所有实现的接口:
Serializable, Cloneable, Iterable<E>, Collection<E>, NavigableSet<E>, Set<E>, SortedSet<E>
- 1
以下是类的对应关系。
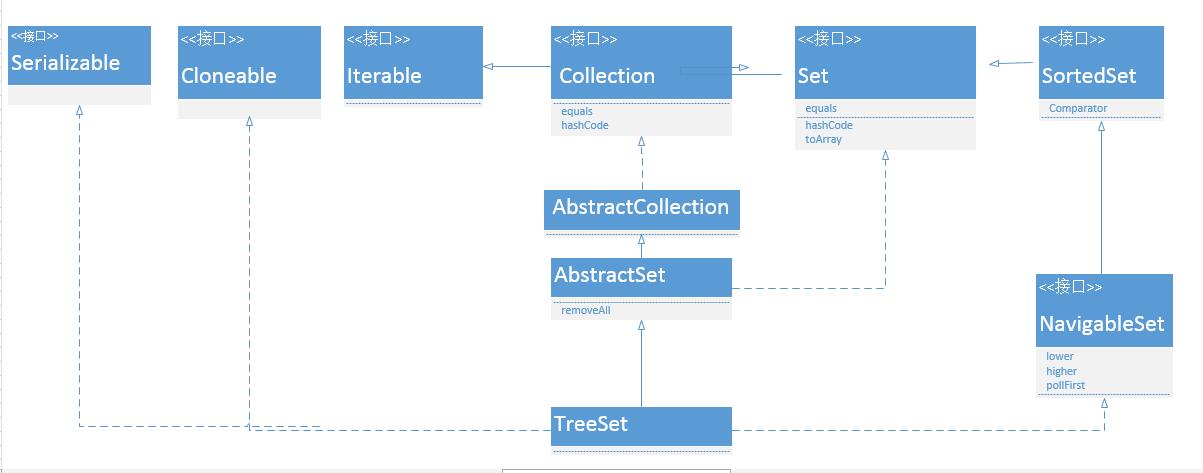
从左到右分析上图:
实现Serializable接口,即支持序列化。
实现Cloneable接口,即能被克隆。
实现Iterable接口,即能用foreach使用迭代器遍历得到集合元素。
实现了NavigableSet接口,即能支持一系列的导航方法。比如查找与指定目标最匹配项。并且,TreeSet中含有一个”NavigableMap类型的成员变量”m,而m实际上是”TreeMap的实例”。
继承AbstractSet,AbstractSet实现set,所以它是一个Set集合,不包含满足element1.eauqals(element2)的元素树,并且最多包含一个null.
所以,TreeSet的本质是一个”有序的,并且没有重复元素”的集合,而且支持自定义排序。
接下来让我们看一下具体的源代码。(基于JDK1.7)
构造函数:
方式一:
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
- 1
- 2
- 3
看NavigableMap的代码是 :
public interface NavigableMap<K,V> extends SortedMap<K,V>
- 1
而SortedMap又是继承Map:
public interface SortedMap<K,V> extends Map<K,V>
- 1
由此,该方式TreeSet初始化时 底层是map
方式二:
// 以自然排序方式创建一个新的 TreeMap,
// 根据该 TreeSet 创建一个 TreeSet,
// 使用该 TreeMap 的 key 来保存 Set 集合的元素
public TreeSet() {
this(new TreeMap<E,Object>());
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
方式三:
// 以定制排序方式创建一个新的 TreeMap,
// 根据该 TreeSet 创建一个 TreeSet,
// 使用该 TreeMap 的 key 来保存 Set 集合的元素
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
方式四:
public TreeSet(Collection<? extends E> c) {
// 调用方式一构造器创建一个 TreeSet,底层以 TreeMap 保存集合元素
this();
// 向 TreeSet 中添加 Collection 集合 c 里的所有元素
addAll(c);
}
- 1
- 2
- 3
- 4
- 5
- 6
从上述可以看出,TreeSet的构造函数都是通过新建一个TreeMap作为实际存储Set元素的容器。因此得出结论: TreeSet的底层实际使用的存储容器就是TreeMap。TreeSet 里绝大部分方法都是直接调用 TreeMap 的方法来实现的。
列举一个,大家也可以自行查看源码。
public boolean addAll(Collection<? extends E> c) {
if (m.size()==0 && c.size() > 0 &&
c instanceof SortedSet &&
m instanceof TreeMap) {
SortedSet<? extends E> set = (SortedSet<? extends E>) c;
//快看!!!我在这!!!
TreeMap<E,Object> map = (TreeMap<E, Object>) m;
Comparator<?> cc = set.comparator();
Comparator<? super E> mc = map.comparator();
if (cc==mc || (cc != null && cc.equals(mc))) {
map.addAllForTreeSet(set, PRESENT);
return true;
}
}
return super.addAll(c);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Set几乎都成了Map的一个马甲 , 我们来关注一下TreeSet应用的TreeMap。
红黑树
对于 TreeMap 而言,它采用一种被称为“红黑树”的排序二叉树,这是一种自平衡排序二叉树,树中每个节点的值,都大于或等于在它的左子树中的所有节点的值,并且小于或等于在它的右子树中的所有节点的值,这确保红黑树运行时可以快速地在树中查找和定位的所需节点。每个 Entry 都被当成“红黑树”的一个节点对待。
红黑树又称红-黑二叉树,它首先是一颗二叉树,它具体二叉树所有的特性。同时红黑树更是一颗自平衡的排序二叉树。
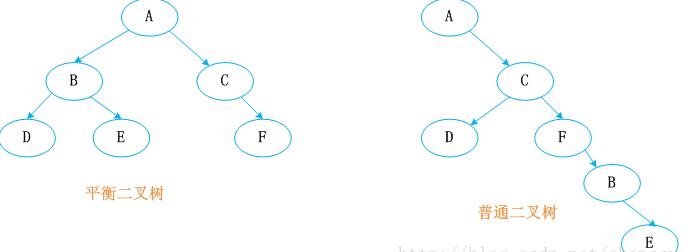
当且仅当两个子树的高度差不超过1时,这个树是平衡二叉树。
通过这种直观的对比,能感受到平衡二叉树比普通二叉树在查找上的优势。平衡二叉树的时间复杂度是log(n),如果二叉树的元素个数为n,那么不管是对树进行插入节点、查找、删除节点都是log(n)次循环调用就可以了。
而红黑树是一种自平衡二叉查找树。放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。不是严格控制左、右子树高度或节点数之差小于等于1。但红黑树高度依然是平均log(n),且最坏情况高度不会超过2log(n)。一个更明显的特点就是红黑树是有颜色区分的。

红黑树中调整位置和改变颜色,相关代码,随意感受一下:
private void fixAfterDeletion(Entry<K,V> x) {
while (x != root && colorOf(x) == BLACK) {
if (x == leftOf(parentOf(x))) {
Entry<K,V> sib = rightOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateLeft(parentOf(x));
sib = rightOf(parentOf(x));
}
if (colorOf(leftOf(sib)) == BLACK &&
colorOf(rightOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(rightOf(sib)) == BLACK) {
setColor(leftOf(sib), BLACK);
setColor(sib, RED);
rotateRight(sib);
sib = rightOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(rightOf(sib), BLACK);
rotateLeft(parentOf(x));
x = root;
}
} else { // symmetric
Entry<K,V> sib = leftOf(parentOf(x));
if (colorOf(sib) == RED) {
setColor(sib, BLACK);
setColor(parentOf(x), RED);
rotateRight(parentOf(x));
sib = leftOf(parentOf(x));
}
if (colorOf(rightOf(sib)) == BLACK &&
colorOf(leftOf(sib)) == BLACK) {
setColor(sib, RED);
x = parentOf(x);
} else {
if (colorOf(leftOf(sib)) == BLACK) {
setColor(rightOf(sib), BLACK);
setColor(sib, RED);
rotateLeft(sib);
sib = leftOf(parentOf(x));
}
setColor(sib, colorOf(parentOf(x)));
setColor(parentOf(x), BLACK);
setColor(leftOf(sib), BLACK);
rotateRight(parentOf(x));
x = root;
}
}
}
setColor(x, BLACK);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
规则:
其红黑树的规则是:
(1)节点是红色或黑色。
(2)根节点是黑色。
(3)每个叶节点(NIL节点,空节点)是黑色的。
(4)每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
(5)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
添加过程:
红黑树的添加原理及TreeMap的put实现过程;
(1)将红黑树当成一颗二叉查找树,将节点插入。
(2)将新插入的节点设置为红色
(3)通过旋转和着色,使它恢复平衡,重新变成一颗符合规则的红黑树。
该部分参考博客TreeMap源码解析: 及视频演示。有兴趣的可以深入研究。
对比:
1. TreeSet和TreeMap
相同点:
TreeMap和TreeSet都是有序的集合。
TreeMap和TreeSet都是非同步集合,因此他们不能在多线程之间共享,不过可以使用方法Collections.synchroinzedMap()来实现同步。
运行速度都要比Hash集合慢,他们内部对元素的操作时间复杂度为O(logN),而HashMap/HashSet则为O(1)。
不同点:
最主要的区别就是TreeSet和TreeMap非别实现Set和Map接口
TreeSet只存储一个对象,而TreeMap存储两个对象Key和Value(仅仅key对象有序)
TreeSet中不能有重复对象,而TreeMap中可以存在。
TreeSet和HashSet
相同点:
都是唯一不重复的Set集合。
不同点:
底层来说,HashSet是用Hash表来存储数据,而TreeSet是用二叉平衡树来存储数据。 功能上来说,由于TreeSet是有序的Set,可以使用SortedSet。接口的first()、last()等方法。但由于要排序,势必要影响速度。所以,如果不需要顺序的话,还是使用HashSet吧,使用Hash表存储数据的HashSet在速度上更胜一筹。如果需要顺序则TreeSet更为明智。
底层来说,HashSet是用Hash表来存储数据,而TreeSet是用二叉平衡树来存储数据。
总结
1、不能有重复的元素;
2、具有排序功能;
3、TreeSet中的元素必须实现Comparable接口并重写compareTo()方法,TreeSet判断元素是否重复 、以及确定元素的顺序 靠的都是这个方法;
①对于java类库中定义的类,TreeSet可以直接对其进行存储,如String,Integer等,因为这些类已经实现了Comparable接口);
②对于自定义类,如果不做适当的处理,TreeSet中只能存储一个该类型的对象实例,否则无法判断是否重复。
4、依赖TreeMap。
5、相对HashSet,TreeSet的优势是有序,劣势是相对读取慢。根据不同的场景选择不同的集合。
转载自 https://blog.csdn.net/u010176014/article/details/52096398