LinkedBlockingQueue源码-JUC阻塞队列2
上篇讲过ArrayBlockingQueue源码,主要看了核心入队和出队源码基本总结了如下几点:
1)ArrayBlockingQueue是有界的阻塞队列,不接受null
2)底层数据接口是数组,下标putIndex/takeIndex,构成一个环形FIFO队列
3)所有的增删改查数组公用了一把锁ReentrantLock,入队和出队数组下标和count变更都是靠这把锁来维护安全的。
4)阻塞的场景:1获取lock锁,2进入和取出还要满足condition 满了或者空了都等待出队和加入唤醒,ArrayBlockingQueue我们主要是put和take真正用到的阻塞方法(条件不满足)。
5)成员cout /putIndex、takeIndex是共享的,所以一些查询方法size、peek、toString、方法也是加上锁保证线程安全,但没有了并发损失了性能。
6)remove(Object obj) 返回了第一个equals的Object
我们来看同为阻塞队列BlockingQueue的另个一实现类LinkedBlockingQueue原理。
这张图也是上篇博文ArrayBlockingQueue源码的直接拉过来,使用方法我就不粘贴了,也在上篇博文,这里就不贴了。
| 操作 | 抛出异常 | 特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除 | remove() | poll() | take() | poll(time, unit) |
| 检查 | element() | peek() | - | - |
LinkedBlockingQueue同样听名字也能知道它底层是链表结构。
主要的构造方法:
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
} 跟ArrayBlockingQueue区别之一
LinkedBlockingQueue构造方法可以不指定一个容量,默认赋值Integer.MAX_VALUE
它的数据结构Node:
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
private final int capacity;
private final AtomicInteger count = new AtomicInteger();
transient Node<E> head;
private transient Node<E> last;
private final ReentrantLock takeLock = new ReentrantLock();
private final Condition notEmpty = takeLock.newCondition();
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notFull = putLock.newCondition();跟ArrayBlockingQueue的区别二
LinkedBlockingQueue数据结构是单向链表
跟ArrayBlockingQueue的区别三
LinkedBlockingQueue有两把锁分别对应两个条件notEmpty和notFull
我没来看下LinkedBlockingQueue是如何使用这些属性
put()方法
public void put(E e) throws InterruptedException {
//有着阻塞队列的公共点 元素不能为空
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
//写入锁
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
//满了进入满了条件队列--单向Node(Thread.currentThread(), Node.CONDITION);
while (count.get() == capacity) {
notFull.await();
}
enqueue(node);//last = last.next = node;
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
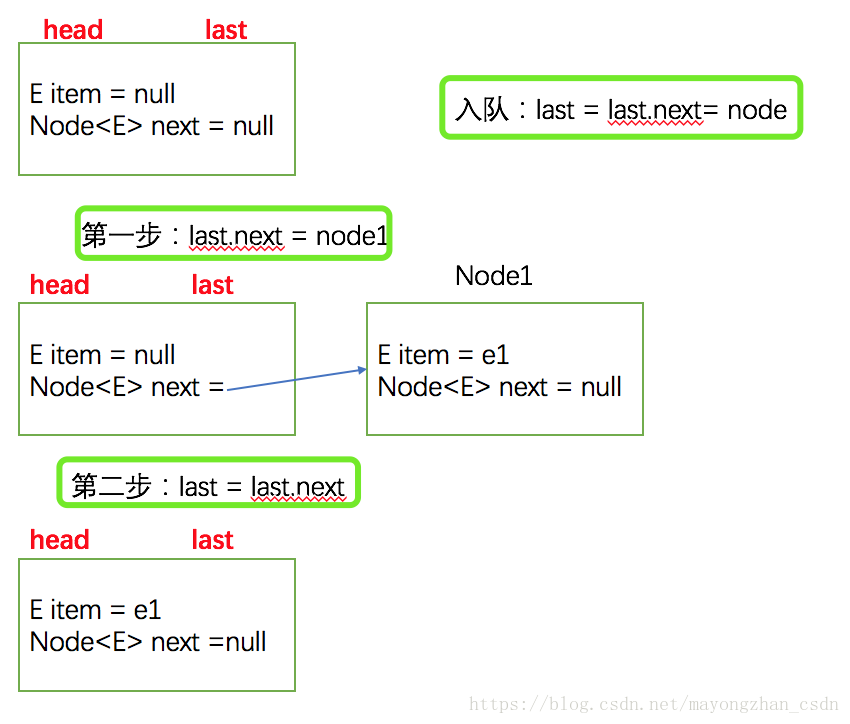
private void enqueue(Node<E> node) {
last = last.next = node;
}
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}首次入队就是如下所示的变化过程:
构造方法将head和last创建了一个Node(null)
入队last = last.next = node
有没有觉得奇怪:
按理说notFull(队列没有满)满足直接notEmpty唤醒不就行了???
但是这了为什么是notFull.signal() notEmpty.signal()
之前条件队列有张图:

这里是一把锁,一个条件
而这是两把锁,两个条件
正如上图所示,用一把锁的时候5)步骤还要进入lock.acquireQueue哪里获取锁,才能执行。
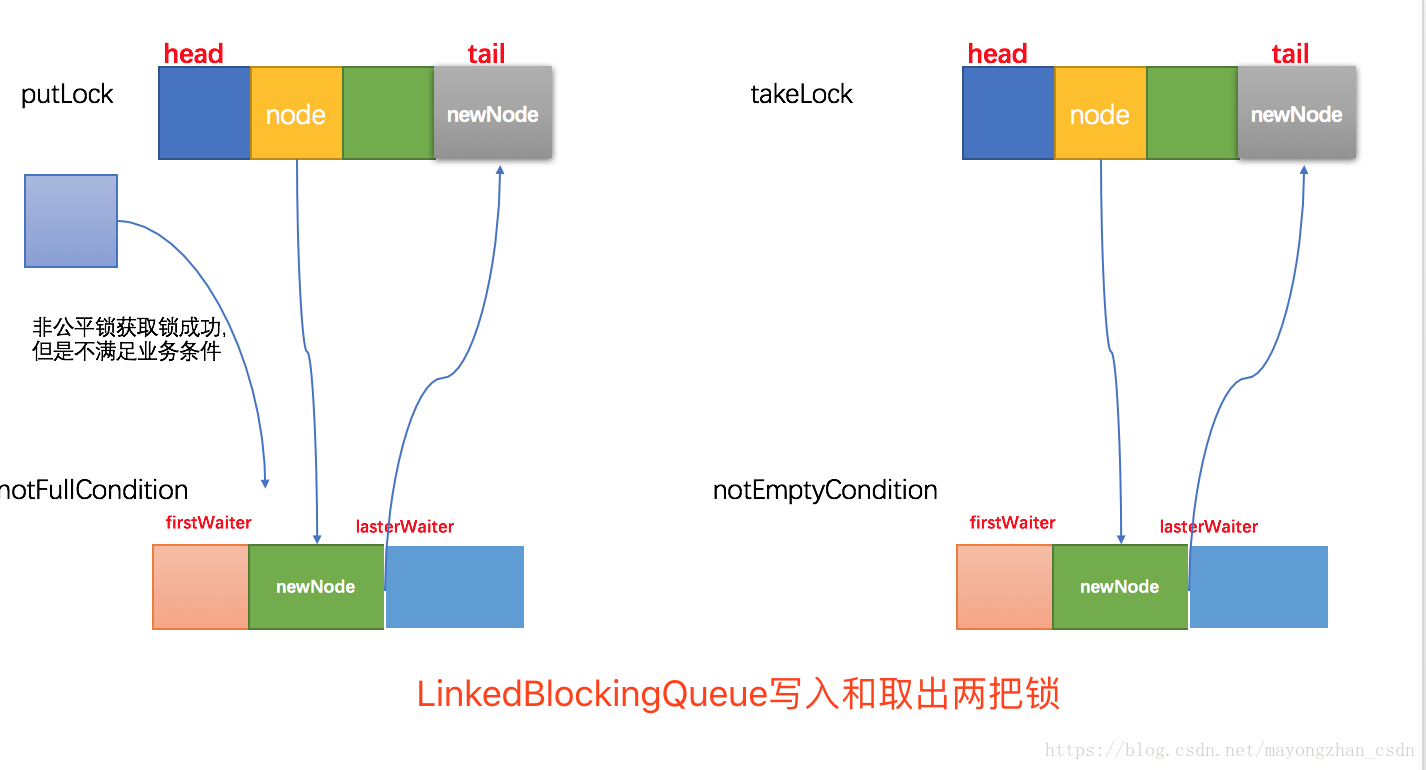
linkedBlockingQueue使用两把锁的时候不是所有的操作(put和take),
ArrayBlockingQueue使用一把锁的时候是所有的操作(put和take),
满足条件了再次进入lock.acquireQueue中继续等前面线程获取锁执行完,才能执行业务逻辑:
写的满足调价进入写的lock.acquireQueue中等
取的满足条件进入去的lock.acquireQueue中等
同一种操作(比如put)满足条件的时候减少了等待时间,提升了并发性能,ArrayBlockingQueue中只有了一把锁一个条件,所以相比于LinkedBlockingQueue来说高并发读和写的场景下会性能会低一些
当然你有可能有这样的疑虑:
ArrayBlockingQueue底层是数组,查询速度应该会很快,删除更慢
LiknedBlockingQueue底层是链表,删除速度应该会快,查询会慢
这话本身都是没问题的,但是BlockQueue是生产者和消费者模型,主要用的场景就是写入和取出(删除),所以LinkedBlockingQueue性能更胜一筹,不仅锁的性能,而且底层数据结构和应用场景来说都证明这点。
我们前面写过读写锁,你是否有考虑可以用到这里???、
NO
读写锁是真正的读和写,是修改和查询
BlockQueue是写入和取出,都是修改
take()方法觉得没什么可写的,基本区别就是这样,文章就到这里。