本文是论文 Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering 的笔记
摘要
在本文中,我们分析了句子对建模的几种神经网络设计(及其变体), 并在八个数据集中比较它们的性能,包括释义识别、语义文本相似性、自然语言推理和问题回答任务。 尽管这些模型中的大多数都声称具有最先进的性能,但原始报告通常只报告一个或两个选定的数据集。 我们提供了一个系统的研究,并且表明 (i) 通过LSTM编码上下文信息和句子间的交互是至关重要的,(ii) Tree-LSTM不像以前所声称的那么有帮助,但令人惊讶地改进了Twitter数据集上的性能,(iii) 对于较大的数据集,增强序贯推理模型(Chen等,2017)是迄今为止最好的,而当两者间的互动模型(He and Lin,2016)在数据较少时达到最佳性能。 我们将我们的实现作为开源工具包发布。
一、介绍
句子对建模是许多NLP任务的基础技术,包括以下内容:
语义文本相似性 (Semantic Textual Similarity) ,用于度量文本配对片段的基本语义中的等价程度。
释义识别 (Paraphrase Identification,PI),识别两个句子是否表达相同的含义。
- 自然语言推理(Natural Language Inference),它涉及假设是否可以从前提推断出来,需要理解假设和前提之间的语义相似性。
- 问答 (Question Answering),根据它们与原始问题的相似程度,可近似为候选答案句或短语的排名。
- 机器理解 (Machine Comprehension),它需要在段落和问题之间进行句子匹配,指出包含答案的文本区域。
传统上,研究人员必须针对每项任务制定不同的方法。现在,神经网络可以通过端到端的训练来执行具有相同体系结构的所有上述任务。各种神经模型已经为句对建模任务宣布了最新的结果,然而,他们经过精心设计并在选定的(通常是一个或两个)数据集上进行评估,以证明模型的优越性。研究问题如下:它们在其他任务和数据集上表现良好吗?多少性能增益是由于某些系统设计选择和超参数优化?
为了回答这些问题并更好地理解不同的网络设计,我们系统地分析并比较了跨多个任务和多个领域的最新神经模型。也就是说,我们在同一个PyTorch平台上实现了五种模型及其变体,它们分别是InferSent model (Conneau et al., 2017), Shortcut-stacked Sentence Encoder Model (Nie and Bansal, 2017), Pairwise Word Interaction Model (He and Lin, 2016), Decomposable Attention Model (Parikh et al., 2016), and Enhanced Sequential Inference Model (Chen et al., 2017)。它们代表了两种最常见的方法:句子编码模型,即先学习单个句子的向量表示,然后通过计算向量的距离来表示句子之间的语义关系;句子对交互模型,即使用某种词语对齐机制 (比如注意力机制) 然后汇总句子间的交互。我们专注于确定重要的网络设计,并通过定量测量和深入分析提出一系列发现,其中包括 (i) 纳入句子间的交互至关重要; (ii) Tree-LSTM不如以前声称的那么有帮助,但令人惊讶地提高了Twitter数据的性能;(iii) 增强的顺序推理模型对于较大的数据集具有最一致的高性能,而成对词互动模型在较小的数据集上表现更好,快捷方式堆叠句子编码器模型是Quora语料库的最佳执行模型。我们将我们的实现作为工具包发布给研究团体。
二、句子对建模的一般框架
已经提出了各种神经网络用于句对建模,所有这些网络分为两种类型的方法。句子编码方法将每个句子编码为一个固定长度的向量,然后直接计算句子相似度。这种类型的模型在网络设计的简单性和其他NLP任务的普遍性方面具有优势。句对交互方法将词对齐和句对之间的交互考虑在内,并且在对域内数据进行训练时经常表现出更好的性能。在这里,我们概述了在相同的一般框架下的两种神经网络:
输入嵌入层
将词的向量表示作为输入,其中最经常使用预训练词嵌入,例如GloVe或Word2vec。一些工作使用了专门用于短语或句子对的嵌入。上下文编码层
将词上下文和序列顺序考虑进来,以得到更好的向量表示。该层通常使用CNN、LSTM、recursive neural network、highway network。句子编码模型将在这一步停止,直接使用编码得到的向量通过向量距离来计算语义相似度。交互和注意力层
使用编码层的输出计算字对 (或n-gram对) 交互。这是交互-汇总模型的关键组件。在PWIM模型中(He和Lin,2016), 相互作用是通过余弦相似度,欧氏距离和向量的点积来计算的。不同的模型在不同的交互中赋予不同的权重,主要模拟两个句子之间的词语对齐。因为两个句子之间的语义关系在很大程度上取决于对齐块的关系,所以对齐信息对句子对建模很有用,如SemEval-2016可解释语义文本相似度任务所示 (Agirre et al., 2016) 。输出分类层
使用CNN或MLP来提取关注对齐中的语义级特征,并应用softmax函数来预测每个类的概率。
三、句子对建模的表示模型
作者列举了近年来比较火的句子对模型,包括两大类,即上文提到的句子编码模型、交互-汇总模型。
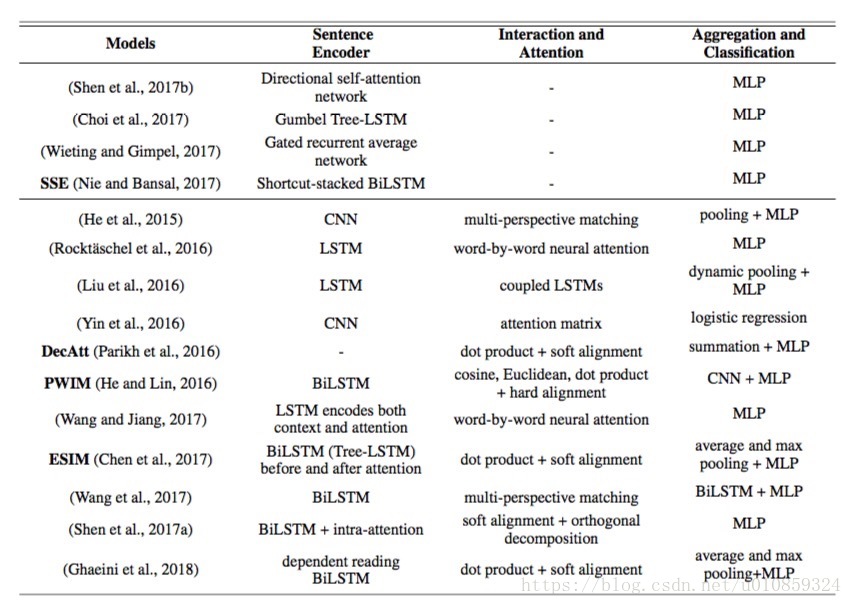
表格中的上半部分是句子编码模型,下半部分是句子对交互模型。
下图给出了一种句子编码模型的框架
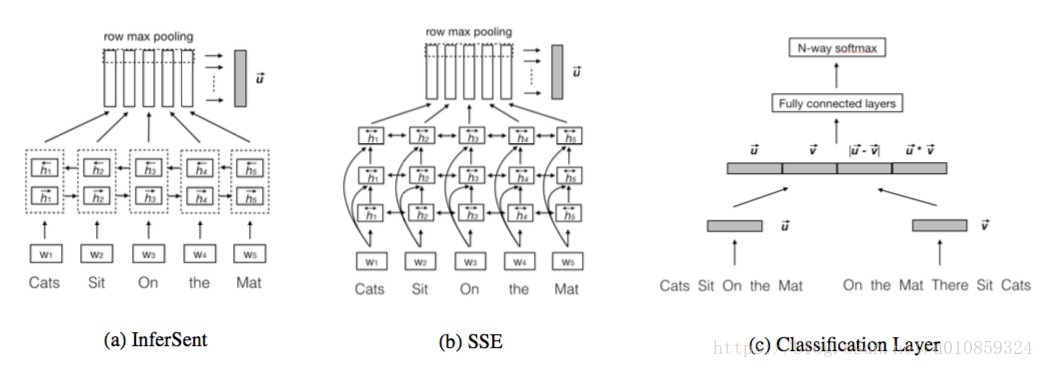
(a)、(b)是两种句子编码的方式,(b)就是把(a)中的LSTM的单层替换成多层,而且加了highway network。(c)是在(a)或(b)得到两个句子的向量表示
、
之后后接的一个classifiation layer。
3.1 Bi-LSTM Max-pooling Network (InferSent)
参考论文 Pairwise Word Interaction Modeling with Deep Neural Networks for Semantic Similarity Measurement
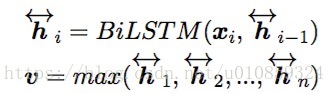
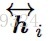
3.2 Shortcut-Stacked Sentence Encoder Model
下图是模型框架
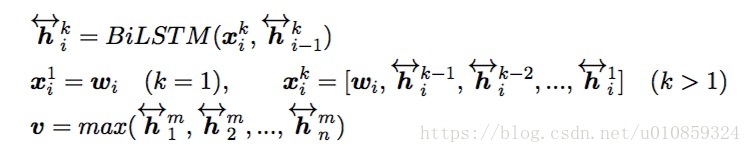
其中,
是Bi-LSTM的第
层是时刻
的输入,它是前面所有layer输出的组合,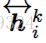
3.3 The Pairwise Word Interaction Model (PWIM)
参考论文 Pairwise Word Interaction Modeling with Deep Neural Networks for Semantic Similarity Measurement
模型架构如下
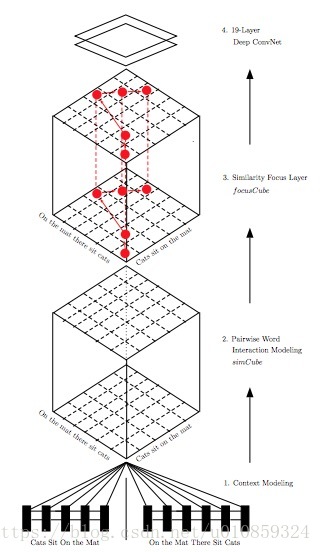
模型由四个部分组成
1)Bi-LSTM作为context-modeling
每个时刻的输出即为该时刻的双向hidden state做concatenation的结果,作为对应时刻word的representation。
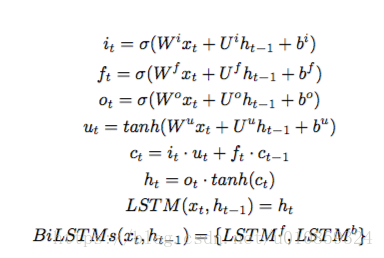
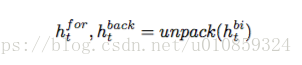
其中,
、
分别是时刻
正向、反向的hidden state。
2)pairwise word interaction modeling
给两个句子,让你判断两个句子像不像,你怎么做?你通常会两个分析句子词语之间的关系。
示意图如下
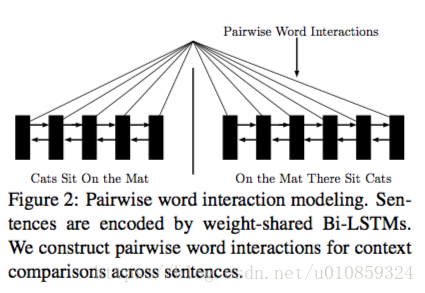
我们定义一个比较单元,去计算任意两个hidden state的关系大小,记
、
为两个hidden state,那么它们的关系定义为
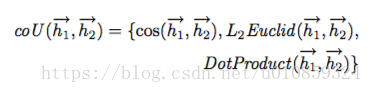

其中,
为第一个句子位置
的双向hidden state,
为第二个句子位置
的双向hidden state。可以把
理解为一个长方体,高度为13,上图中只体现12个,剩下一个是padding indicator (可以简单理解为intercept),在长方体的每一个高度上是一个截面,这个截面的尺寸是句子1和句子2长度的乘积,即
,该截面内装的是
similarity 或
distance或dort product度量形式的word pair similarity结果,这就是为什么
在赋值的时候三三的一组进行。注意到这里计算两个sentence的word之间的关系时用的是LSTM的hidden state,背后已经把词序信息纳入 (因为hidden state包含了顺序),而不是只考虑独立的每一个word。
3)Similarity Focus Layer
句子内部不同的词的重要性是不一样的,两个句子间重要的word pair interation对于句子相似度的计算贡献更大,这些word pair应该得到更多的重视,所以我们开发了similarity forcus layer,它可以识别重要的word interactions并提高它们的权重。下图中,矩阵中的每一个元素都是对相应word pair的iteraction大小的衡量,黑点表示iteraction大,而空白表示iteraction小。
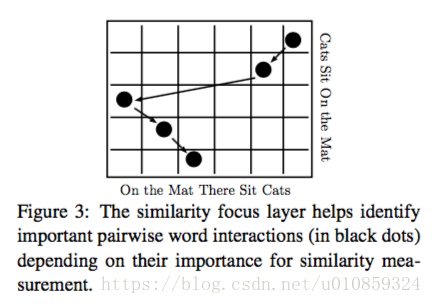
那么similarity focus layer是什么样的呢?similarity focus layer的输入是
,
下面给出的Algorithm 2将两种相似度的度量考虑进去,即
similarity和
distance。

5-11行是基于
similarity的运算,15-23行是基于
similarity的运算。
怎么理解Algorithm 2 ?
这个函数参数是
和
,
是按倒叙排序,所以猜测
是依word pair interaction的大小依次返回pair interaction对应的word pair index (其实在算
的时候你可以建立一个word pair index—word pair interation的映射关系词典,然后
这个函数就可以去调用这个词典,依次返回word pair index)。循环内部的
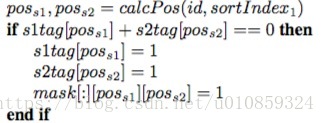
使得sent1中的每一个word只会与sent2的一个word高度相关,即mask相应的位置为0(其余位置为0.1),这比较像是hard attention的做法。
矩阵装的就是weight,其实Algorithm 2 的第11行mask 的第一维index 应该是10,第21行mask的第一维的index应该是11,也就是说这里只列聚了10和11两个横截面,其他横截面的计算方法相同。
在得到
后将
和
做element-wise的点乘,即为
。
4)Similarity Classification with Deep Convolutional Neural Networks
可以视作一个channel为13的image,这样以来最后一层就可以用CNN来做分类。
CNN的框架如下

conv层都是用3*3的filter,因为这种尺寸的filter是能够抓取左/右、上/下和中心等相对位置的最小filter。conv层stride为1,pad为1,这么做可以使得生成的feature map的尺寸与原始image相同。CNN的输入是
,
channel数总是13,但横截面的尺寸却是随着两个句子sent1 和 sent2的长度变化而变化,所以为了使得CNN的输入总是一致,这里对
做zero padding,使得
的尺寸总是13*32 32 或 13 48 * 48 ,如果原始长度超过了这个,则进行截取。
3.4 The Decomposable Attention Model (DecAtt)
参考论文 A Decomposable Attention Model for Natural Language Inference
这是一种attention模型,考虑两个句子
、
,长度分别为
、
,两个句子中两个word的embedding分别为
、
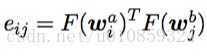
其中
是一个feedford, 然后alinment的计算如下,

紧接着又是一个network
,
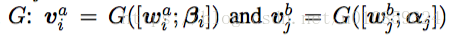
得到 {
}、{
},然后将它们加和、拼接到一起,用来做分类。
3.5 The Enhanced Sequential Inference Model (ESIM)
论文 Enhanced LSTM for Natural Language Inference
和DecAtt很像,考虑了一些词的特征信息,用了Tree-LSTM(不知道是什么鬼)。
四、实验和分析
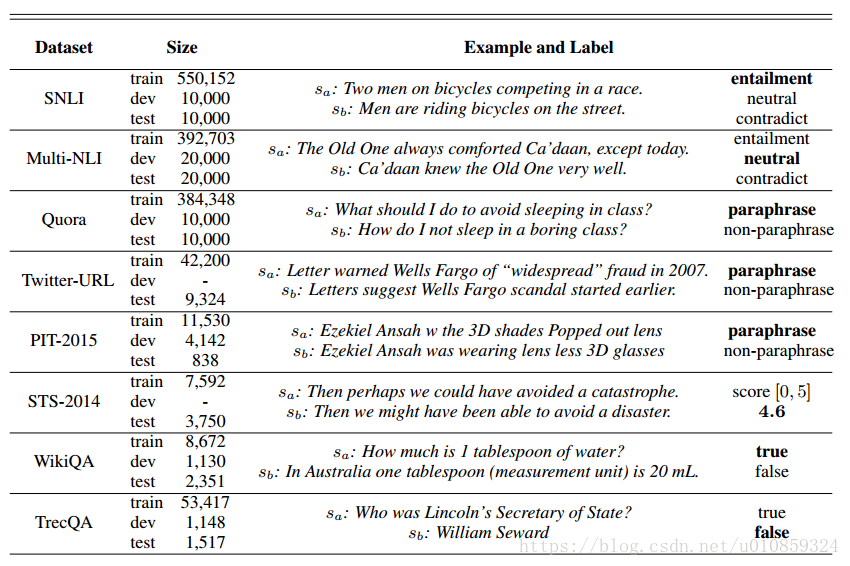
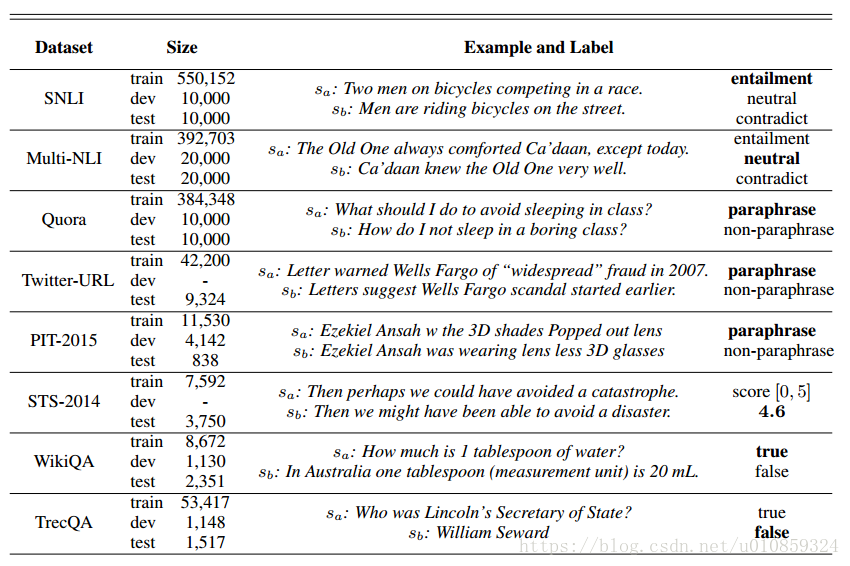
4.1 数据
4.2 结果
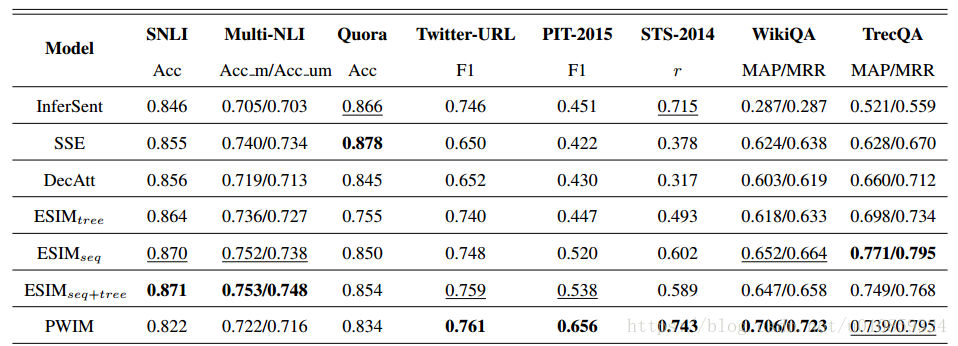
4.3 分析
从结果上看,作者实现的效果还是很厉害的,基本上跟原文章声明的不相上下,当然由于不是针对特定任务进行特别优化,所有效果还是有一点点差的,但基本上可以认为是实现了原来的效果,而且作者也发现了一些有意思的现象,例如:表现最好的就是ESIM,个人感觉这里面加入了很多次本身的一些信息,例如近义词,反义词,上下位信息等,这些信息其实对句子语义理解十分重要。
参考文献:
论文阅读笔记