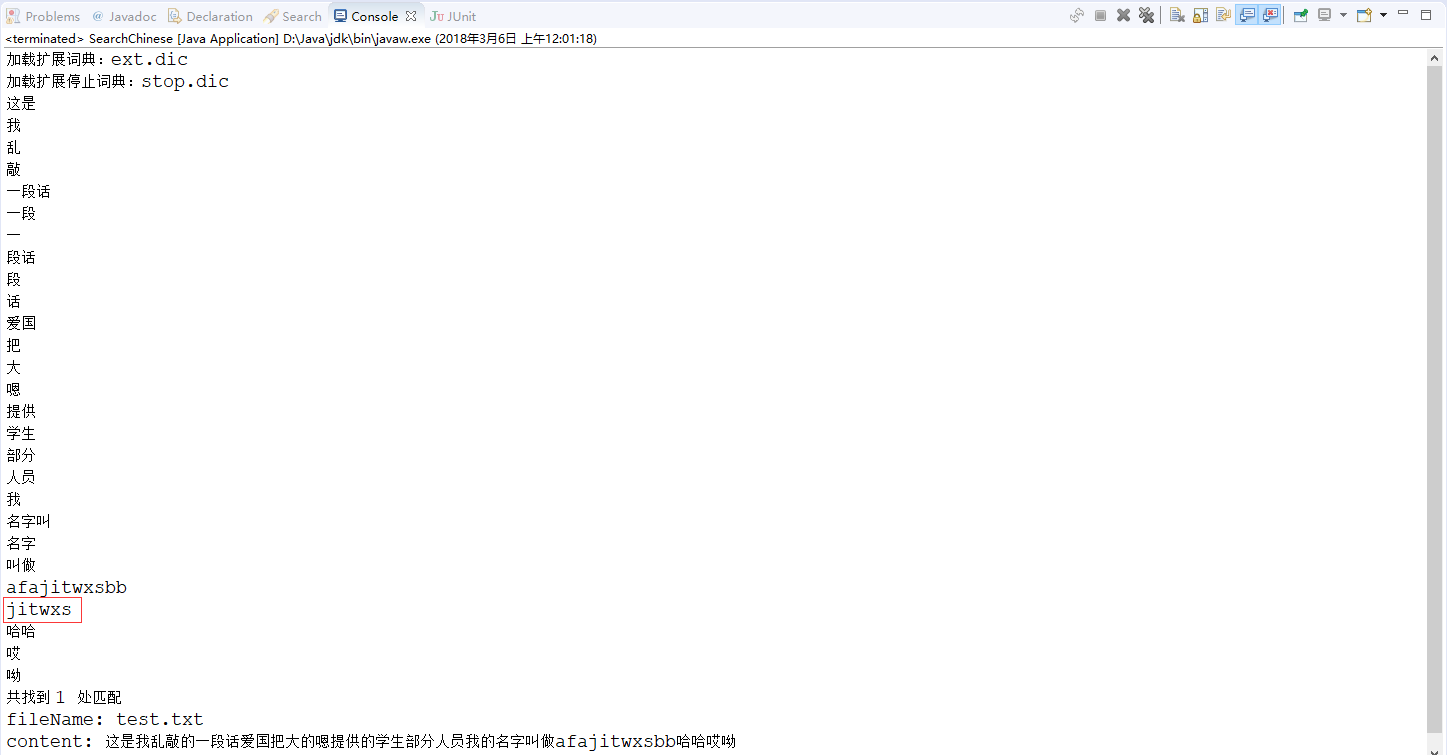
分词效果还可以,但是我们要搜的jitwxs却没有搜到,因为它自带的字典中没有这个词,自然没法识别出来。我们知道IK-Analyzer相较于自带的SmartChineseAnalyzer最大的优点就是扩展性,我们在之前的扩展字典文件ext.dic中添加单词jitwxs:

注:再啰嗦下,这两个文件一定要确保是UTF-8编码,否则会导致无法生效(IK-Analyzer内部我是用UTF-8读取的)。重新运行程序,成功识别出了我们添加的单词:
3.5 代码高亮
首先自定义代码高亮的代码,然后对每个filed进行取值,包含关键字会高亮显示,否则为空:
/**
* 高亮显示代码
* @author jitwxs
* @version 创建时间:2018年3月6日 上午9:08:56
* @param query 查询对象
* @param doc Document对象
* @param fieldName filed名
* @param startCode 高亮起始代码
* @param endCode 高亮结束代码
* @return
* @throws IOException
* @throws InvalidTokenOffsetsException
*/
public static String highlight(Query query, Document doc, String fieldName, String startCode, String endCode) throws IOException, InvalidTokenOffsetsException {
QueryScorer scorer = new QueryScorer(query);
// 设置高亮的格式
SimpleHTMLFormatter formatter = new SimpleHTMLFormatter(startCode, endCode);
Highlighter highlighter = new Highlighter(formatter, scorer);
// 设置高亮的分段
highlighter.setTextFragmenter(new SimpleSpanFragmenter(scorer));
String fieldVale = doc.get(fieldName);
// 高亮代码,如果没找到匹配的,返回null
String tmp = highlighter.getBestFragment(new IKAnalyzer(), fieldName, fieldVale);
if(tmp != null) {
return tmp;
} else {
return fieldVale;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
完整代码:
import java.io.File;
import java.io.IOException;
import java.nio.file.FileSystems;
import java.util.Collection;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.search.highlight.SimpleSpanFragmenter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.wltea.analyzer.lucene.IKAnalyzer;
/**
* @className SearchHighlighter.java
* @author jitwxs
* @version 创建时间:2018年3月6日 上午12:32:34
*/
public class SearchHighlighter {
/**
* 创建索引
* @author jitwxs
* @version 创建时间:2018年3月4日 下午11:52:51
* @param indexPath 索引路径
* @param resourcePath 被索引的路径
* @throws IOException
*/
public static void createIndex(String indexPath, String resourcePath) throws IOException {
// 使用IK分词器
Analyzer analyzer = new IKAnalyzer();
Directory directory = FSDirectory.open(FileSystems.getDefault().getPath(indexPath));
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 清除以前的索引
indexWriter.deleteAll();
// 得到txt后缀的文件集合
Collection<File> txtFiles = FileUtils.listFiles(new File(resourcePath), new String[] { "txt" }, true);
for (File file : txtFiles) {
String fileName = file.getName();
// 以UTF-8编码读取文件内容,如果文件不是该编码,去掉该参数即可
String content = FileUtils.readFileToString(file, "UTF-8");
Document document = new Document();
document.add(new Field("fileName", fileName, TextField.TYPE_STORED));
document.add(new Field("content", content, TextField.TYPE_STORED));
indexWriter.addDocument(document);
}
if (indexWriter != null) {
indexWriter.close();
}
}
/**
* 查询索引
* @author jitwxs
* @version 创建时间:2018年3月5日 上午12:38:05
* @param indexPath 索引路径
* @param keyword 关键字
* @throws IOException
*/
public static void queryIndex(String indexPath, String keyword) throws Exception {
Directory directory = FSDirectory.open(new File(indexPath).toPath());
DirectoryReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
TermQuery query1 = new TermQuery(new Term("fileName", keyword));
TermQuery query2 = new TermQuery(new Term("content", keyword));
BooleanQuery booleanBuery = new BooleanQuery.Builder().add(query1, Occur.SHOULD).add(query2, Occur.SHOULD)
.build();
TopDocs topDocs = indexSearcher.search(booleanBuery, 100);
// 定义高亮代码(前后加红色)
String startCode = "<span style=\"color:red\">";
String endCode = "</span>";
System.out.println("共找到 " + topDocs.totalHits + " 处匹配");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
Document doc = indexSearcher.doc(scoreDoc.doc);
// 高亮代码
String fileName = highlight(booleanBuery, doc, "fileName", startCode, endCode);
String content = highlight(booleanBuery, doc, "content", startCode, endCode);
System.out.println("fileName: " + fileName);
System.out.println("content: " + content);
}
if (reader != null) {
reader.close();
}
}
/**
* 高亮显示代码
* @author jitwxs
* @version 创建时间:2018年3月6日 上午9:08:56
* @param query 查询对象
* @param doc Document对象
* @param fieldName filed名
* @param startCode 高亮起始代码
* @param endCode 高亮结束代码
* @return
* @throws IOException
* @throws InvalidTokenOffsetsException
*/
public static String highlight(Query query, Document doc, String fieldName, String startCode, String endCode) throws IOException, InvalidTokenOffsetsException {
QueryScorer scorer = new QueryScorer(query);
// 设置高亮的格式
SimpleHTMLFormatter formatter = new SimpleHTMLFormatter(startCode, endCode);
Highlighter highlighter = new Highlighter(formatter, scorer);
// 设置高亮的分段
highlighter.setTextFragmenter(new SimpleSpanFragmenter(scorer));
String fieldVale = doc.get(fieldName);
// 高亮代码,如果没找到匹配的,返回null
String tmp = highlighter.getBestFragment(new IKAnalyzer(), fieldName, fieldVale);
if(tmp != null) {
return tmp;
} else {
return fieldVale;
}
}
public static void main(String[] args) {
// 存放用于查找文件内容的文件夹
String resourcePath = "D:\\lucene-resource";
// Lucene索引文件夹
String indexPath = "D:\\lucene-index";
try {
createIndex(indexPath, resourcePath);
queryIndex(indexPath, "jitwxs");
} catch (Exception e) {
e.printStackTrace();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
