有些网站需要登录后才能爬取到有用的信息,Scrapy先模拟登录,再进行信息爬取。
登录实质
理解登录的实质,跟踪一次登录操作
http://example.webscraping.com/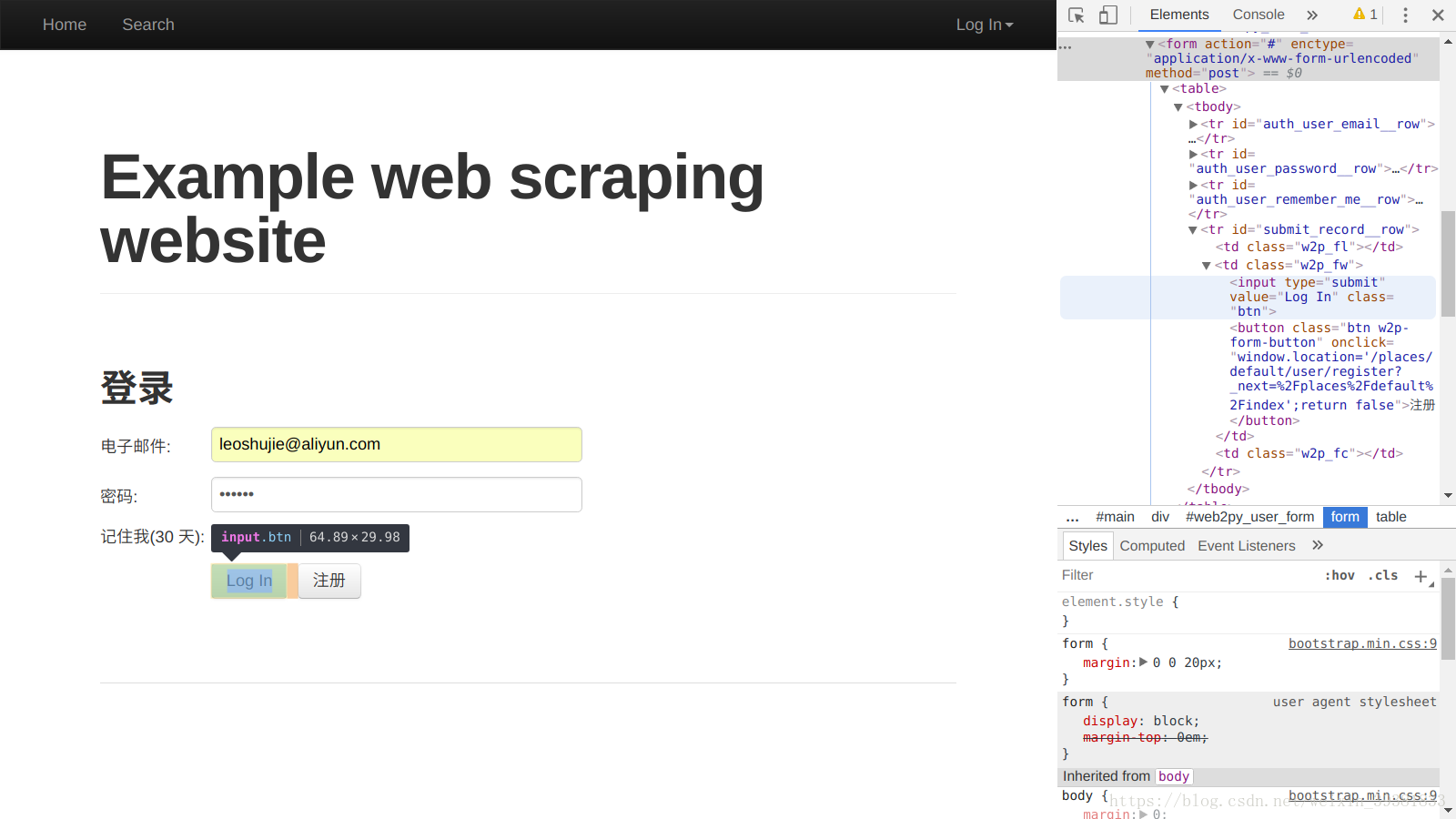
页面的表单对应的HTML的 《form》,log in会根据form元素的内容发送一个http请求给服务器
- method决定请求方法 post
- action 请求的url (#为当前页面)
- enctype 编码类型
《input》表单数据的内容
再来看《form》中的《input》元素:name属性为‘email’和‘password’的两个input
- 在《div style=’display:none’》中包含了3个隐藏的《input type=”hidden”》
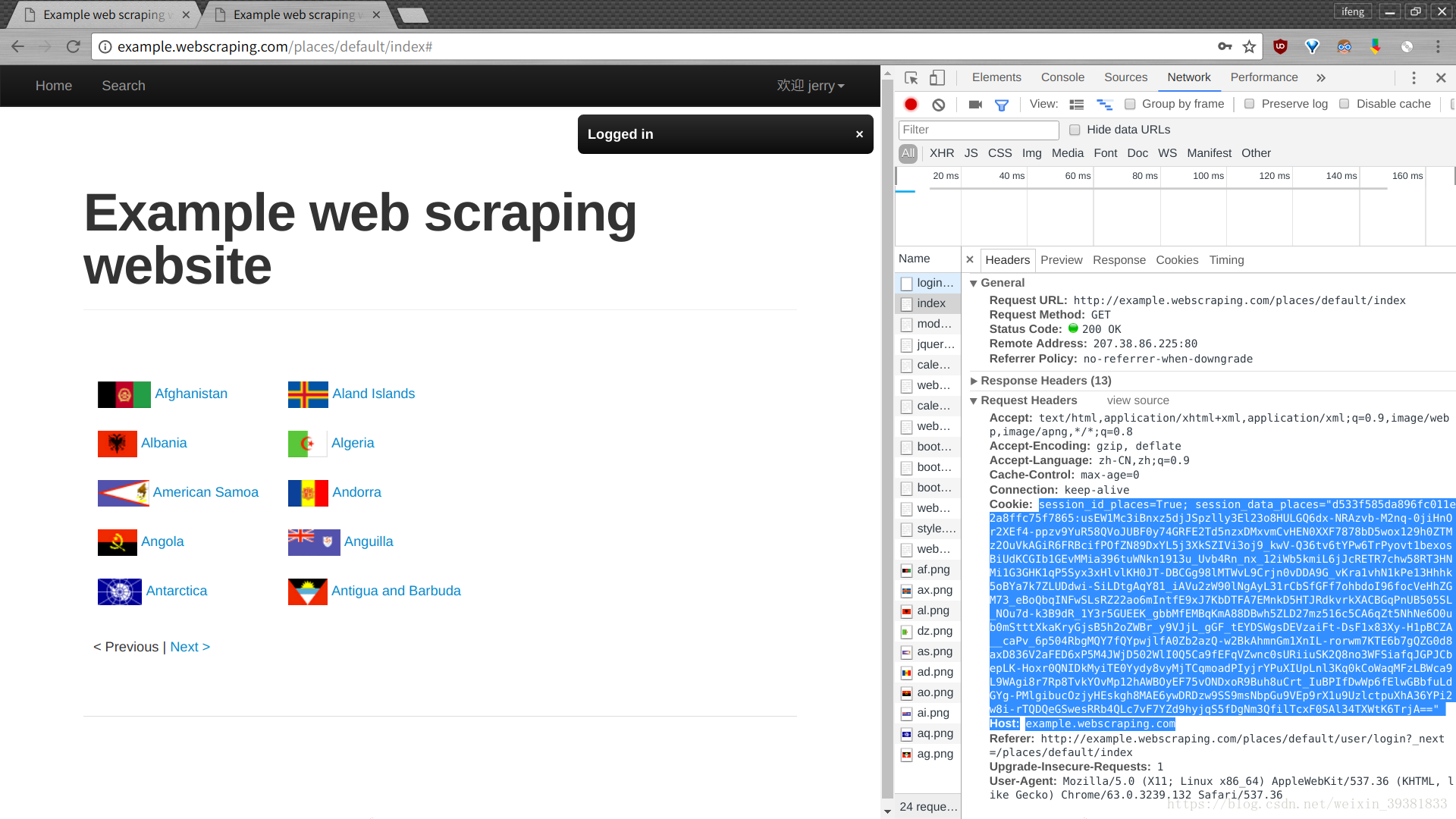
分析请求信息
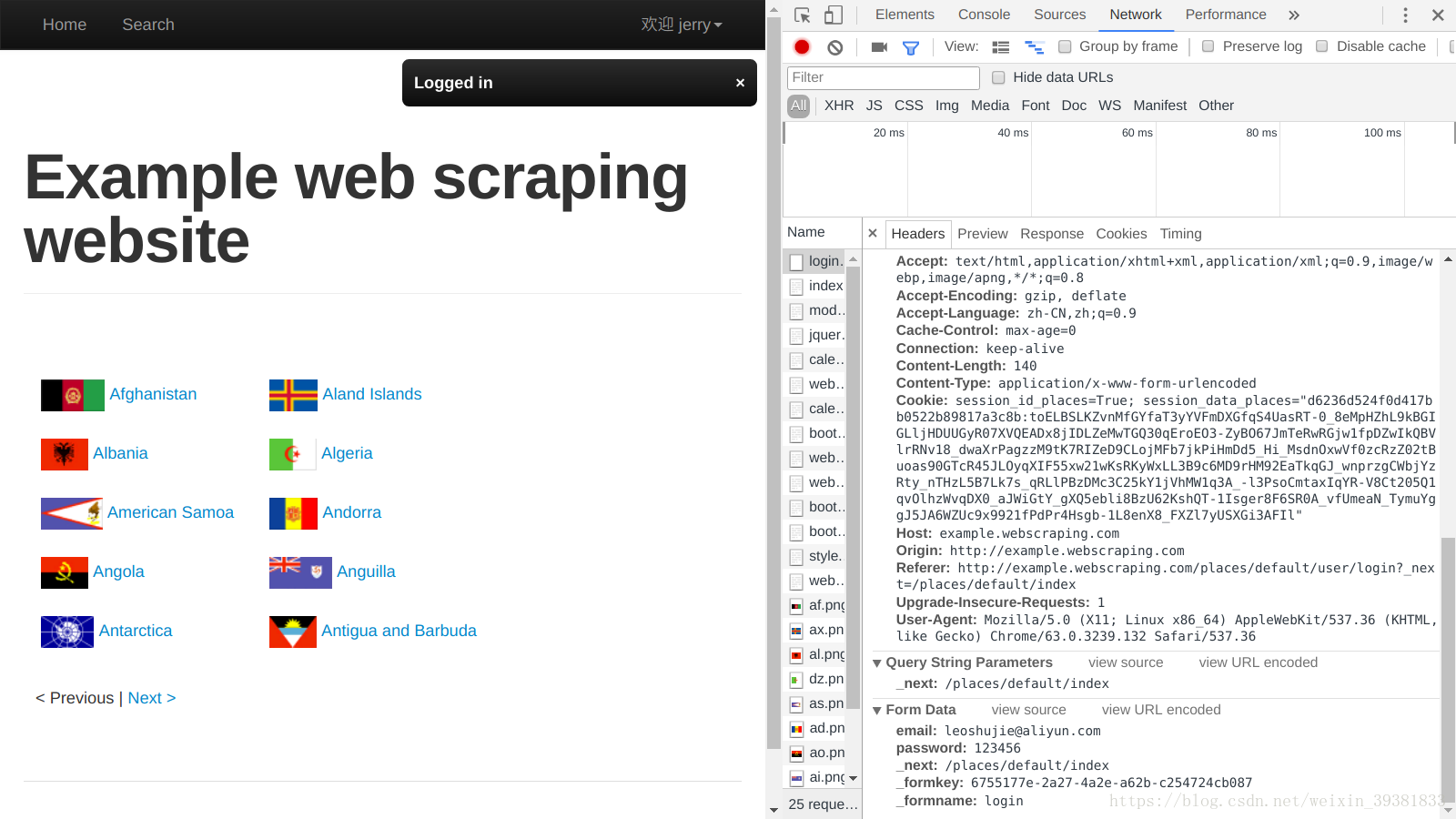
从图中可以看出,捕获到很多http请求,其中第一个就是发送登录表单的post请求,可以找到url、请求方法(method)、请求头部(header)、表单数据(form data)等信息
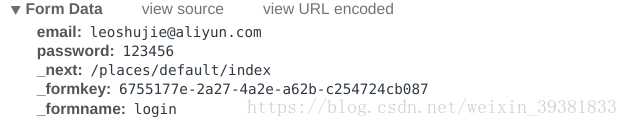
form data中的数据
表单数据由多个键值对构成,每个键值对对应一个input,上图中并不是实际的POST正文(count),这样的显示方式只是为了方便用户查看。点击view source,可以看到实际的POST正文。这样显示只是未来方便查看。
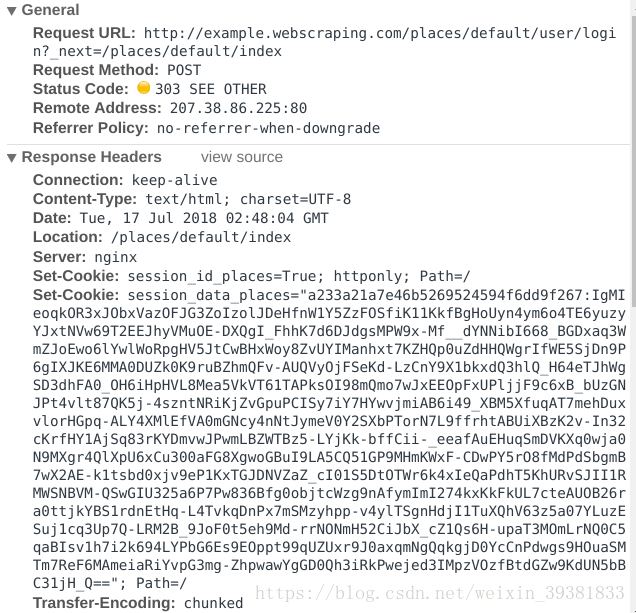
分析相应信息
Set-Cookie:网站服务器保存的cookie
Status Code:303 SEE OTHER :303代表重定向 读取location字段,再发送一个get请求
观察request头部的信息,它携带了之前POST请求获取的cookie信息,最终浏览器用该请求相应了html文档刷新了页面。

Scrapy模拟登录
使用FormResquset
前期讲解了登录的实质,核心是向服务器发送含有登录表单数据的HTTP请求(通常是post).Scrapy提供了一个FormRequest类(Request的子类),专门用于构造含有表单数据的请求,FormRequest的构造方法有一个Formdata参数,接收字典形式的表单数据。接下来,我们在scrapy shell环境下演示用FormRequest模拟登录。
首先爬取登录页面信息
scrapy shell http://example.webscraping.com/user/login上面已经分析过了,表单数据对应包含的信息、账号和密码信息,再加三个隐藏中的信息。先把这些信息收集到一个字典中,然后使用这个表单数据字典构造FormRequest对象:
#先提取3个隐藏<input>中包含的信息,它们在<div style="dispaly:none;">中
sel = response.xpath('//div[@style]/input')
#构造表单数据字典
fd = dict(zip(sel.xpath('./@name').extract(),sel.xpath('./@value').extract()))
#填写账号和密码信息
fd['email'] = '******'
fd['password'] = '********'
from scrapy.http import FormRequest
requset = FormResquset('http://example.webscrapying.com/user/login',formdata = fd)以上直接构造FormRequest对象的方式,还有一种更加简单的方式,即调用FormRequest的from_response方法。调用时需要传入一个response对象作为第一个参数,该方法会解析Response对象所包含页面的《form》元素,帮助用户创建FormRequest对象,并将隐藏《input》中的信息自动填充表单数据。这方法只需要通过formdata参数填写账号密码即可
这里写代码片