参考
代码来自黄文坚的《TensorFlow实战》
深度学习之自编码器AutoEncoder
代码
########################
#基于MNIST的自编码器实现
########################
import numpy as np
import sklearn.preprocessing as prep
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#导入mnist数据集
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
#一种自适应的权重参数初始化方式
def xavier_init(fan_in,fan_out,constant=1):
low = -constant * np.sqrt(6.0 / (fan_in + fan_out))
high = constant * np.sqrt(6.0 / (fan_in + fan_out))
#从均匀分布中返回随机值
return tf.random_uniform((fan_in,fan_out),minval=low,maxval=high,dtype=tf.float32)
#对数据进行标准化,全体数据共用训练集的sacler,保持一致性
def standard_scale(X_train,X_test):
preprocessor = prep.StandardScaler().fit(X_train)
X_train = preprocessor.transform(X_train)
X_test = preprocessor.transform(X_test)
return X_train,X_test
#随机抽样得数据块
def get_random_block_from_data(data,batch_size):
#从(0,len(data)-batch_size)中获取随机的起始坐标,避免越界
start_index = np.random.randint(0,len(data)-batch_size)
return data[start_index:(start_index+batch_size)]
#定义去噪自编码类
class AdditiveGaussianNoiseAutoencoder(object):
def __init__(self,n_input,n_hidden,transfer_function=tf.nn.softplus,optimizer=tf.train.AdamOptimizer(),scale=0.1):
#输入变量
self.n_input = n_input
#隐含层节点数
self.n_hidden = n_hidden
#隐含层激活函数,默认为softplus
self.transfer = transfer_function
#高斯噪声系数
self.scale = tf.placeholder(tf.float32)
self.training_scale = scale
network_weights = self._initialize_weights()
self.weights = network_weights
self.x = tf.placeholder(tf.float32,[None,self.n_input])
#隐层输出值
self.hidden = self.transfer(tf.add(tf.matmul(self.x + scale*tf.random_normal((n_input,)),self.weights['w1']),self.weights['b1']))
#输出层的重建,无需激活函数
self.reconstruction = tf.add(tf.matmul(self.hidden,self.weights['w2']),self.weights['b2'])
#定义代价函数,平方误差函数
self.cost = 0.5*tf.reduce_sum(tf.pow(tf.subtract(self.reconstruction,self.x),2.0))
self.optimizer = optimizer.minimize(self.cost)
#全局参数初始化
init = tf.global_variables_initializer()
#定义会话
self.sess = tf.Session()
self.sess.run(init)
# 定义参数初始化函数
def _initialize_weights(self):
all_weights = dict()
all_weights['w1'] = tf.Variable(xavier_init(self.n_input, self.n_hidden))
all_weights['b1'] = tf.Variable(tf.zeros([self.n_hidden], dtype=tf.float32))
all_weights['w2'] = tf.Variable(tf.zeros([self.n_hidden, self.n_input], dtype=tf.float32))
all_weights['b2'] = tf.Variable(tf.zeros([self.n_input], dtype=tf.float32))
return all_weights
#定义计算损失cost以及执行一步训练的函数
def partial_fit(self,X):
cost,opt = self.sess.run((self.cost,self.optimizer),feed_dict={self.x:X,self.scale:self.training_scale})
return cost
#定义一个只求损失的函数
def calc_total_cost(self,X):
return self.sess.run(self.cost,feed_dict={self.x:X,self.scale:self.training_scale})
#返回自编码器隐含层的输出结果,目的是提供接口来获取抽象后的特征
def transform(self,X):
return self.sess.run(self.hidden,feed_dict={self.x:X,self.scale:self.training_scale})
#将隐含层的输出作为输入,用于复现
def generate(self,hidden=None):
if hidden is None:
hidden = np.random.normal(size= self.weights["b1"])
return self.sess.run(self.reconstruction,feed_dict={self.hidden:hidden})
#整体运行一套复原过程,包括提取高阶特征和复原数据
def reconstruction(self,X):
return self.sess.run(self.reconstruction,feed_dict={self.x:X,self.scale:self.training_scale})
##数据显示方式##
#获取隐含层权重
def getWeights(self):
return self.sess.run(self.weights['w1'])
#获取隐含层偏置
def getBiases(self):
return self.sess.run(self.weights['b1'])
#数据标准化
X_train,X_test = standard_scale(mnist.train.images,mnist.test.images)
#总样本数
n_smaples = int(mnist.train.num_examples)
#最大训练轮数
training_epochs = 20
#批大小
batch_size = 128
#每轮显示一次结果
display_step = 1
#定义编码器和训练参数
autoencoder = AdditiveGaussianNoiseAutoencoder(n_input=784,n_hidden=200,transfer_function=tf.nn.softplus,optimizer=tf.train.AdamOptimizer(learning_rate=0.001),scale=0.1)
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(n_smaples/batch_size)
for i in range(total_batch):
#随机抽样
batch_xs = get_random_block_from_data(X_train,batch_size)
#训练并计算损失
cost = autoencoder.partial_fit(batch_xs)
#计算平均损失
avg_cost += cost/n_smaples*batch_size
if epoch % display_step ==0:
print("Epoch:",'%04d'%(epoch+1),'cost=',"{:.9f}".format(avg_cost))
print("Total cost: " + str(autoencoder.calc_total_cost(X_test)))总结
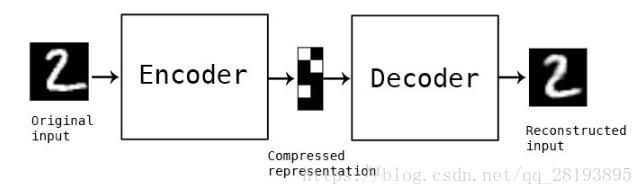
1.自编码器
自动编码器是一种数据的压缩算法,其中数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的。在大部分提到自动编码器的场合,压缩和解压缩的函数是通过神经网络实现的。
2.xavier
优秀的初始化应该使得各层的激活值和状态梯度的方差在传播过程中的方差保持一致。Xavier初始化确实保证了Glorot条件,使得激活值的方差和层数无关,反向传播梯度的方差和层数无关。推导详见深度学习之参数初始化(一)——Xavier初始化
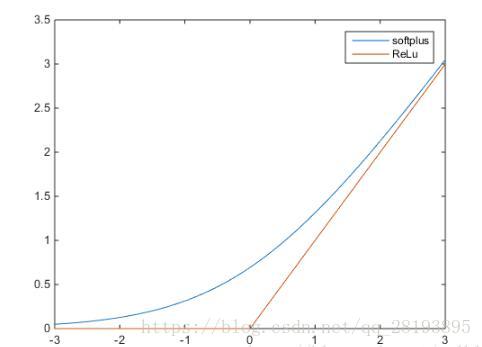
3.softplus函数
softplus函数表达式为 ,可以看作是ReLu的平滑。相比于早期的激活函数,softplus和ReLu更加接近脑神经元的激活模型。