学习网址:https://www.icourse163.org/learn/BIT-1001870001?tid=1002781006
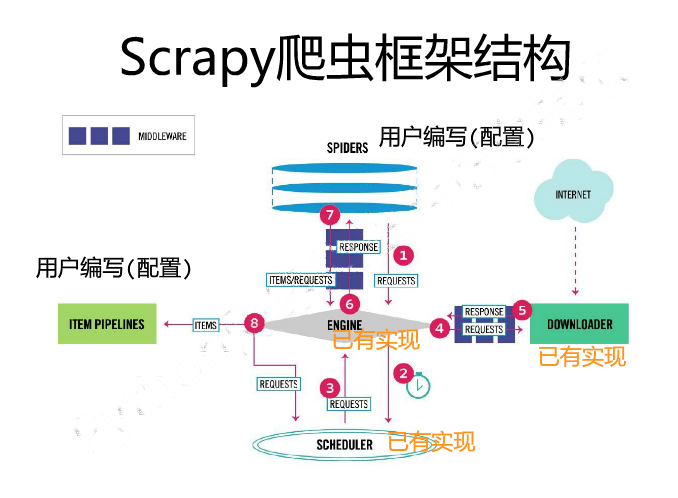
Scrapy 不是一个功能库,而是一个爬虫框架。
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。
爬虫框架是一个半成品,能够帮助用户实现专业的网络爬虫。
1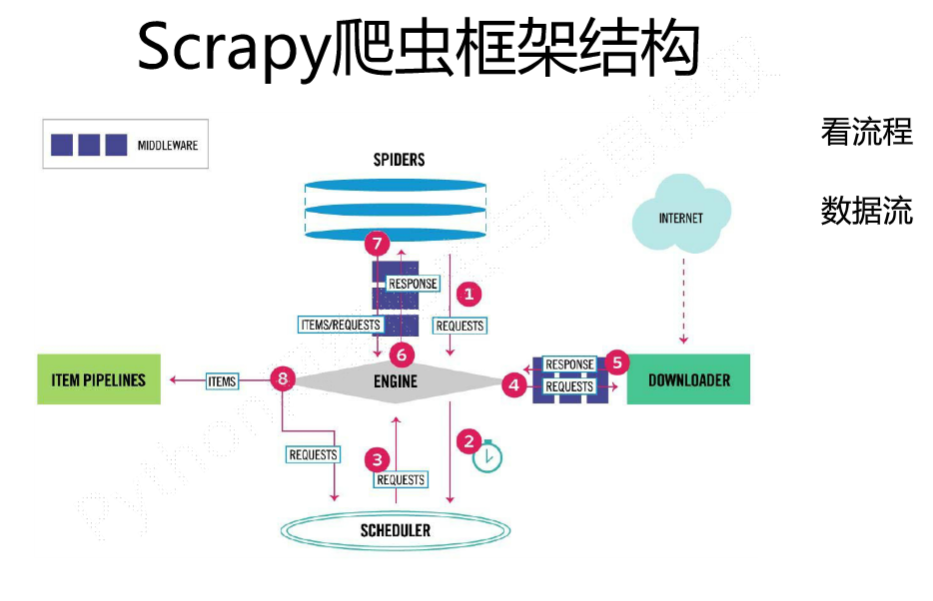
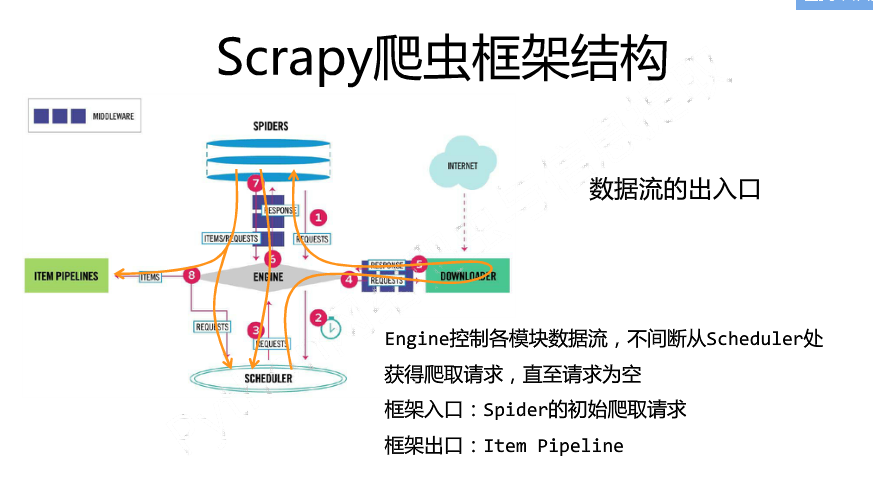
1 Engine从Spider处获取爬取请求(request)
2 Engine将爬取请求转发给Scheduler,用于调度
3 Engine从Scheduler处获得下个爬取的请求
4 Engine将爬取请求通过中间发送给Downloader
5 爬取网页后,Downloader形成响应(Response)通过中间件发给Engine
6 Engine将收到的响应通过中间件发送给Spider处理
7 Spider处理响应后产生爬取项(scraped Item)和新的爬取请求(Requests)给Engine
8 Engine将爬取项发送给Item Pipeline(框架出口)
9 Engine将爬取请求发送给Scheduler