廖雪峰老师的Python教程的笔记
1.格式化
最后一个常见的问题是如何输出格式化的字符串。我们经常会输出类似’亲爱的xxx你好!你xx月的话费是xx,余额是xx’之类的字符串,而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。
你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,%f表示用浮点数替换,%x表示用十六进制整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
其中,格式化整数和浮点数还可以指定是否补0和整数与小数的位数:
print('%2d-%02d' % (3, 1))
3-01
print('%.2f' % 3.1415926)
3.14有些时候,字符串里面的%是一个普通字符怎么办?这个时候就需要转义,用%%来表示一个%:
>>> 'growth rate: %d %%' % 7
'growth rate: 7 %'另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'2.list、tuple、dict、set
List:
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
-- Python定义列表list
classmates = ['Michael', 'Bob', 'Tracy']
-- 用len()函数可以获得list元素的个数
len(classmates)
3
-- 用索引来访问list中每一个位置的元素
classmates[0]
'Michael'
classmates[-1]
'Tracy'
-- 追加元素
classmates.append('Adam')
['Michael','Bob','Tracy','Adam']
-- 把元素插入到指定的位置
classmates.insert(1,'Jack')
-- 要删除list末尾的元素,用pop()方法:
classmates.pop()
-- 要删除指定位置的元素,用pop(i)方法,其中i的索引位置:
classmates.pop(1)
-- 要把某个元素替换成别的元素,可以直接赋值给对应的索引位置
classmates[1] = 'Sarah'
-- list里面的元素的数据类型也可以不同,比如:
L = ['Apple', 123, True]
-- list元素也可以是另一个list,比如:
s = ['python', 'java', ['asp','php'],'scheme']tuple:
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改。
classmates = ('Michael', 'Bob', 'Tracy')现在,classmates这个tuple不能变了,它也没有append(),insert()这样的方法。其他获取元素的方法和list是一样的,你可以正常地使用classmates[0],classmates[-1],但不能赋值成另外的元素。
dict:
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}判断key存不存在,有两种办法,一是通过in判断key是否存在:
>>> 'Thomas' in d
False二是通过dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1注意:返回None的时候Python的交互环境不显示结果。
要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
>>> d.pop('Bob')
75
>>> d
{'Michael': 95, 'Tracy': 85}和list比较,dict有以下几个特点:
查找和插入的速度极快,不会随着key的增加而变慢;
需要占用大量的内存,内存浪费多。
而list的特点:
查找和插入的时间随着元素的增加而增加;
占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
dict可以用在需要高速查找的很多地方,在Python代码中几乎无处不在,正确使用dict非常重要,需要牢记的第一条就是dict的key必须是不可变对象。
set
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合:
>>> x = set('spam')
>>> y = set(['h','a','m'])
>>> x, y
(set(['a', 'p', 's', 'm']), set(['a', 'h', 'm']))重复元素在set中自动被过滤:
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
{1, 2, 3}通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
>>> s.add(4)
>>> s
{1, 2, 3, 4}
>>> s.add(4)
>>> s
{1, 2, 3, 4}通过remove(key)方法可以删除元素:
>>> s.remove(4)
>>> s
{1, 2, 3}set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
>>> s1 = set([1, 2, 3])
>>> s2 = set([2, 3, 4])
>>> s1 & s2
{2, 3}
>>> s1 | s2
{1, 2, 3, 4}set和dict的唯一区别仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。试试把list放入set,看看是否会报错。
>>> a = 'abc'
>>> b = a.replace('a', 'A')
>>> b
'Abc'
>>> a
'abc'要始终牢记的是,a是变量,而’abc’才是字符串对象!有些时候,我们经常说,对象a的内容是’abc’,但其实是指,a本身是一个变量,它指向的对象的内容才是’abc’:

当我们调用a.replace(‘a’, ‘A’)时,实际上调用方法replace是作用在字符串对象’abc’上的,而这个方法虽然名字叫replace,但却没有改变字符串’abc’的内容。相反,replace方法创建了一个新字符串’Abc’并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串’abc’,但变量b却指向新字符串’Abc’了:
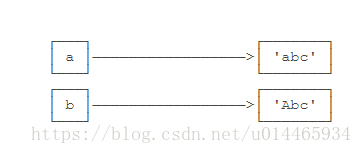
所以,对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
3.函数
数据类型转换:
>>> int('123')
123
>>> int(12.34)
12
>>> float('12.34')
12.34
>>> str(1.23)
'1.23'
>>> str(100)
'100'
>>> bool(1)
True
>>> bool('')
False默认参数:
-- 把第二个参数n的默认值设定为2
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
>>> power(5)
25
>>> power(5, 2)
25可变参数:
在Python函数中,还可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
我们以数学题为例子,给定一组数字a,b,c……,请计算a2 + b2 + c2 + ……。
第一种方法:
要定义出这个函数,我们必须确定输入的参数。由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来,这样,函数可以定义如下:
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum但是调用的时候,需要先组装出一个list或tuple:
>>> calc([1, 2, 3])
14
>>> calc((1, 3, 5, 7))
84第二种方法:
我们把函数的参数改为可变参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum此时,调用函数的方式可以简化成这样:
>>> calc(1, 2, 3)
14
>>> calc(1, 3, 5, 7)
84第三种方法:
如果已经有一个list或者tuple,要调用一个可变参数怎么办?可以这样做:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
nums = [1,2,3]
--我们按照第二种方法的话,可以这样做
calc(nums[0],nums[1],nums[2])
-- 或者,在list或tuple前面加一个*号,把list或tuple得元素变成可变参数传进去
calc(*nums)关键字参数:
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。请看示例:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)函数person除了必选参数name和age外,还接受关键字参数kw。在调用该函数时,可以只传入必选参数:
>>> person('Michael', 30)
name: Michael age: 30 other: {}也可以传入任意个数的关键字参数:
>>> person('Bob', 35, city='Beijing')
name: Bob age: 35 other: {'city': 'Beijing'}
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
和可变参数类似,也可以先组装出一个dict,然后,把该dict转换为关键字参数传进去:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, city=extra['city'], job=extra['job'])
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}当然,上面复杂的调用可以用简化的写法:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}**extra表示把extra这个dict的所有key-value用关键字参数传入到函数的**kw参数,kw将获得一个dict,注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
命名关键字参数:
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job):
print(name, age, city, job)4.切片、迭代
切片:
-- 列表list
L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
>>> L[0:3]
['Michael', 'Sarah', 'Tracy']
>>> L[-2:]
['Bob', 'Jack']
>>> L[-2:-1]
['Bob']
-- 元组tuple
>>> (0, 1, 2, 3, 4, 5)[:3]
(0, 1, 2)
-- 字符串
>>> 'ABCDEFG'[:3]
'ABC'
>>> 'ABCDEFG'[::2]
'ACEG'迭代:
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。
Python的for循环不仅可用在list或tuple上,还可以作用在其他可迭代对象上。
>>> d = {'a': 1, 'b': 2, 'c': 3}
>>> for key in d:
... print(key)
...
a
c
b默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
由于字符串也是可迭代对象,因此,也可以作用于for循环:
>>> for ch in 'ABC':
... print(ch)
...
A
B
C那么,如何判断一个对象是可迭代对象呢?方法是通过collections模块的Iterable类型判断:
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list是否可迭代
True
>>> isinstance(123, Iterable) # 整数是否可迭代
False最后一个小问题,如果要对list实现类似Java那样的下标循环怎么办?Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
>>> for i, value in enumerate(['A', 'B', 'C']):
... print(i, value)
...
0 A
1 B
2 C上面的for循环里,同时引用了两个变量,在Python里是很常见的,比如下面的代码:
>>> for x, y in [(1, 1), (2, 4), (3, 9)]:
... print(x, y)
...
1 1
2 4
3 9