Hadoop作业流调度系统基本功能
Oozie基本架构
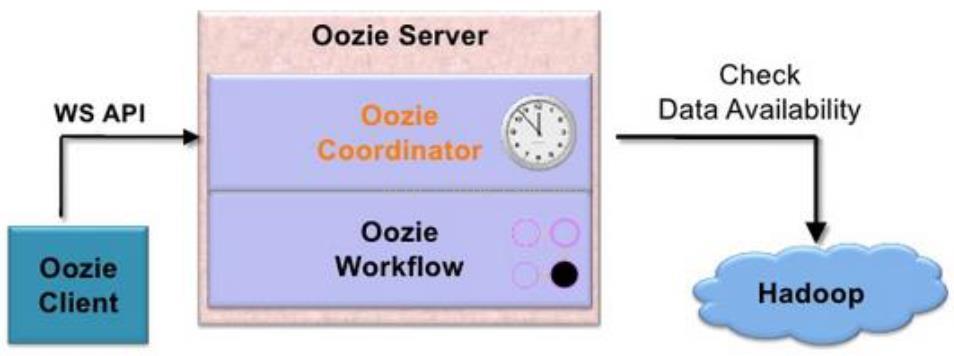
Oozie 使用方式
Oozie基本概念
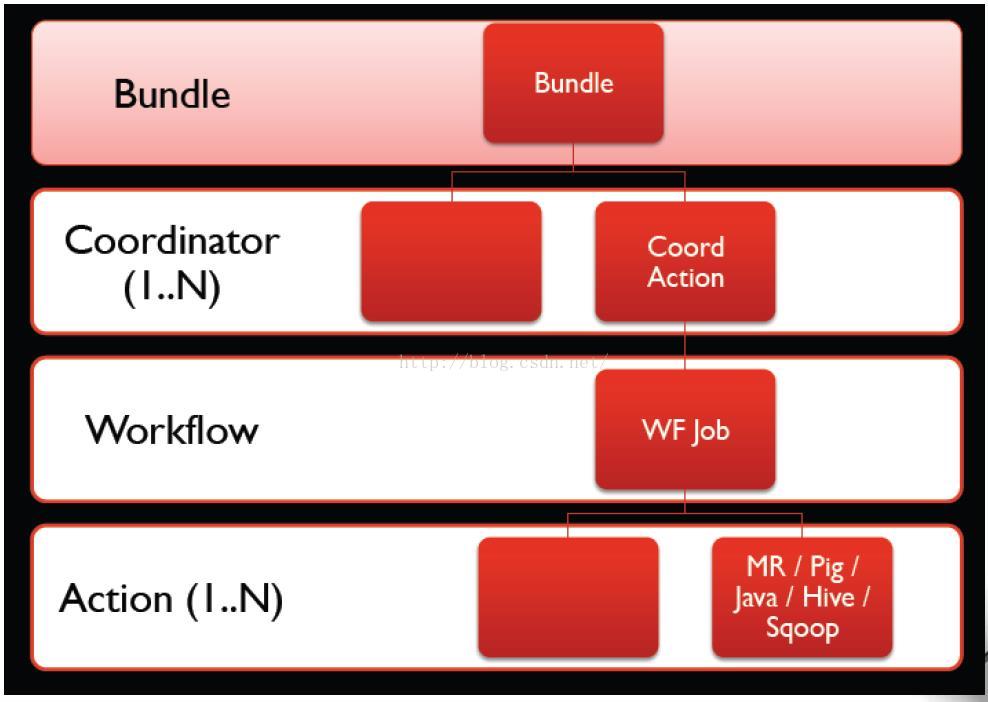
Oozie 层次结构
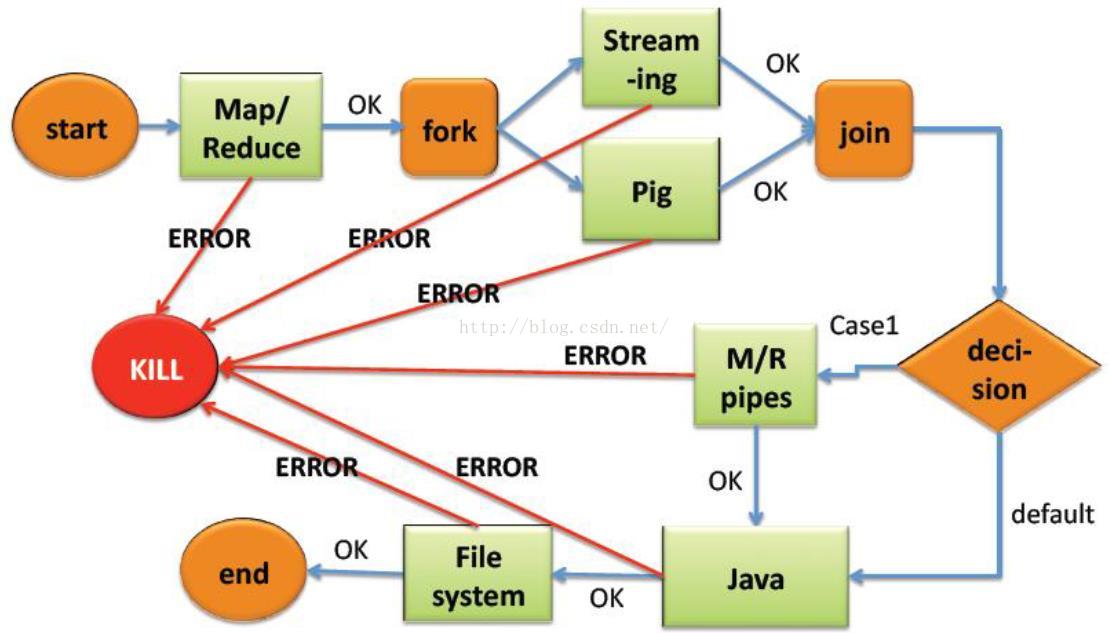
Oozie Action
Oozie 控制流
Coordinator
对常见作业类型进行调度
MapReduce(
Java、Streaming等)作业
Hive作业
Pig作业
Shell ….
Oozie运行流程
Oozie CLI
JAVA API
REST API
WEB UI(只读)
作业流由一组行为节点(Hadoop MR作业、Hive作业等)构成,且这些节点通过控制流节点相连;
控制流节点定义了工作流的起始与结束,并控制着工作流的执行路径;
行为节点包含一个计算/处理任务,包括:Hadoop map-reduce,
HDFS, Pig, SSH, HTTP, eMail等
Oozie工作流是通过hPDL语言(一种XML过程定义语言)编写的。
支持Hadoop map-reduce, HDFS, Pig, SSH, HTTP, eMail等;
可设置重试次数。
定期执行一个工作流;
数据准备完毕后执行一个工作流。
依赖关系配置
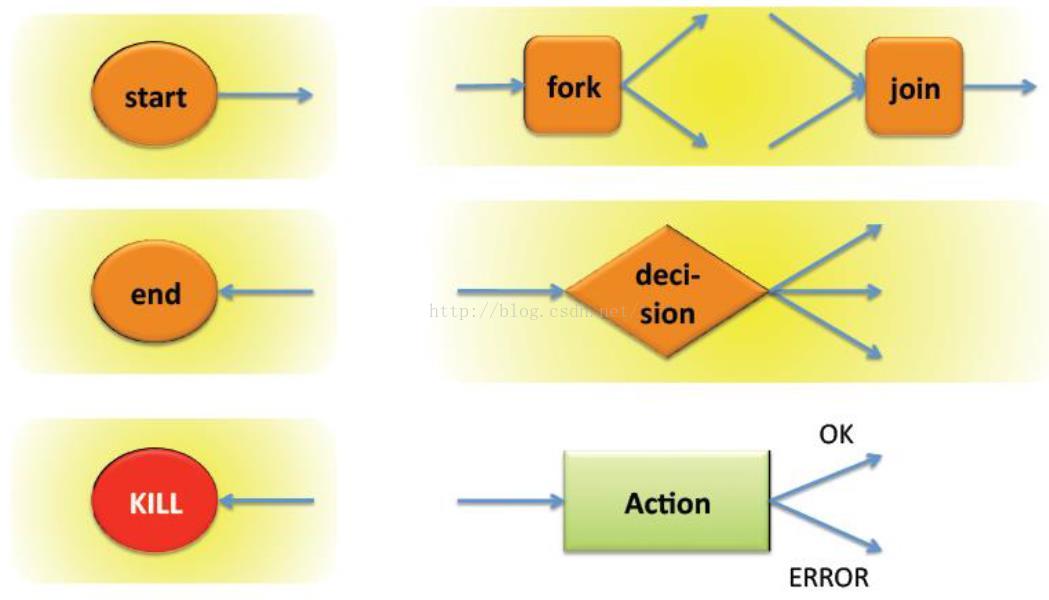
控制节点包括start、end、kill、decision、fork、join。其中start、end、kill代表了工作流的起始及工作流执行逻辑(路径),如decision、fork、join
节点名称必需复合 [a-zA-Z][\-_a-zA-Z0-0]* ,最大20个字符;
start控制节点
此节点是工作流任务的入口点,工作流定义必须有一个start节点
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<start to="[NODE-NAME]"/>
...
</workflow-app>
例:
<workflow-app name="foo-wf" xmlns="uri:oozie:workflow:0.1">
...
<start to="firstHadoopJob"/>
...
</workflow-app>
end 节点
此节点是工作流执行成功的节点。当工作流有多个任务执行,其中有一个到达end节点,其它任务会被kill掉,但结果是成功的。工作流定义必须有一个end节点
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<end name="[NODE-NAME]"/>
...
</workflow-app>
例:
<workflow-app name="foo-wf" xmlns="uri:oozie:workflow:0.1">
...
<end name="end"/>
</workflow-app>
kill节点
此节点,允许工作流任务kill自己,当工作流遇到错误,会执行kill节点。如果有多个工作流任务,其中有一个先到达了kill节点,其它任务也会被kill掉,整个任务是失败的。工作流定义可以有零个或多个kill节点
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<kill name="[NODE-NAME]">
<message>[MESSAGE-TO-LOG]</message>
</kill>
...
</workflow-app>
message 元素的内容会记录工作流任务被kill的原因
例:
<workflow-app name="foo-wf" xmlns="uri:oozie:workflow:0.1">
...
<kill name="killBecauseNoInput">
<message>Input unavailable</message>
</kill>
...
</workflow-app>
decision节点
此节点允许根据条件选择不同的执行路径,比较像swith-case表达式,通过断言来决定执行哪个路径,switch-case建议有一个default,以免出现错误。断言是JSP Expression Language(EL)表达式
相当于if else,比如A任务的输出数据大小是1G,B任务后续处理, 如果输出大小是100M,C任务后续处理
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<decision name="[NODE-NAME]">
<switch>
<case to="[NODE_NAME]">[PREDICATE]</case>
...
<case to="[NODE_NAME]">[PREDICATE]</case>
<default to="[NODE_NAME]"/>
</switch>
</decision>
...
</workflow-app>
例:
<workflow-app name="foo-wf" xmlns="uri:oozie:workflow:0.1">
...
<decision name="mydecision">
<switch>
<case to="reconsolidatejob">
${fs:fileSize(secondjobOutputDir) gt 10 * GB}
</case>
<case to="rexpandjob">
${fs:filSize(secondjobOutputDir) lt 100 * MB}
</case>
<case to="recomputejob">
${ hadoop:counters('secondjob')[RECORDS][REDUCE_OUT] lt 1000000 }
</case>
<default to="end"/>
</switch>
</decision>
...
</workflow-app>
fork & join节点
fork节点把一个执行路径分发成多个并发执行路径
join节点一直等待,直到所有的fork节点执行路径到达join节点
fork&join节点必须成对出现
实际场景依赖关系可能很复杂, 比如 Z任务依赖A B C D ,Y任务依赖A B C E ,那么需要两对fork join,A B C 会重复出现
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<fork name="[FORK-NODE-NAME]">
<path start="[NODE-NAME]" />
...
<path start="[NODE-NAME]" />
</fork>
...NAME
<join name="[JOIN-NODE-NAME]" to="[NODE-NAME]" />
...
</workflow-app>
例:
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1">
...
<fork name="forking">
<path start="firstparalleljob"/>
<path start="secondparalleljob"/>
</fork>
<action name="firstparallejob">
<map-reduce>
<job-tracker>foo:9001</job-tracker>
<name-node>bar:9000</name-node>
<job-xml>job1.xml</job-xml>
</map-reduce>
<ok to="joining"/>
<error to="kill"/>
</action>
<action name="secondparalleljob">
<map-reduce>
<job-tracker>foo:9001</job-tracker>
<name-node>bar:9000</name-node>
<job-xml>job2.xml</job-xml>
</map-reduce>
<ok to="joining"/>
<error to="kill"/>
</action>
<join name="joining" to="nextaction"/>
...
</workflow-app>
节点名称必需复合 [a-zA-Z][\-_a-zA-Z0-0]* ,最大20个字符;
start控制节点
此节点是工作流任务的入口点,工作流定义必须有一个start节点
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<start to="[NODE-NAME]"/>
...
</workflow-app>
例:
<workflow-app name="foo-wf" xmlns="uri:oozie:workflow:0.1">
...
<start to="firstHadoopJob"/>
...
</workflow-app>
end 节点
此节点是工作流执行成功的节点。当工作流有多个任务执行,其中有一个到达end节点,其它任务会被kill掉,但结果是成功的。工作流定义必须有一个end节点
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<end name="[NODE-NAME]"/>
...
</workflow-app>
例:
<workflow-app name="foo-wf" xmlns="uri:oozie:workflow:0.1">
...
<end name="end"/>
</workflow-app>
kill节点
此节点,允许工作流任务kill自己,当工作流遇到错误,会执行kill节点。如果有多个工作流任务,其中有一个先到达了kill节点,其它任务也会被kill掉,整个任务是失败的。工作流定义可以有零个或多个kill节点
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<kill name="[NODE-NAME]">
<message>[MESSAGE-TO-LOG]</message>
</kill>
...
</workflow-app>
message 元素的内容会记录工作流任务被kill的原因
例:
<workflow-app name="foo-wf" xmlns="uri:oozie:workflow:0.1">
...
<kill name="killBecauseNoInput">
<message>Input unavailable</message>
</kill>
...
</workflow-app>
decision节点
此节点允许根据条件选择不同的执行路径,比较像swith-case表达式,通过断言来决定执行哪个路径,switch-case建议有一个default,以免出现错误。断言是JSP Expression Language(EL)表达式
相当于if else,比如A任务的输出数据大小是1G,B任务后续处理, 如果输出大小是100M,C任务后续处理
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<decision name="[NODE-NAME]">
<switch>
<case to="[NODE_NAME]">[PREDICATE]</case>
...
<case to="[NODE_NAME]">[PREDICATE]</case>
<default to="[NODE_NAME]"/>
</switch>
</decision>
...
</workflow-app>
例:
<workflow-app name="foo-wf" xmlns="uri:oozie:workflow:0.1">
...
<decision name="mydecision">
<switch>
<case to="reconsolidatejob">
${fs:fileSize(secondjobOutputDir) gt 10 * GB}
</case>
<case to="rexpandjob">
${fs:filSize(secondjobOutputDir) lt 100 * MB}
</case>
<case to="recomputejob">
${ hadoop:counters('secondjob')[RECORDS][REDUCE_OUT] lt 1000000 }
</case>
<default to="end"/>
</switch>
</decision>
...
</workflow-app>
fork & join节点
fork节点把一个执行路径分发成多个并发执行路径
join节点一直等待,直到所有的fork节点执行路径到达join节点
fork&join节点必须成对出现
实际场景依赖关系可能很复杂, 比如 Z任务依赖A B C D ,Y任务依赖A B C E ,那么需要两对fork join,A B C 会重复出现
语法:
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.1">
...
<fork name="[FORK-NODE-NAME]">
<path start="[NODE-NAME]" />
...
<path start="[NODE-NAME]" />
</fork>
...NAME
<join name="[JOIN-NODE-NAME]" to="[NODE-NAME]" />
...
</workflow-app>
例:
<workflow-app name="sample-wf" xmlns="uri:oozie:workflow:0.1">
...
<fork name="forking">
<path start="firstparalleljob"/>
<path start="secondparalleljob"/>
</fork>
<action name="firstparallejob">
<map-reduce>
<job-tracker>foo:9001</job-tracker>
<name-node>bar:9000</name-node>
<job-xml>job1.xml</job-xml>
</map-reduce>
<ok to="joining"/>
<error to="kill"/>
</action>
<action name="secondparalleljob">
<map-reduce>
<job-tracker>foo:9001</job-tracker>
<name-node>bar:9000</name-node>
<job-xml>job2.xml</job-xml>
</map-reduce>
<ok to="joining"/>
<error to="kill"/>
</action>
<join name="joining" to="nextaction"/>
...
</workflow-app>
参考
http://blog.csdn.net/matthewei6/article/details/50554472
http://marsorp.iteye.com/blog/1532983