#pragma是编译器指示字,用于指示编译器完成一些特定的动作
#pragma所定义的很多指示字是编译器和操作系统特有的
#pragma在不同的编译器间是不可移植的
预处理器将忽略它不认识的#pragma指令,当预处理器看到#pragma后,就不会像处理#define,#include那样来进行进一步的处理,会把#pragma指令留给后续的编译模块,编译模块会根据他的参数执行一系列的动作,编译模块如果发现parameter参数是自己支持的话,就按照自己的处理方式来进行处理,如果是自己不支持的话就直接忽略把它删除掉。
两个不同的编译器可能以两种不同的方式解释同一条#pragma指令
一般用法:
#pragma parameter
注:不同的parameter参数语法和意义各不相同,因为这依赖于编译器制造商如何来实现
#pragma message
message参数在大多数的编译器中都有相似的实现
message参数在编译是输出消息到编译输出窗口中,单纯的将消息输出,没有更多含义
message可用于代码的版本控制
注意:message是VC特有的编译器指示字,gcc中将其忽略  这点有疑问,先挂起
这点有疑问,先挂起
以下程序在Dev-C++中运行,编译器是gcc
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
int main()
-
{
-
printf( "%s\n", VERSION);
-
return 0;
-
}

编译选项加入宏定义 -DANDRIOD23,再编译

但是在Linux下编译不会有#pragma的输出

或许是gcc版本不一致造成的。
#pragma pack
内存对齐:
不同类型的数据在内存中按照一定的规则排列;而不是顺序的一个接一个的排放,这就是对齐。
为什么需要内存对齐?
CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是1、2、4、8、16...2^n字节
当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
效率方面:

某些硬件平台只能从规定的地址处取某些特定类型的数据,否则抛出硬件异常
如:硬件规定只能读/写偶地址

编译器优化后

#pragma pack能够改变编译器的默认对齐方式
#pragma pack(2) //告诉编译器不要按照默认方式对齐了,按照我指定的2字节对齐方式对齐
struct Test1
{
char c1;
short s;
char c2; //sizeof(struct Test1) = 10
int i;
};
#pragma pack() //编译器将取消自定义字节对齐方式
#pragma pack(4) //告诉编译器不要按照默认方式对齐了,按照我指定的4字节对齐方式对齐
struct Test2
{
char c1;
short s;
char c2; //sizeof(struct Test1) = 12
int i;
};
#pragma pack() //编译器将取消自定义字节对齐方式
struct占用的内存大小:
.第一个成员起始于0偏移处 如下c1起始于0
.每个成员按期类型大小和指定对齐参数n中较小的一个进行对齐 如下地址/对齐参数,c1:0/1能除尽,s:2/2能除尽,c2:4/1能除尽,i:8/4能除尽
.偏移地址和成员占用大小均需对齐
.结构体成员的对齐参数为其所用成员使用的对齐参数的最大值
.结构体总长度必须为所用对齐参数的整数倍,如下12(1+1+2+1+3+4)是1,2,4的整数倍

面试题:
#include <stdio.h>
#pragma pack(8)
struct S1
{
short a;
long b;
};
struct S2
{
char c;
struct S1 d; //对于结构体,要取它用过的对齐数里面最大的一个,其对齐参数取4
double e;
};
#pragma pack()
int main()
{
struct S2 s2;
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
printf("%d\n", (int)&(s2.d) - (int)&(s2.c)); //d的地址-c的地址 = 4(看下图)
return 0;
}

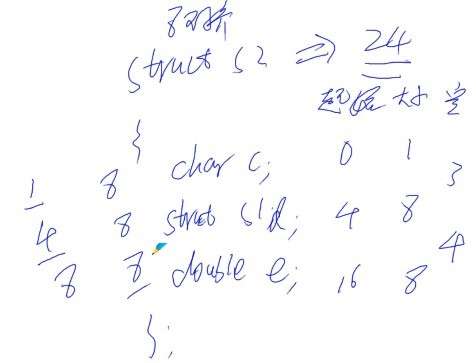
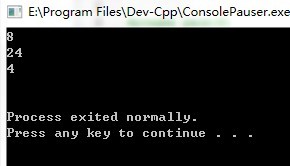
在Dev-C++中运行结果如下
但是在Linux下运行结果如下
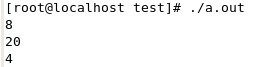
因为Linux下gcc不支持8字节对齐,只能支持1字节,2字节,4字节对齐,所以这里#pragma pack(8)编译器直接无视,就按照默认的4字节对齐,所以结果不一样。