题目:点击打开链接
心得:不得不说对于我这个菜鸡来说真的有点难啊,不过我又学到了一个新知识,值得庆贺。
坑:不同单词数。
大神的代码:(两种方法)
/*#include<bits/stdc++.h>
using namespace std;
int main(){
string str,temp;
set<string> ss;
while(getline(cin,str)){
if(str=="#")
break;
ss.clear();
stringstream sss(str);
while(sss>>temp)
ss.insert(temp);
cout<<ss.size()<<endl;
}
return 0;
}*/ 代码出处:刘汝佳红书
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main(void){
string input_str,*words;
int length,flag=0,k=0,word_num=0;
map<string,int> differ_word;
while(getline(cin,input_str)){
if(input_str=="#")
break;
length=input_str.size();
for(int i=0;i<length;i++){
if(input_str[i]!=' '&&flag==0){
++word_num;
flag=1;
continue;
}
if(flag==1){
if(input_str[i]==' '||i==length-1){
flag=0;
}
}
}
words=new string[word_num];
for(int j=0;j<length;j++){
if(input_str[j]!=' '){
words[k]+=input_str[j];//这里面的words[k]就是一个容器,往里面插入一个一个字母,直到玩成,再存储下一个单词
}//比如单词 gay 先存g 再存a(变成ga) 再存y(变成gay) 跳出循环
if(input_str[j]==' '){
if(j==length-1)
break;
if(input_str[j+1]!=' '&&words[k]!=" ")
++k;
}
cout<<words[k]<<endl;
}
for(int h=0;h<word_num;h++){
++differ_word[words[h]];
cout<<words[h];
}
cout<<differ_word.size()<<endl;
word_num=0;
flag=0;
k=0;
differ_word.clear();
}
return 0;
}关联容器
关联容器和顺序容器有着根本的不同:关联容器中的元素是按照关键字来保存和访问的,与之相对的顺序容器元素则是按照他们在容器中的位置来顺序保存和访问的。关联容器支持高效的关键字查找和访问,比较主要的关联容器类型是map和set。
map容器介绍
map是c++的一个标准容器,它提供了很好的一对一的关系。map容器的元素是一些关键字——值(key-value)对,key和value可以是你想要的任意类型,关键字起到了索引的作用,值则表示与索引相关的联的数据。换句话说,就是通过key可以找到相应的value。例如:将个人的学号作为关键字key,因为学号对每个人来说是唯一的,将其名字作为value。这样的数据结构称为“将学号映射到名字”。这样一来我们通过学号就可以找到其姓名。
map容器的特点:
它是一个相关联的容器,它的大小可以改变,它能根据关键字来提高读取数据能力
它提供一个双向的定位器来读写取数据。
它已经根据关键字和一个比较函数来排好序。
它的每一个元素的关键字key都是惟一的。
它是一个模板,它能提供一个一般且独立的数据类型
pair类型
在介绍map容器之前,我们需要了解名为pair的标准库类型。他定义在文件utility中。
一个pair保存两个数据成员。类似容器,pair是一个用来生成特定类型的模板。当创建一个pair时候,我们必须提供两个类型名,pair的数据成员将具有对应的类型。两个类型不要求一样。例如:
pair<string,string>anon;//保存两个string
pair<string,size_t> word_count;//保存一个string和一个size_tpair的默认构造函数对数据成员进行初始化,因此anon是一个包含两个空string的pair。word_count的size_t会初始化为0,string成员初始化为空。
与其他标准库类型不同的是,pair数据成员是public的,两个成员分别命名为first和second。
一、map引入
1、包含相应头文件和域
#include <map>
using namespace std;2、对象的定义,有两个参数key和value
//map <key,value>
map<string,int> my_map;二、map容器操作
1、对象的初始化,下面展示两种方法:
#include<iostreaam>
#include<map>
using namespace std;
int main(void){
/*第一种方法*/
map <string,int> my_map;
my_map[string("hello")]=1;//第一种
may_map[string("world")]=2;
/*第二种方法*/
map<string,string> authors={ {"Joyce","Jame"},
{"xiaoming","Jane"},
{"Davie","charles"}};
.......
}2、插入数据 ,对一个map容器进行insert操作时候,必须记住元素类型是pair,通常,对于想要插入的数据,并没有一个现成的pair对象,可以在insert的参数列表中创建一个pair:
//向my_map插入数据有4种方法
my_map.insert({"hello",1});
my_map.insert(make_pair("hello",1));
my_map.insert(pair<string, int>("everyone", 3));
my_Map.insert(map<string, int>::value_type("b",2));3、删除数据
my_Map.erase(p);
my_Map.erase("c"); //从my_map删除关键字为c的元素,返回一个size_type的值,指出删除元素的数量。注意:第一个语句,从my_map删除迭代器p指定的元素,必须指向my_map中一个真实的元素,不能等于my_map.end()。返回p之后元素的迭代器。若p指向my_map中的尾元素,则返回my_map.end()
4、获取迭代器
my_map.begin();//返回第一个元素的定位器地址
my_map.end();//返回尾元素之后元素的位置,即最后一个单元+1的指针
my_map.rbegin();//将my_map反转后的开始指针返回(其实就是原来的end()-1)
my_map.rend();//将my_map反转构的结束指针返回(其实就是原来的begin-1)5、其他方法
my_Map.size() // 返回元素数目
my_Map.empty() // 判断是否为空
my_Map.clear() // 清空所有元素 map举例应用
举例一:按照Map的关键字Key排序
map内部本身就是按序存储的(比如红黑树)。他是按照键值得大小进行排序的,也就是他自带了字典排序功能。在我们插入key-value键值对时,就会按照key的大小顺序进行存储。这也是作为key的类型必须能够进行<运算比较的原因。现在我们写了一段代码,记录颜色出现的次数,用string类型作为key,表示输入的颜色,int作为value,表示出现的次数。因此,我们的存储就是按颜色字母的字典排序储存的。参考代码如下:
#include <iostream>
#include<stdlib.h>
#include<string>
#include<map>
#include<vector>
#include<algorithm>
using namespace std;
int main(void)
{
int n;
map<string,size_t>color_balloon;
string * input_str;
while(cin>>n&&n)
{
input_str=new string[n];//为输入的颜色分配空间
for(int i=0;i<n;i++)
{
cin>>input_str[i];
++color_balloon[input_str[i]];//提取input_str[]计数器并对其加1
}
for(map<string,size_t>::iterator iter=color_balloon.begin();iter!=color_balloon.end();++iter){
cout<<iter->first<<" "<<iter->second<<endl;
}
color_balloon.clear();
delete [] input_str;
}
return 0;
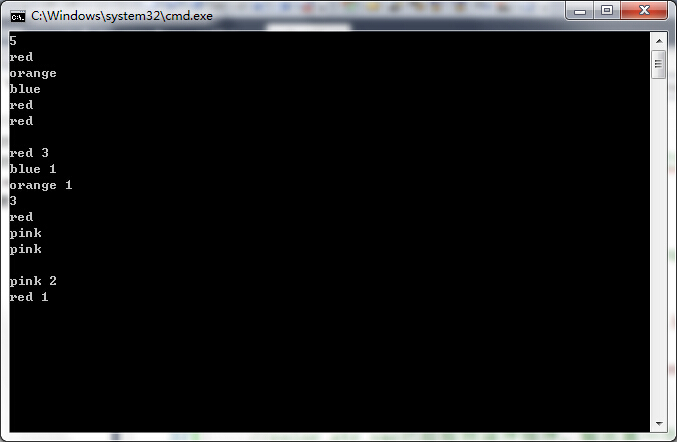
}运行结果如下:
从结果可以看出,输出的结果是按输入字符的字典顺序排序的,也就是按照首字母的先后顺序。但是有时候针对这一种情况我们想先输出出现次数最多的颜色,也就是按照map 中value值的大小先后顺序进行输出,可以不呢?下面我们就针对这种情况进行另一组拓展。
举例二:拓展用法——按照Map的值Value排序
使用value排序,我们就会想到上一篇利用STL中提供的sort算法实现,有这种思维很好,不过sort算法有个限制,利用sort算法只能对序列容器进行排序,就是线性的(如vector、deque、list、forward_list、array、string)。map是一个关联容器,属于集合容器,它里面存储的元素是pair,但是它不是线性存储的,所以利用sort不能直接和map结合进行排序。
既然不能直接用sort对map进行排序,那有没有什么方法呢?可不可以转换一下,把map中的元素放到顺序容器(vector)中,然后再对这些元素进行排序呢?这个想法看似是可行的。要对序列容器中的元素进行排序,也有个必要条件:就是容器中的元素必须是可比较的,也就是实现了<操作的。
在上一篇文章我们已经讲到sort函数排序的方式我们可以自己定义,sort默认排序是按照升序排序,那么现在我们想要先输出颜色数出现最多的,也就是按照value值得降序排序。那么我们就写一个比较函数,按照降序排序。如下:
typedef pair<string,size_t> PAIR;
//定义排序比较函数,通过value比较
bool cmp_by_value(const PAIR& lhs, const PAIR& rhs) {
return lhs.second > rhs.second;
}比较函数写好了,这样我们就能指定元素间如何进行比较。下面我们就给出按照value值比较,颜色数从多到少的顺序输出的代码如下:
#include <iostream>
#include<stdlib.h>
#include<string>
#include<map>
#include<vector>
#include<algorithm>
using namespace std;
typedef pair<string,size_t> PAIR;
//定义排序比较函数,通过value比较
bool cmp_by_value(const PAIR& lhs, const PAIR& rhs) {
return lhs.second > rhs.second;
}
int main(void)
{
int n;
map<string,size_t>color_balloon;
string * input_str;
while(cin>>n&&n)
{
input_str=new string[n];//为输入的颜色分配空间
for(int i=0;i<n;i++)
{
cin>>input_str[i];
++color_balloon[input_str[i]];//提取input_str[]计数器并对其加1
}
//把map中元素转存到vector中
vector <PAIR> color_str_vec(color_balloon.begin(),color_balloon.end());
//按降序排序
sort(color_str_vec.begin(),color_str_vec.end(),cmp_by_value);
cout<<endl;
//color_str_vec已经按照降序排序,输出第一个即为出现次数最多的一个
for(vector<PAIR>::iterator iter=color_str_vec.begin();iter!=color_str_vec.end();++iter){
cout<<iter->first<<" "<<iter->second<<endl;
}
color_balloon.clear();
delete [] input_str;
}
return 0;
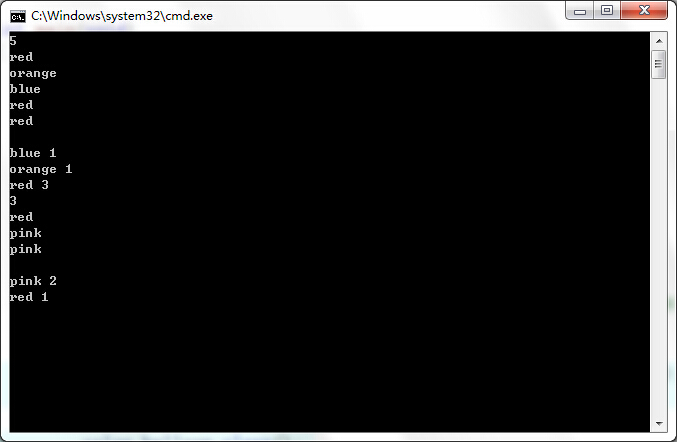
}结果如下: