目录
1.HDFS设计基础与目标
2.HDFS体系结构
2.1 NameNode
2.2 DataNode
3.读取数据流程
4.HDFS的可靠性
4.1 冗余副本策略
4.2 机架策略
4.3 心跳策略
4.4 安全模式
4.5 校验和
4.6 回收站
4.7 元数据保护
4.8 快照机制
Hadoop其实并不是一个产品,而是一些独立模块的组合。主要由分布式文件系统HDFS和大型分布式数据处理算法MapReduce组成。那么我们今天就来看看HDFS究竟是什么鬼?
1.HDFS设计基础与目标
(1) 硬件错误是常态。因此需要冗余。
在Google很少会使用超级计算机,也很少会使用一些厂商很昂贵的设备,他们一般会使用的就是普通的PC集群。PC集群即使是PC server,它的底子基本上也是家用机的模式,所以这种机器的耐用性肯定没有小型机或者专用的服务器高。如果一个集群里机器很多,比如几百台,那么每个星期坏几台是很常见的。这个“坏掉”不一定是彻底坏掉,可能是宕机等,比如内存不稳定或者CPU过热,导致某些节点死掉;或者过了一段时间之后,硬盘的寿命到期,硬盘的介质发生了损坏,因为普通PC很多都是采用很便宜的SATA硬盘,它设计的也不一定就是7*24工作的,或者在7*24模式底下工作它的寿命就会大大缩短。无论什么原因,总之在hadoop集群里面,我们面对的就是经常性地发生错误这种情况。每天可能就是要面对各种各样的错误,有些时候可能是节点机器本身失效,比如死机、断网等,有些时候可能是硬盘介质问题,比如某个文件损坏、某个硬盘完全坏掉等。由于错误是经常性发生,所以备份都不足够防止这种错误。因此需要冗余,就是在运行的过程中直接对数据进行备份,比如说数据本来只需要写一份,现在可能需要一次写好几份,万一某个节点失效,我们还可以从其他节点把这个数据拿出来。因此冗余是HDFS本身直接嵌入的一个功能,它并不是一个额外的功能,它是在设计的时候就必须考虑的一点。冗余思想是深入到HDFS的骨髓里面的。
(2) 流式数据访问。即数据批量读取而非随机读写,hadoop擅长做的是数据分析而不是事物处理。
HDFS是为大数据而生。一般来说很少会让Hadoop集群去做OLTP(联机事务处理)。所谓OLTP就是偶尔地、随机性地去读写一些数据,主要就是随机读,随机写,可能还会有一些修改的工作。Hadoop很少会处理这种事情,它处理的是大数据的流式读写,比如说我整堆整堆的去读,然后去加以处理。
(3) 大规模数据集。
(4) 简单一致性模型,为了降低系统复杂度,对文件采用一次性写多次读的逻辑设计,即是文件一经写人,关闭,就不能修改。
由于面临的是批量性地操作,所以hadoop在设计时就会采取一些简单的一致性模型,针对这种大批量读却很少去写的模型。为了降低系统的复杂度,Hadoop文件通常是一次性写进去,比如说拷贝文件一次性拷好,这个文件拷好之后一般你不会去改,除非你把它删除掉。就是说这个文件写进去之后你会多次去读它,但是不能改变它的内容。如果你一定要改变它,那就把原来的文件删除,然后再把改后的文件重新写进去。
(5) 程序采用“数据就近”原则分配节点执行。
HDFS在设计时也要考虑到MapReduce体系跟它的融合,就是我们的数据到底怎么放,才能使作业以最快的速度来运行。
2.HDFS体系结构
HDFS体系结构有NameNode、DataNode和SecondaryNameNode。
另外在NameNode上面是怎样保存数据的呢?主要是采用了事物日志以及映像文件这2个概念。
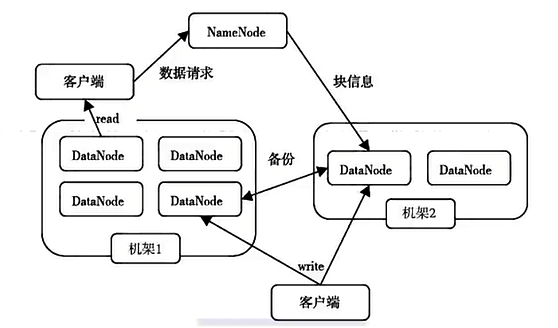
下面我们来逐一观察一下架构里面的一些元素。
2.1 NameNode
(1) 管理文件系统的命名空间。
就是说它是文件系统总控的节点。
(2) 记录每个文件的数据块在各个DataNode上的位置和副本信息。
就比如说现在我有一个表格,这个表格的每一个项目均记录了一个文件的情况,比如说文件名、权限、元数据信息(建立修改时间、长度等)。除此之外,它还记录这些文件究竟在集群的哪些节点上,比如说存在节点1的某个数据块上面。
(3) 协调客户端对文件的访问。
当有节点需要访问某个文件时,首先访问NameNode来获取文件位置信息,然后跟相应的DataNode通讯,读取数据块。所以NameNode在这里起到了一个类似书里面目录的作用。
(4) 记录命名空间内的改动或空间本身属性的改动。
比如说它的权限发生了一些什么样的变化之类的。
(5) 使用事物日志记录HDFS元数据的变化,使用映像文件存储文件系统的命名空间,包括文件映射,文件属性等。
NameNode使用两个东西来记录元数据。分别是事物日志和映像文件。具体来说大家可以打开NameNode节点上面你所定义的保存元数据的目录,在HDFS配置文件里面有一项参数是指出元数据在什么地方,那是一个目录,打开目录之后可以看到有一些文件,其中fsimage就是映像文件。


[root@hadoop ~]# cat /usr/local/hadoop/etc/hadoop/core-site.xml ... <property> <name>hadoop.tmp.dir</name> <value>/var/hadoop/tmp</value> </property> ... [root@hadoop ~]# cd /var/hadoop/tmp/dfs/name/current/ [root@hadoop current]# ll total 1052 -rw-r--r-- 1 root root 42 Jul 18 04:03 edits_0000000000000000001-0000000000000000002 -rw-r--r-- 1 root root 1048576 Jul 18 04:03 edits_inprogress_0000000000000000003 -rw-r--r-- 1 root root 389 Jul 18 04:02 fsimage_0000000000000000000 -rw-r--r-- 1 root root 62 Jul 18 04:02 fsimage_0000000000000000000.md5 -rw-r--r-- 1 root root 389 Jul 18 04:03 fsimage_0000000000000000002 -rw-r--r-- 1 root root 62 Jul 18 04:03 fsimage_0000000000000000002.md5 -rw-r--r-- 1 root root 2 Jul 18 04:03 seen_txid -rw-r--r-- 1 root root 219 Jul 18 04:02 VERSION
2.2 DataNode
(1) 负责所在物理节点的存储管理
(2) 一次写入,多次读取(不修改)
由于这个特性,那么我们就不需要考虑一致性问题。所谓一致性就是说假如有很多人同时修改一个文件,那么最终应该采纳哪个修改的版本呢?这是在数据库环境里经常要考虑的问题。在Oracle中采用回滚,在块结构里也加了一些机制来保证读取一致性,但是Oracle里面做的巨复杂。而在hadoop中非常简单,因为文件一经写入就不能改,所以根本就不可能发生很多人一起修改的情况。因此它完全不需要考虑一致性。
(3) 文件由数据块组成,典型的块大小是64MB
每个数据块是一个blk文件,一般来说缺省的数据块可以达到64MB,大家可以尝试往Hadoop里面不断写文件,可观察到数据块在不断增长,一般来说增长到64MB就不再增长,然后数据块文件就不断增多。
(4) 数据块尽量散布到各个节点
实现冗余的效果
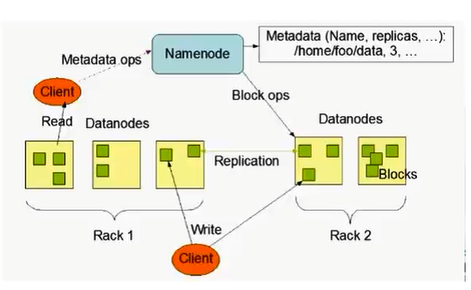
3.读取数据流程
客户端(通常是集群中的某一个节点)要访问HDFS中的一个文件:
首先从NameNode获得组成这个文件的数据块位置列表;然后根据列表知道存储数据块的DataNode;最后访问DataNode获取数据。
NameNode并不参与数据实际传输。
4.HDFS的可靠性
4.1 冗余副本策略
(1) 可以在hdfs-site.xml中设置复制因子指定副本数量。
[root@hadoop ~]# cat /usr/local/hadoop/etc/hadoop/hdfs-site.xml ... <property> <name>dfs.replication</name> <value>1</value> </property> ...
复制因子:比如说replication=1代表没有冗余,2及以上代表有冗余。一般来说,数越大代表越安全,即数据块重复的越多越安全。但是把数定大了也有坏处,那
就是空间利用率下降,比如说冗余数量增大一倍,此时空间利用率就会下降50%。还有一个坏处就是影响速度,因为数据要写入副本,肯定会在性能上产生一些影响。所以说复制因子应该取什么数值呢?说实话这个一般没有什么原则,大家可以根据实际集群的情况、性能、空间利用率等综合的一个平衡,来选取一个折中的数值。
(2) 所有数据块都有副本。
(3) DataNode启动时,遍历本地文件系统,产生一份hdfs数据块和本地文件的对应关系列表(blockreport)汇报给NameNode。
一般来说数据节点启动时,都会把本地的系统文件遍历一次,产生一个数据块和本地文件对应的清单(叫做blockreport)汇报给NameNode,NameNode根据blockreport来和它的元数据进行对照,看一看数据节点的实际情况跟元数据里面所记录的情况是否相符,再决定是否采取某些安全上的措施。
4.2 机架策略
集群一般放在不同机架上,机架间带宽要比机架内宽带要小。
集群一般是放在若干个机柜里面,集群可能利用机柜里面的交换机共同连到一个大的交换机里面,一般来说有这么一个规律,就是同一个机柜里面的机器由于连的是同一个机柜里的交换机,通常交换数据比较快。不同机柜之间的服务器由于连到一个更加高级的一个交换机里面,所以他们的速度一般会慢一点。而且还有一个比较特别的情况,有时候可能会因为网线的故障或者交换机端口的故障,我们往往会跟整个机柜里面的服务器失去联系。考虑到这种情况。hadoop对机架要有特殊的处理策略。比如机架感知和冗余策略。
HDFS的“机架感知”。
通过节点之间互相传递一个信息包来获知节点之间的关系(究竟是分布在同一个机架还是不同的机架里面)。
冗余:一般在本机架存放一个副本,在其他机架存放别的副本,这样可以防止机架失效时丢失数据,也可以提高带宽利用率。
4.3 心跳策略
Namnode周期性从DataNode接收心跳信号和快报告;
所谓快报告就是说DataNode会不断地向NameNode发送一个blockreport,告诉他在本地的系统里面数据块和文件的对应关系。
NameNode会根据块报告验证元数据;
就是说数据节点实际情况和元数据里面记录的是否一致,如果不一致,可能需要进行相应的修正以及冗余策略等。
没有按时发送心跳的DataNode会被标记为宕机,不会再给它任何I/O请求;
如果DataNode失效造成副本数量下降,并且低于预先设置的阈值,NameNode会检测出这些数据块,并在合适的时机进行重新复制;
引发重新复制的原因还包括数据副本本身损坏、磁盘错误,复制因子被增大等。
4.4 安全模式
NameNode启动时会先经过一个“安全模式”阶段;
安全模式阶段不会产生数据写;
在此阶段NameNode收集各个DataNode的报告,当数据块达到最小副本数以上时,会被认为是安全的;
在一定比例(可设置)的数据块被确定为“安全”后,再过若干时间,安全模式结束;
当检测到副本数不足的数据块时,该块会被复制直到达到最小副本数。
4.5 校验和
在文件创立时,每个数据块都产生校验和;
校验和会作为单独一个隐藏文件保存在命名空间下;
客户端获取数据时可以检查校验和是否相同,从而发现数据块是否损坏;
如果正在读取的数据块损坏,则可以继续读取其它副本。
4.6 回收站
删除文件时,其实是放入回收站/trash;
回收站里的文件可以快速恢复;
可以设置一个时间阈值,当回收站里文件的存放时间超过这个阈值,就会被彻底删除,并且释放占用的数据块。
4.7 元数据保护
映像文件和事物日志是NameNode的核心数据,可以配置为拥有多个副本;
副本会降低NameNode的处理速度,但增加安全性;
NameNode依然是单点,如果发生故障要手工切换。
元数据在NameNode上,保存了整个文件系统的关键信息,如果元数据被破坏掉,那么毫无疑问文件系统就崩溃了,无可挽回的崩溃,为了防止这种情况的发生,我们需要对元数据进行保护。
4.8 快照机制
支持存储某个时间点的映像,需要时可以使数据重返这个时间点的状态;
Hadoop目前(2012年)还不支持快照,已经列入开发计划。