目的:
利用python实现爬取淘宝某具体商品信息,再将其数据实现持久化。
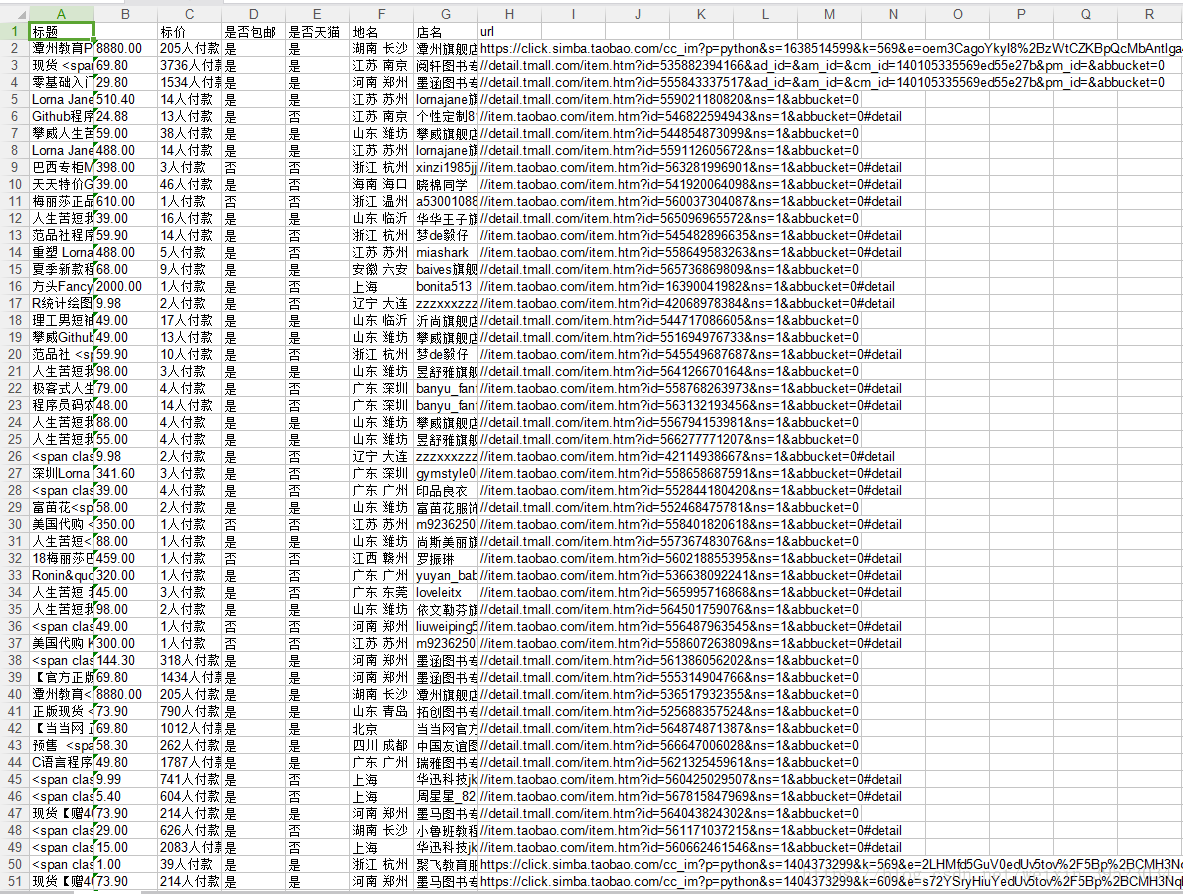
实现结果如图:
开始前:
环境:python3
第三方模块:requests,matplotlib,xlwt
IDE:PYCHARM
浏览器:Chrome
这些安装全部跳过,直接来干货!!!
先来一波概念
网络爬虫:
用于模拟浏览器进行批量爬取我们需要的数据的一个程序或代码段(认为不对欢迎指正)
说是一波其实也就只有一条
下面正式开始:
1、我们先在淘宝搜索关键字:python(这个随意),获取我们这次爬取的url
url = 'https://s.taobao.com/search?q=python&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20180430&ie=utf8'
这个url不一定是网页的地址栏的,当然,相同的关键字的url都不一定相同,不一样的关键字的url更不同。可以按F12对该网页进行一个简单的“抓包”(应该算不上真正意义的抓包)
2、发送http请求,这时候需要requests,获取源码进行分析
import requests
#http请求
response = requests.get(url)
#html源码
html = response.text3、通过部分源码我们不难发现,里面的内容符合json格式。可用正则表达式将内容提取出来。

4、分析找出信息,并且格式化json。
import re
content = re.findall(r'g_page_config = (.*?) g_srp_loadCss',html,re.S)[0].strip()[:-1]
#格式化
content = json.loads(content)
5.提取数据。将获取的json格式的数据放到json解析的网页中进行解析分析点击打开链接
此时我们创建一个data_list对象,用于数据的提取,并且定义一个全局字典DATA[],用for循环将data_list的数据进行提取。冒号前面为自定义,后面的为源码里面相应的标签。最后用方法append()将其添加到字典里。
#获取信息列表
data_list = content['mods']['itemlist']['data']['auctions']
#提取数据
for item in data_list:
temp = {
'title':item['title'],
'view_price':item['view_price'],
'view_sales':item['view_sales'],
'view_fee': '否' if float(item['view_fee'])else '是',
'isTmall':'是' if item['shopcard']['isTmall'] else '否',
'area': item['item_loc'],
'name':item['nick'],
'detail_url':item['detail_url'],
}
DATA.append(temp)6、通过print(len(DATA))我们不难发现我们只爬取到了36条数据,原本整个页面是有48条数据。这里就关系到了消息的加载方式:同步和异步。前面的36条数据是随网页一同加载,也就是同步加载的,后面12条是通过异步进行加载的,所以我们需要再次对后面的数据进行分析。下图不难发现刚好有12条数据是符合我们的要求的,也就是之前我们没有爬取下来的数据。
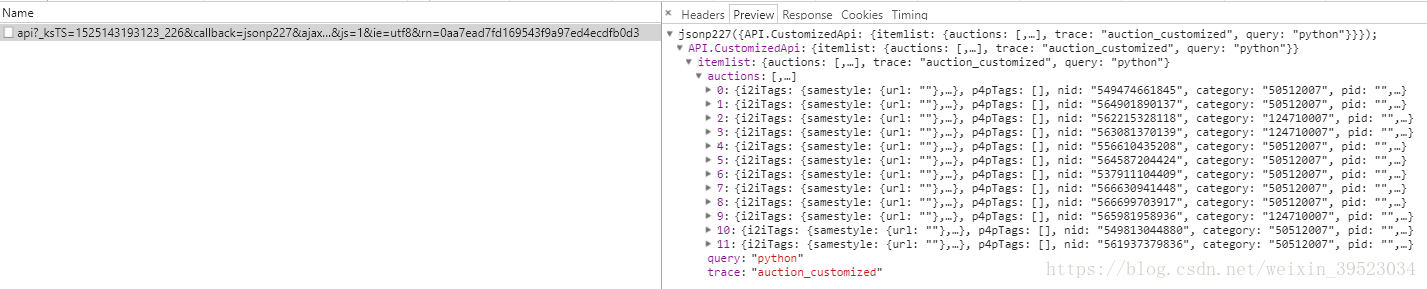
接下来需要模拟一下浏览器的请求,做一下cookie保持(有些需要cookie验证),然后再用正则表达式。
#cookie保持
cookies = response.cookies
#首页12条异步
url2 = 'https://s.taobao.com/api?_ksTS=1524836494360_224&callback=jsonp225&ajax=true&m=customized&sourceId=tb.index&q=python&spm=a21bo.2017.201856-taobao-item.1&s=36&imgfile=&initiative_id=tbindexz_20170306&bcoffset=-1&commend=all&ie=utf8&rn=efedc6cda629c8a38008aff6f017b934&ssid=s5-e&search_type=item'
response2 = requests.get(url2,cookies=cookies)
html2=response2.text
content = re.findall(r'{.*}',html2)[0]获取到的12条数据的处理方式于上面的36条的方式也相同。我们先专注于爬取的思路,代码的雍余可在后期进行优化,我们还是将其加入到DATA字典中。
#格式化
content = json.loads(content)
data_list = content['API.CustomizedApi']['itemlist']['auctions']
#提取
for item in data_list:
temp = {
'title':item['title'],
'view_price':item['view_price'],
'view_sales':item['view_sales'],
'view_fee': '否' if float(item['view_fee'])else '是',
'isTmall':'是' if item['shopcard']['isTmall'] else '否',
'area': item['item_loc'],
'name':item['nick'],
'detail_url':item['detail_url'],
}
DATA.append(temp)7、下面就是进行翻页的操作了,我们在浏览器翻页操作时,浏览器发送了请求。
我们找到了翻页请求的url,将其提取出来,进行分析。

url = 'https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksTS=1525143958908_907&callback=jsonp908&q=python&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=3&ntoffset=0&p4ppushleft=1%2C48'进行下次翻页该url是有规律可循的,其主要变量在data-value、时间戳_ksTS以及callback,因此要进行翻页模拟需要引入time。这里同样需要cookie保持,我们先获取10页的数据用方法range(1,10)在for循环里对翻页地址进行拼接,翻页完成后自然就是数据提取,上面有提,这里就不在赘述。
import time
#翻页
cookies=response2.cookies
for i in range(1,10):
ktsts = time.time()
_ksTS = '%s_%s' % (int(ktsts*1000),str(ktsts)[-3:])
callback = "jsonp%s" % (int(str(ktsts)[-3:])+1)
data_value = 44*i
url = 'https://s.taobao.com/search?data-key=s&data-value={}&ajax=true&_ksTS={}&callback={}&q=python&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&bcoffset=0&ntoffset=6&p4ppushleft=1%2C48&s=44'.format(data_value,_ksTS,callback)8、数据持久化。将数据爬取到本地并以Excel格式存储,需要引入xlwt。
import xlwt
#持久化
f = xlwt.Workbook(encoding='utf-8')
sheet01 = f.add_sheet(u'sheet1',cell_overwrite_ok=True)
#写标题
sheet01.write(0,0,'标题')
sheet01.write(0,2,'标价')
sheet01.write(0,3,'是否包邮')
sheet01.write(0,4,'是否天猫')
sheet01.write(0,5,'地名')
sheet01.write(0,6,'店名')
sheet01.write(0,7,'url')
for i in range(len(DATA)):
sheet01.write(i+1,0,DATA[i]['title'])
sheet01.write(i + 1, 1, DATA[i]['view_price'])
sheet01.write(i + 1, 2, DATA[i]['view_sales'])
sheet01.write(i + 1, 3, DATA[i]['view_fee'])
sheet01.write(i + 1, 4, DATA[i]['isTmall'])
sheet01.write(i + 1, 5, DATA[i]['area'])
sheet01.write(i + 1, 6, DATA[i]['name'])
sheet01.write(i + 1, 7, DATA[i]['detail_url'])
f.save(u'搜索python的结果.xls')这里就没有太多方法可言,也就是添加标题,以及存储样式。运行后,我们代码的文件夹中会多一个名为:搜索python的结果.xls 的文件,打开里面就是我们要的结果。然后,整个爬取淘宝信息的流程大致如此。
声明:该博客内容是博主通过视频学习敲写,并未做任何商业用途,做于本人的学习笔记,侵权或触碰到相关法律法规必删,谁叫我是奉公守法的好青年呢。有什么疑问可留言和我交流,谢谢。