zookeeper是分布式应用的分布式、开放式协调服务。它公开了一组简单的原语,分布式应用程序可以构建来实现更高级别的服务,用于同步、配置维护、组和命名。它被设计成易于编程,并使用在熟悉文件系统目录树结构之后的数据模型。它在java环境上运行,并对Java和C都有绑定。
众所周知,协调服务很难得到正确的结果。它们特别容易出现错误,如race conditions和死锁。zookeeper背后的动机是减轻分布式应用程序从零开始执行协调服务的责任。
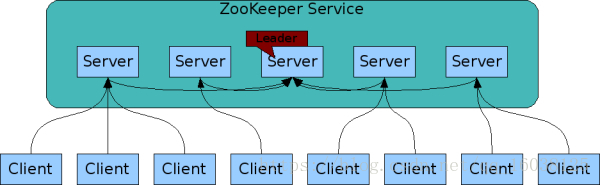
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
允许分布式进程通过类似于标准文件系统组织的共享层次命名空间进行协调。名称空间由数据寄存器(称为ZNODE)组成,它们与文件和目录类似。不像一个典型的文件系统,它被设计用于存储,数据被保存在内存中,这意味着可以获得高吞吐量和低延迟数。
实现了高性能、高可用、严格有序的访问。性能方面意味着它可以用于大型、分布式系统。可靠性方面使它不能成为一个单一的故障点。严格排序意味着复杂的同步原语可以在客户端实现。
被复制。像它所协调的分布式进程一样,zookeeper本身也要在一组称为集合的主机上复制。
组成zookeeper服务的服务器必须彼此了解。它们维护状态的内存映像,以及持久存储中的事务日志和快照。只要大多数服务器可用,zookeeper服务将是可用的。
客户端连接到一个zookeeper服务器。客户端维护一个TCP连接,通过该连接,它发送请求,得到响应,得到监视事件,并发送心跳。如果到服务器的TCP连接中断,客户端将连接到不同的服务器。
zookeeper是顺序性的。zookeeper用一个数字反映每个动物园管理员交易的顺序。后续操作可以使用顺序来实现更高级的抽象,例如同步原语。
zookeeper很快。它特别快,在“read占主导地位”的工作量。zookeeper应用程序运行在数千台机器上,它的读取效果最好,以10:1左右的比率比写入更常见。