实现原理:
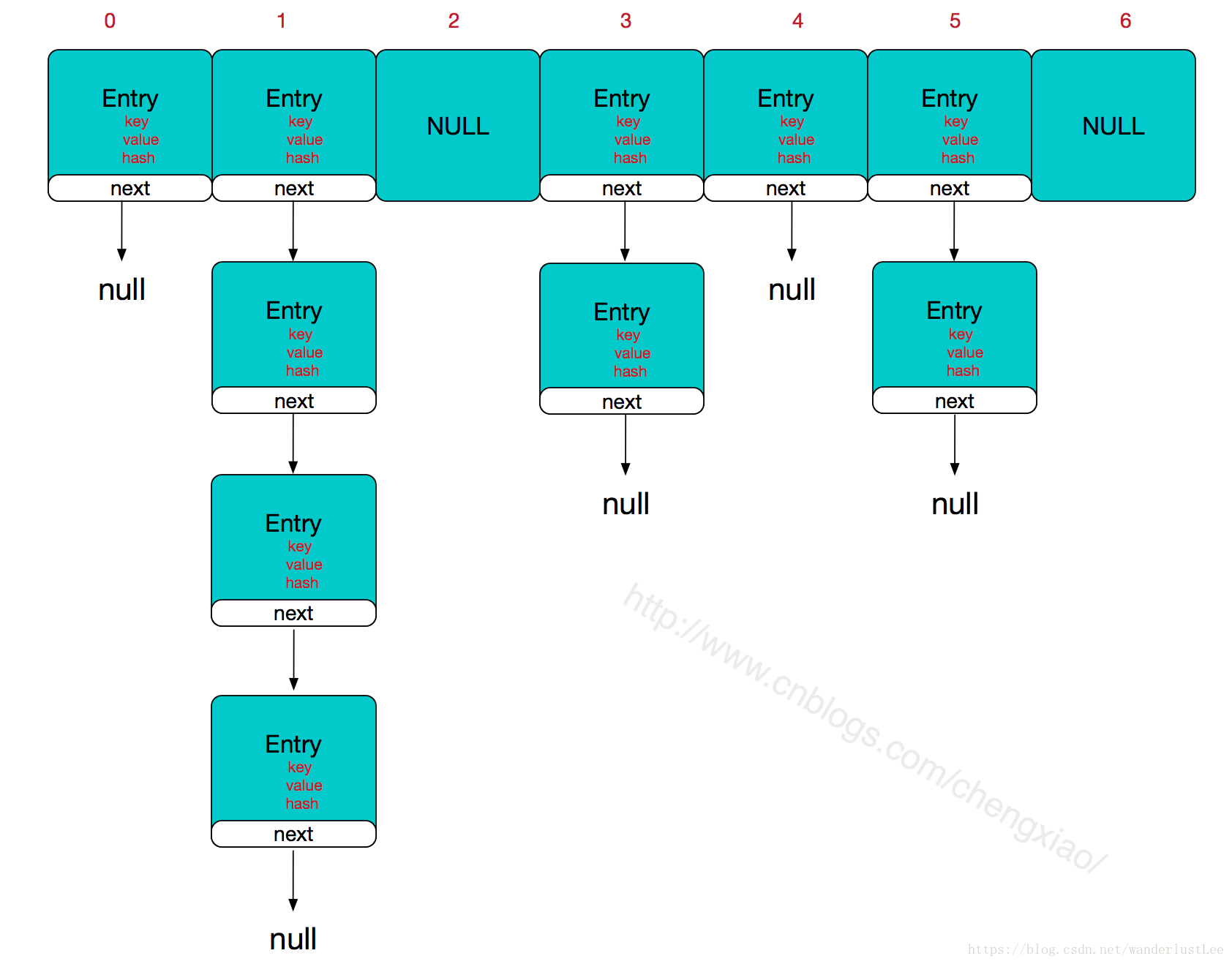
HashMap本质是一个一定长度的数组,数组中存放的是链表。
它是一个Entry类型的数组,Entry的源码:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
final int hash;
Entry<K,V> next;
} 其中存放了Key,Value,hash值,还有指向下一个元素的引用。
当向HashMap中put(key,value)时,会首先通过hash算法计算出存放到数组中的位置,比如位置索引为i,将其放入到Entry[i]中,如果这个位置上面已经有元素了,那么就将新加入的元素放在链表的头上,最先加入的元素在链表尾。比如,第一个键值对A进来,通过计算其key的hash得到的index=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其index也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,index也等于0,那么C.next = B,Entry[0] = C;这样我们发现index=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起,也就是说数组中存储的是最后插入的元素。
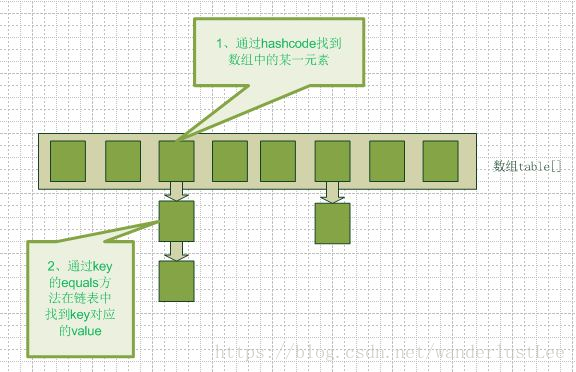
HashMap的get(key)方法是:首先计算key的hashcode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。从这里我们可以想象得到,如果每个位置上的链表只有一个元素,那么hashmap的get效率将是最高的。所以我们需要让这个hash算法尽可能的将元素平均的放在数组中每个位置上。
扩容机制:
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容。
HashMap的容量由一下几个值决定:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // HashMap初始容量大小(16)
static final int MAXIMUM_CAPACITY = 1 << 30; // HashMap最大容量
transient int size; // The number of key-value mappings contained in this map
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 负载因子
HashMap的容量size乘以负载因子[默认0.75] = threshold; // threshold即为开始扩容的临界值
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; // HashMap的基本构成Entry数组当HashMap中的元素个数超过数组大小(数组总大小length,不是数组中个数size)*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过16*0.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置。
0.75这个值成为负载因子,那么为什么负载因子为0.75呢?这是通过大量实验统计得出来的,如果过小,比如0.5,那么当存放的元素超过一半时就进行扩容,会造成资源的浪费;如果过大,比如1,那么当元素满的时候才进行扩容,会使get,put操作的碰撞几率增加。
HashMap中扩容是调用resize()方法,方法源码:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果当前的数组长度已经达到最大值,则不在进行调整
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//根据传入参数的长度定义新的数组
Entry[] newTable = new Entry[newCapacity];
//按照新的规则,将旧数组中的元素转移到新数组中
transfer(newTable);
table = newTable;
//更新临界值
threshold = (int)(newCapacity * loadFactor);
}
//旧数组中元素往新数组中迁移
void transfer(Entry[] newTable) {
//旧数组
Entry[] src = table;
//新数组长度
int newCapacity = newTable.length;
//遍历旧数组
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);//放在新数组中的index位置
e.next = newTable[i];//实现链表结构,新加入的放在链头,之前的的数据放在链尾
newTable[i] = e;
e = next;
} while (e != null);
}
}
}可以看到HashMap不是无限扩容的,当达到了实现预定的MAXIMUM_CAPACITY,就不再进行扩容。
Hashmap为什么大小是2的幂次?
因为在计算元素该存放的位置的时候,用到的算法是将元素的hashcode与当前map长度-1进行与运算。源码:
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}如果map长度为2的幂次,那长度-1的二进制一定为11111...这种形式,进行与运算就看元素的hashcode,但是如果map的长度不是2的幂次,比如为15,那长度-1就是14,二进制为1110,无论与谁相与最后一位一定是0,0001,0011,0101,1001,1011,0111,1101这几个位置就永远都不能存放元素了,空间浪费相当大。也增加了添加元素是发生碰撞的机会。减慢了查询效率。所以Hashmap的大小是2的幂次。
get方法实现
Hashmap get一个元素是,是计算出key的hashcode找到对应的entry,这个时间复杂度为O(1),然后通过对entry中存放的元素key进行equal比较,找出元素,这个的时间复杂度为O(m),m为entry的长度。