首先上来是自我介绍。
第一题:算法题。
给定一个数组和一个目标结果,返回数组中两个数的和等于目标结果的索引的数组,要考虑数组中的重复元素。比如,给一个数组{2,-1,0,2,18,30,20},target=20。那返回的结果集应该为[2,6],[0,4],[3,4]。
这道题刷LeetCode的时候做过类似的,只不过那道题没有重复元素。
回答:思路是建一个map,将数组的值存为key,索引存为value。所以这个题的重点就是如何存储重复元素的索引,经过面试官的引导,依旧使用这种方法,只不过value中存的应该是数组相同值得索引构成的list。然后遍历map的key,查map中还存不存在target-当前key。
代码:
public static Set<int []> test(int []array,int target){
Map<Integer,List<Integer>> map = new HashMap<>();
List<Integer> list = null;
Map<String,int []> resultList = new HashMap<>();
for (int i = 0; i < array.length; i++) {
if (map.containsKey(array[i])){
list = map.get(array[i]);
list.add(i);
map.put(array[i],list);
}else {
list = new ArrayList<>();
list.add(i);
map.put(array[i],list);
}
}
Set<Integer> set = map.keySet();
Iterator<Integer> iterator = set.iterator();
while (iterator.hasNext()){
int key = iterator.next();
int temp = target - key;
if (map.containsKey(temp)){
//遍历索引
for (int j = 0; j < map.get(temp).size(); j++) {
for (int i = 0; i < map.get(key).size(); i++) {
int []a = {map.get(key).get(i),map.get(temp).get(j)};
//防止加入重复的结果数组
Arrays.sort(a);
String flag = a[0]+""+a[1];
if (!resultList.containsKey(flag)){
resultList.put(flag,a);
}
}
}
}
}
return new HashSet<>(resultList.values());
}第二题:数据库有哪几种索引?怎样建立一个索引?
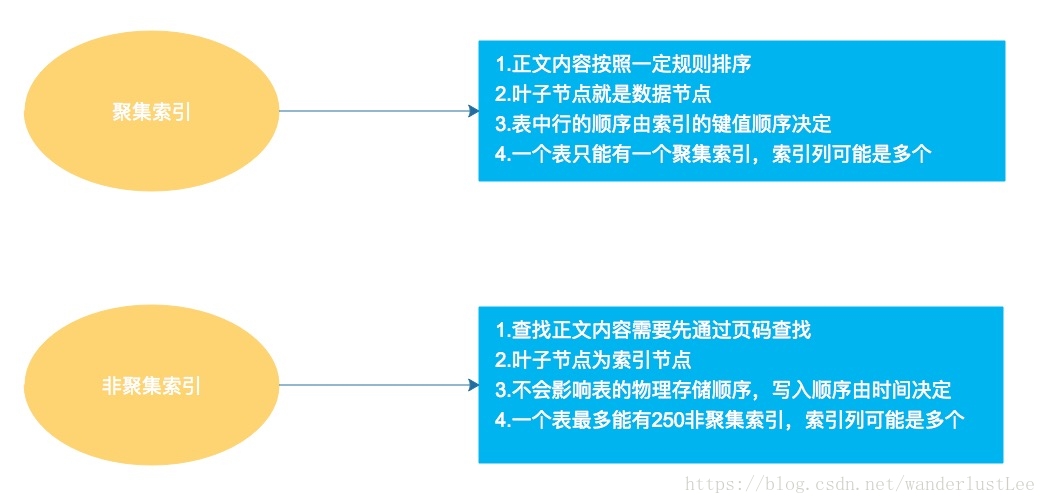
回答:主要有聚集索引和非聚集索引。聚集索引一个表只能有一个,大多是根据主键建的索引。非聚集索引一个表可以有多个,根据所需字段建立。建立索引的sql语句是create index on 表明(列名)。默认是非聚集索引。
反思:为列创建索引实际上就是为列进行排序,以方便查询。建立一个列的索引,就相当与建立一个列的排序。一个索引就是一个数据结构,常见的索引实现是通过平衡树。索引需要存储空间,一个索引就会占据一定的物理存储空间,表的体积也就会增加。
聚集索引:就是将表内的数据按照一定的规则进行排列的目录。
建表时,如果有主键,会默认将主键设置为聚集索引(只是在SqlServer、MySQL中,ORACLE中则默认是非聚集),MySQL中如果没有主键,将把第一个唯一并且非空的字段设置为聚集索引,如果还没有,会在后台设置一个6字节的字段作为聚集索引。但主键不一定要是聚集索引,聚集索引也不一定要为主键,也可在建表语句是将主键声明为非聚集索引。也可将其他唯一且不为空的字段设置为聚集索引。
聚集索引一张表只能有一个,因为聚集索引决定了数据的物理存储顺序,也就是磁盘上数据的存储位置。这种物理顺序一定要是唯一的,所以聚集索引也就只能有一个。一般聚集索引依据的字段是向一个方向增长的,比如自增长。这样添加的数据自动向后插入,避免了插入过程中的聚集索引排序问题。聚集索引的排序,必然会带来大范围的数据的物理移动,这里面带来的磁盘IO性能损耗是非常大的。
聚集索引不一定是唯一索引(索引的值不重复,但可以为null),也可以是非唯一索引。将索引设置为唯一,对于等值查找是很有利的,当查到第一条符合条件的纪录时即可停止查找,返回数据,而非唯一索引则要继续查找,同样,由于需要保证唯一性,每一行数据的插入都会去检查重复性。
Mysql中聚集索引是后台给设置好的,不能手动用关键字clustered或nonclustered设置聚集或者非聚集索引。之后手动设置的索引都是普通索引,也就是非聚集索引。非聚集索引中存储的不是数据,而是指向数据的指针。并且非聚集索引的创建不会改变数据的物理存储结构。
追问:对一个表中where x=200 and y >200,where x=200,where y=200。这种频繁的查询条件应该怎么建索引?
回答:我觉得这样可以对x和y字段建一个联合索引,不过要看那种查询比较多,如果对y单独的查询比较多,就对x和y分开建索引,如果对x和y一起查询、对x单独查询比较多,就建联合索引。
反思:mysql 暂时只支持最左前缀原则进行筛选。例子:创建复合索引 create index idx_a_b_c on tb1(a,b,c)只有使用如下条件才可能应用到这个复合索引1.where a=?2.where a =?and b =?3.where a =?and b =?and c =?但4.where a =?and c =?只会使用到mysql 索引 a 列的信息。如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引。
第二题:用过redis缓存吗,redis有哪些数据类型?
回答:String ,hash,list,set,zset。
追问:zset是什么?主要用在什么情境下?
回答:zset是排序的set,有序集合。这个应该是用在需要对数据进行排序操作的场景下吧,比如说分数。
反思:
1.String类型的应用场景
String是最常用的一种数据类型,普通的key/value存储.
2.list类型的应用场景
比较适用于列表式存储且顺序相对比较固定,例如:
省份、城市列表
品牌、厂商、车系、车型等列表
拆车坊专题列表…
3.set类型的应用场景
Set对外提供的功能与list类似,当需要存储一个列表数据,又不希望出现重复数据时,可选用set
4.zset(sorted set)类型的应用场景
zset的使用场景与set类似,区别是set不是自动有序的,而zset可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且 是插入有序的,即自动排序.当你需要一个有序的并且不重复的集合列表,那么可以选择zset数据结构。例如:
根据PV排序的热门车系车型列表
根据时间排序的新闻列表
5.hash类型的应用场景
类似于表记录的存储
页面视图所需数据的存储
第三题:使用redis怎么更新缓存?
回答:这个还没有了解过,不过我觉得最笨的方法就是将缓存清空,然后添加新的缓存。这样效率会很差。
追问:那在什么时候清空缓存呢?
回答:应该在有新数据添加或更新到数据库,数据库的内容和缓存中的内容不一致时更新缓存。
反思:通常的做法是先更新数据库,再删除缓存。如果有更新数据库的请求是,现等数据更新到数据库后,再删除旧的缓存,等有读请求时,再讲新的数据写入到缓存中。如果是新增数据,可以先将数据插入到数据库中,再把数据加入到缓存中。或者后台设置一个定时任务,定时更新缓存(当由用户触发的更新操作过于频繁时)。也可以设置缓存的过期时间,时间过了自动更新缓存。
1、缓存【失效】:客户端请求数据先从缓存中查询,如果没有再查询数据库,最后将数据放入缓存
2、缓存【命中】:客户端从缓存中直接取到数据,返回结果
3、缓存【更新】:客户端写入数据到数据库,成功之后,让缓存失效(下次请求时从缓存中拿不到,则查询数据库,再放入缓存)
第四题:学过操作系统吧,知道哪些页面置换的算法,了解LRU吗?
回答:emmm,页面置换?这个没有印象了,好早之前学的操作系统了,有点忘记了。
反思:页面是内存的一个物理单位,代表了一页内存,可以存放多个进程。分页就是讲内存分为多个页面,以便进行分配和调度(类似的还有分段内存)。运行一个程序时,对于大程序,一般不会讲所有都加载到内存中,那样会浪费内存资源,导致没有足够资源进行作业轮转让其他程序运行。一般会将程序分为几个页面,将一部分页面装入内存,其余页面留在外存中,在程序执行过程中,当所访问的信息不在内存中时(这种现象成为缺页中断),由操作系统将所需要的页面调入到内存,然后继续执行程序。另一方面,操作系统将内存中暂时不使用的页面换出到外存中,从而腾出空间存放将要调入的页面(这就叫做页面置换)。这样内存和外存组合在一起好像是为用户提供了一个比实际内存大很多的存储器,称为虚拟存储器,这部分内存也就成为虚拟内存。
页面置换算法就是用来解决应该将哪个页面换出内存。
最佳置换算法(OPT):是想让未来最长时间不会再访问到的页面换出。但是因为计算机无法预知未来,所以是一种理想型的算法,无法实现。
先进先出(FIFO)页面置换算法:就是先进入内存中的页面先换出。比如进入了三个页面:1,2,3,那么当需要访问4页面时,就要把最先进入的1换出。这种算法实现简单但是效率不高,并且可能会出现增加了物理块数(也就是能容纳的页面的数量),而缺页故障数不降反增的Belady异常。
最近最久未使用(LRU)页面置换算法:就是将调入到内存中的页面距离现在没有访问间隔最长时间的页面换出。比如进入了1,2,3三个页面,出现缺页中断时,最久没被访问的是1,那么将1换出。
时钟(CLOCK)页面置换算法,也称为最近未用(NRU)算法:简单的 CLOCK 该帧的使用位设置为算法是给每一帧关联一个附加位,称为使用位。当某一页首次装入主存时该使用位被置为1 ,当该页随后再被访问到时,它的使用位也被置为 1。将所有在内存中的用于替换的候选帧集合看做一个循环缓冲区,并且有一个指针与之相关联。对于页替换算法,当某一页被替换时,该指针被设置成指向缓冲区中的下一帧。当需要替换一页时,操作系统扫描缓冲区,查找第一个使用位为0的页面,将其替换。如果所有页面都为0,则选择第一个,如果所有页面都为1,则全置0然后选择第一个。
改进型CLOCK页面置换算法: CLOCK 算法的性能比较接近 LRU 。而在使用位的基础上再增加一个修改位,则得到改进型的 CLOCK 页面置换算法。每一个页面都处于以下四种情况之一:①最近未被访问,也未被修改(u=0,m=0)。②最近被访问,但未被修改(u=1,m=0)。③最近未被访问,但被修改(u=0,m=1)。④最近被访问,被修改(u=1,m=1)。算法执行如下操作步骤: ①从指针的当前位置开始,扫描帧缓冲区。在这次扫描过程中选择遇到的第一个帧(u=0,m=0)用于替换。②如果第①步失败,则重新扫描,查找(u=0,m=1)的帧。选择遇到的第一个这样的帧用于替换。在这个扫描过程中,对每个跳过的帧,把它的使用位设置成 0。③如果第②步失败,指针将回到它的最初位置,并且集合中所有帧的使用位均为 0 。重复第①②步这样将可以找到供替换的帧。
类似的还有磁盘调度算法:就是在对磁盘进行读写操作时在磁盘的磁道上选择的算法。算法的好坏可决定读写的快慢。当然读写的快慢还取决于磁盘的转速,因为数据最终要读写到磁盘上磁道的某一扇区。主要包括:先来先服务(FCFS)算法、最短寻找时间优先(SSTF)算法,扫描(SCAN)算法或电梯算法,循环扫描(C-SCAN)算法。
还有进程(作业)调度算法,有:先来先服务(FCFS)调度算法、短作业优先(SJF)调度算法、优先级调度算法、最高响应比优先调度算法(响应比=等待时间+服务时间/服务时间)、时间片轮转调度算法、多级反馈队列调度算法(结合多个算法)。
第五题:学过HTTP吧,知道哪些HTTP状态码?
回答:200:表示响应成功。204:表示请求成功,但服务器没有返回数据。404:页面资源未找到。500:服务器内部错误。403:禁止访问。
反思:常用状态码:
- 200 OK
请求正常处理完毕 - 204 No Content
请求成功处理,没有实体的主体返回 - 206 Partial Content
GET范围请求已成功处理 - 301 Moved Permanently
永久重定向,资源已永久分配新URI - 302 Found
临时重定向,资源已临时分配新URI - 303 See Other
临时重定向,期望使用GET定向获取 - 304 Not Modified
发送的附带条件请求未满足 - 307 Temporary Redirect
临时重定向,POST不会变成GET - 400 Bad Request
请求报文语法错误或参数错误 - 401 Unauthorized
需要通过HTTP认证,或认证失败 - 403 Forbidden
请求资源被拒绝 - 404 Not Found
无法找到请求资源(服务器无理由拒绝) - 500 Internal Server Error
服务器故障或Web应用故障 - 503 Service Unavailable
服务器超负载或停机维护
追问:500错误应该怎么解决?
回答:500是服务器内部错误,所以需要看服务器日志的报错信息,去后台修改对应的代码。
第六题:了解Https吗?
回答:知道他是一个比Http更安全的协议,具体的不太了解,后面学习一下。。。。
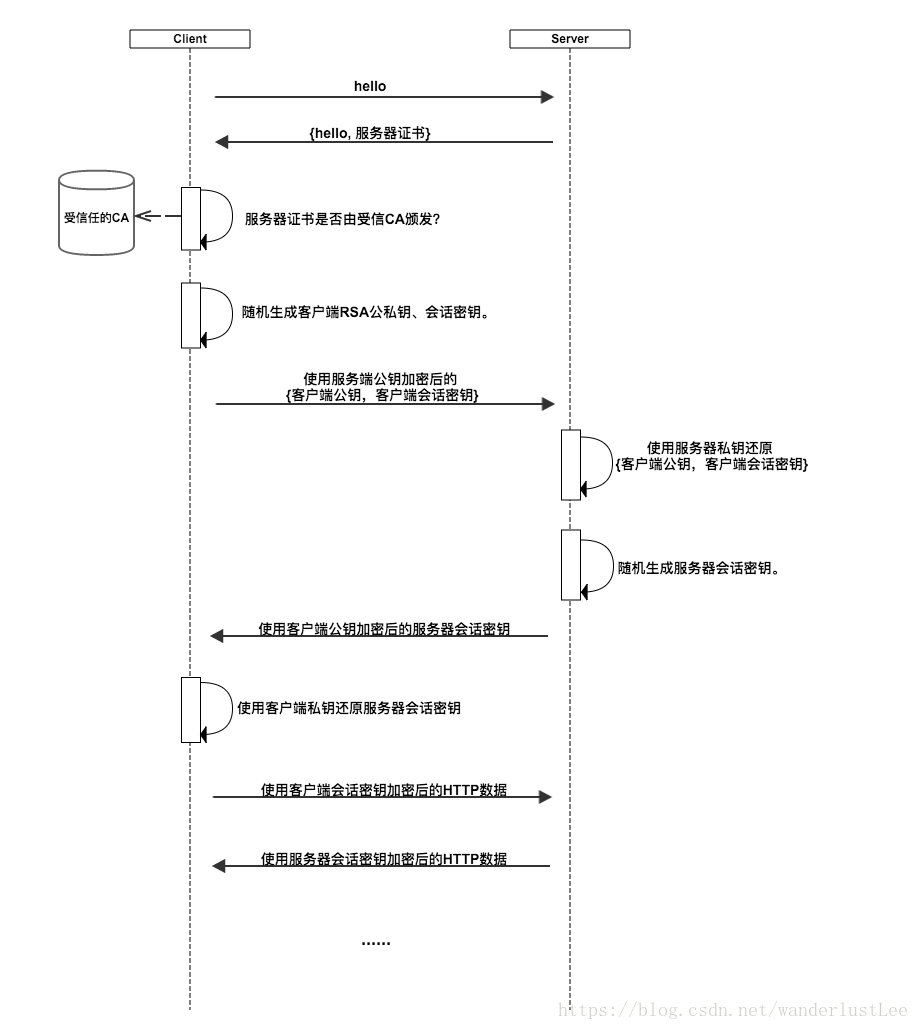
反思:Https是一种比Http更加安全的应用层协议,端口为443,可以理解为Http+SSL/TLS, 即 HTTP 下加入 SSL 或TLS层,SSL和TLS层都是位于Http层之下,TCP/IP层之上加入的一层安全协议。HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL,用于安全的 Http 数据传输。Http都是明文传输的,数据是裸奔在网络中的,完全可以通过抓包修改请求中的数据然后重新发送,而Https就可以解决这个问题。Https主要保证两点:①可以认证正在访问的网站。比如说我们正在访问银行的官网,怎样确保是真的官网还是钓鱼网站?通过Https协议将官网加入到Https证书签发和管理机构,比如CA机构,这样我们访问的时候可以到机构上验证这个网站是不是官网。现在Chrome默认将非Https的网站标记为不安全的网站。②保证所传输数据的私密性和完整性。通过机构的加密算法加密数据,另一端再通过这个算法解析数据,这样就算数据中间被劫持,没有提供的算法也无法修改和解析数据。因为有了验证加密解密等阶段,Https也比Http请求处理的时间长,也更耗费服务器资源。
请求的主要过程:
第七题:说一下TCP断开的步骤。
回答:TCP断开连接时需要经过四次握手。首先客户端发出断开连接请求,服务端响应到会发送一个ACK确认,但此时服务器还可以服务端发送数据,客户端也必须要接受数据,处于一个半关闭状态。等服务端发送完数据,会再发送一个FIN字段表示数据已发送完毕,客户端收到后要再发送一个确认关闭,等待一段时间,然后断开连接。
追问:为什么服务端要分开发送确认?为什么发送了断开请求还要发送数据?
回答:因为一开始断开连接的请求是单方向的,如果此时服务端还有数据没有发送就要继续发送。也为了防止客户端超时的断开连接请求发送到服务端造成错误。
基础知识好的都忘了。。。回答的不好,八成是凉了。。。。