淘宝外卖(口碑外卖)有App版和H5版两个版本。经验(直觉)告诉我们淘宝的App肯定是有保护措施的(签名机制),那我们就直奔H5版本了。H5版本的入口地址是:https://h5.m.taobao.com/app/waimai/index.html,你需要启动浏览器的手机兼容模式才能在PC浏览器中正常浏览(如何开启?我们之前的文章里有介绍:http://www.site-digger.com/html/articles/20160718/127.html)。
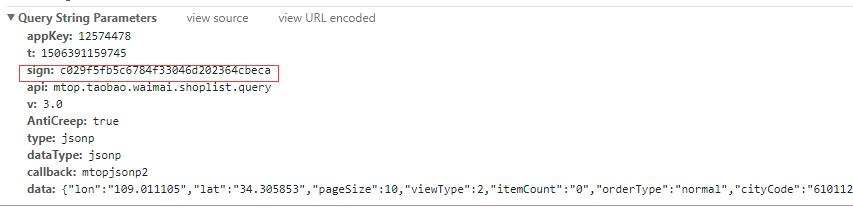
稍微抓包分析就可以看到数据全是Ajax动态加载的,不论是店铺列表页还是店铺详情页。当你尝试去构造这个Ajax请求时,会发现悲剧了。它同样也有一个签名参数sign(如下图所示)。这个值是根据data参数动态计算出来的,经验告诉我们想搞清楚这个算法是不容易的。如果我们不提交这个参数或者提交一个错误的值,服务器会返回错误。
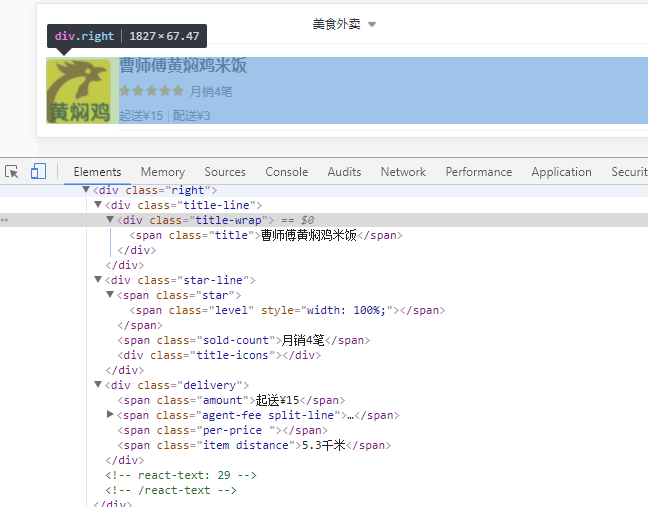
有经验的爬虫工程师立马会想到,那我们就曲线救国吧,使用模拟浏览器,来绕过这个签名机制。但是当你再仔细分析时发现又悲剧了,Ajax动态加载数据后,页面HTML里还是看不到店铺的详细信息(只能看到名称、月销量、起送金额之类的,如下图所示)。
PS:科普一下模拟浏览器的数据抓取方式,顾名思义就是通过程序控制浏览器去抓取数据,最大的优点是可以不关心数据的加载方式(动态加载还是静态页面),能绕过各种加密方式。直接从最终的页面源码(数据加载完成后)中提取想要的字段。(缺点是速度慢,资源开销大)。
我去,太狠了吧。Ajax返回的信息里明明有店铺详细的信息(甚至连电话、营业时间、营业执照信息都有啊),可惜动态加载后的页面中找不到(故意的),甚至控制台查看所有JS变量也找不到:dir(window)。我们需要的数据不在页面源码里,传统的模拟浏览器的方式也行不通了。
看来我们只能想办法拦截那个浏览器的Ajax应答,然后从Ajax应答里提取数据了。之前我们曾介绍过可以通过Fiddler + Custom Rules脚本来实现类似的功能(http://www.site-digger.com/html/articles/20170810/137.html),这里我们可以利用类似的方案,让 Custom Rules把捕获到的Ajax应答数据记录下来,然后我们再从里面提取想要的信息。
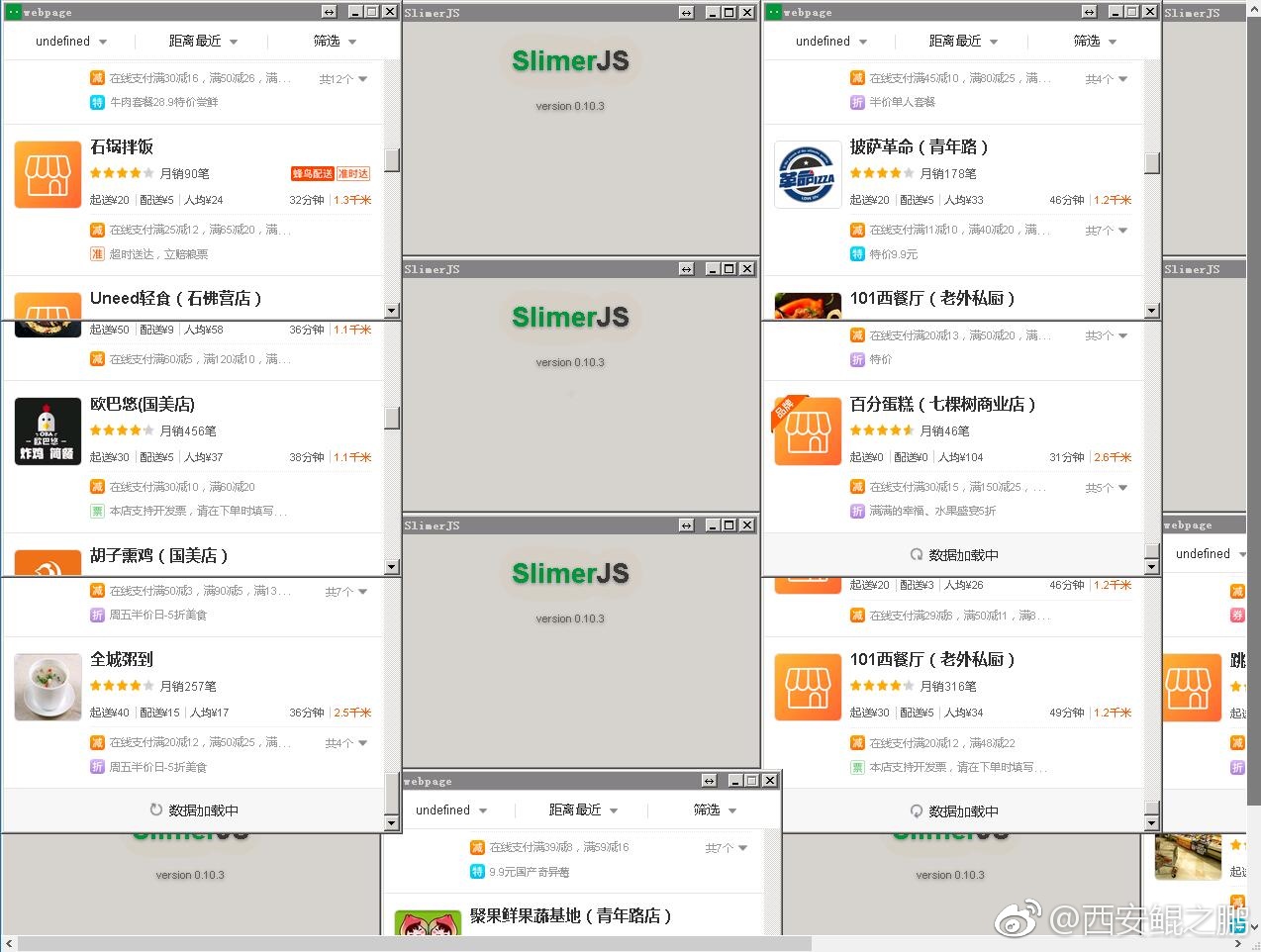
不过今天要换一种方案(条条大路通罗马)。我们换用SlimerJS(https://slimerjs.org/),它和PhantomJS类似可以用Javascript来驱动它为我们工作。它比PhantomJS优越的地方是它提供一个可以捕获HTTP事件的接口,我们可以利用它的onResourceReceived接口在HTTP应答到达的时候进行捕获。而且它支持多线程。
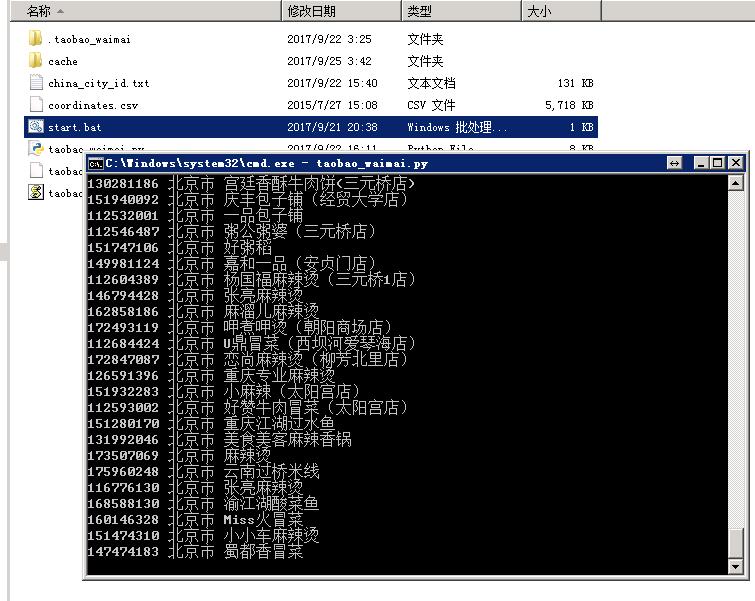
最后再秀一下抓取过程和最终获取到数据的截图:
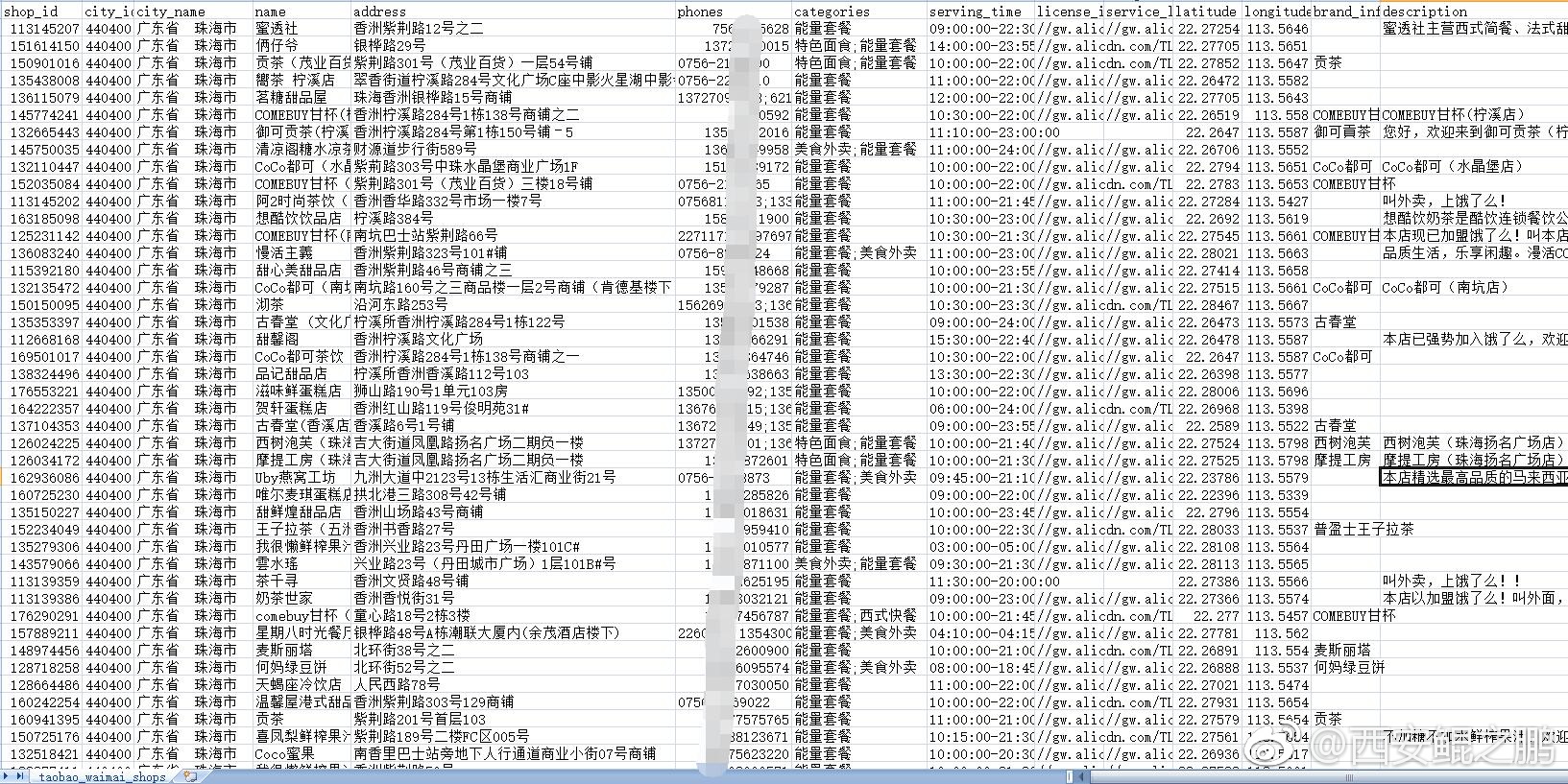
本文原创作者:鲲之鹏(http://www.site-digger.com)