前言
随着互联网行业的高速发展,一些商业的存储解决方案的成本越来越高;大部分企业开始寻求开源的存储解决方案,成为互联网商业存储的首选。下面以mysql为例,介绍下数据库的扩展方案。
根据业务域垂直拆分
首先是根据业务域进行拆分。以前可能所有的业务表是耦合在一个数据库中,这种模式下,系统的复杂性越来越大,开发维护成本越来越大,开发效率越来越低,系统的资源成本也会越来越大。
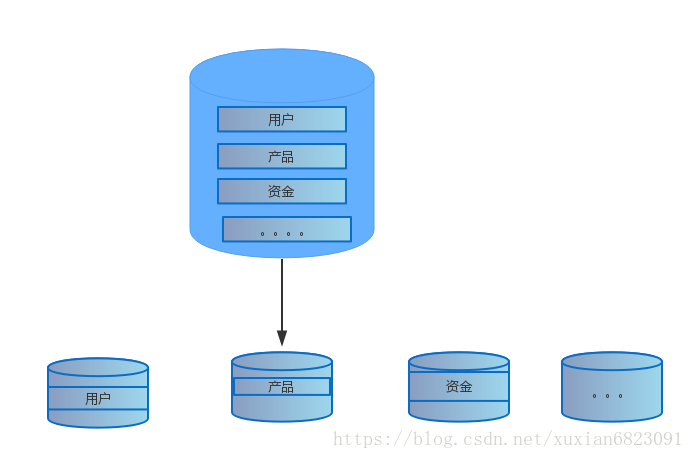
优点:所以需要从业务域的粒度层面进行拆分,每一块业务域都有自己的单独数据库,不同的业务访问不同的库,这样库的压力自然而然下降了。
缺点:由于拆分成不同的业务域,多表的CURD会有分布式事务以及跨库join等问题。
当然解决方式有很多,跨库join可以考虑全局表,可以生成以查询唯独的异步。
分布式事务可以考虑通过补偿达到最终一致性,这也是目前微服务架构中最常用的一种解决方案。
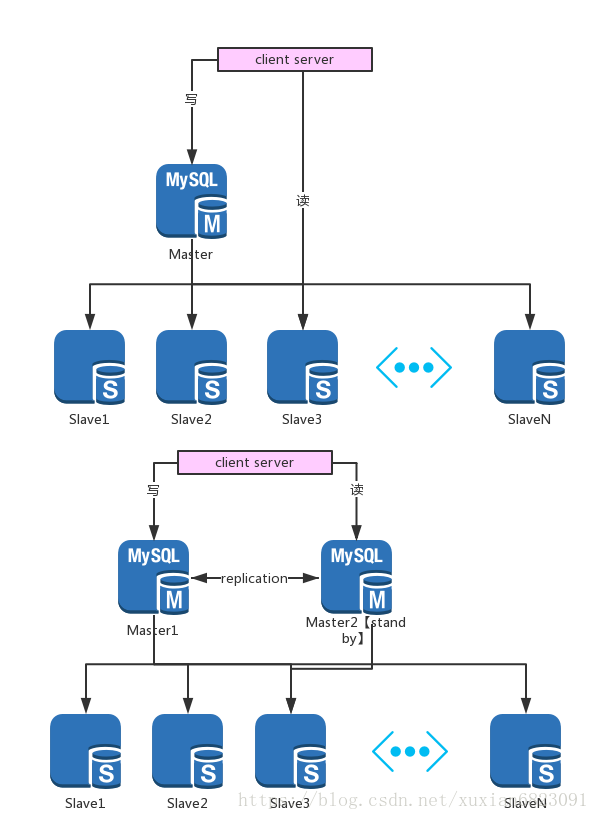
主从复制,读写分离
随着业务量的不断发展,单张业务表可能会遇到瓶颈;很多表可能会存在读多写少的问题,这时候我们可能考虑需要通过主从复制,读写分离来解决,将读与写分成几个库。开启master的Binary log;数据复制是slave通过master获取binary log,在本地镜像的执行日志中记录的操作。
大概有以下2种复制架构
1.单master,多slave的架构
缺点:单master会存在单点故障的问题,不利于升级维护;Master停机可能会导致整体应用都无法访问。
2.双master,多slave的架构
两台mysql服务器互相将对方作为自己的master,自己作为对方的slave;通过主从复制机制同步到对方的服务器数据。一般情况下,只会让其中一台master提供写入服务,另外一台作为读库。
分库分表
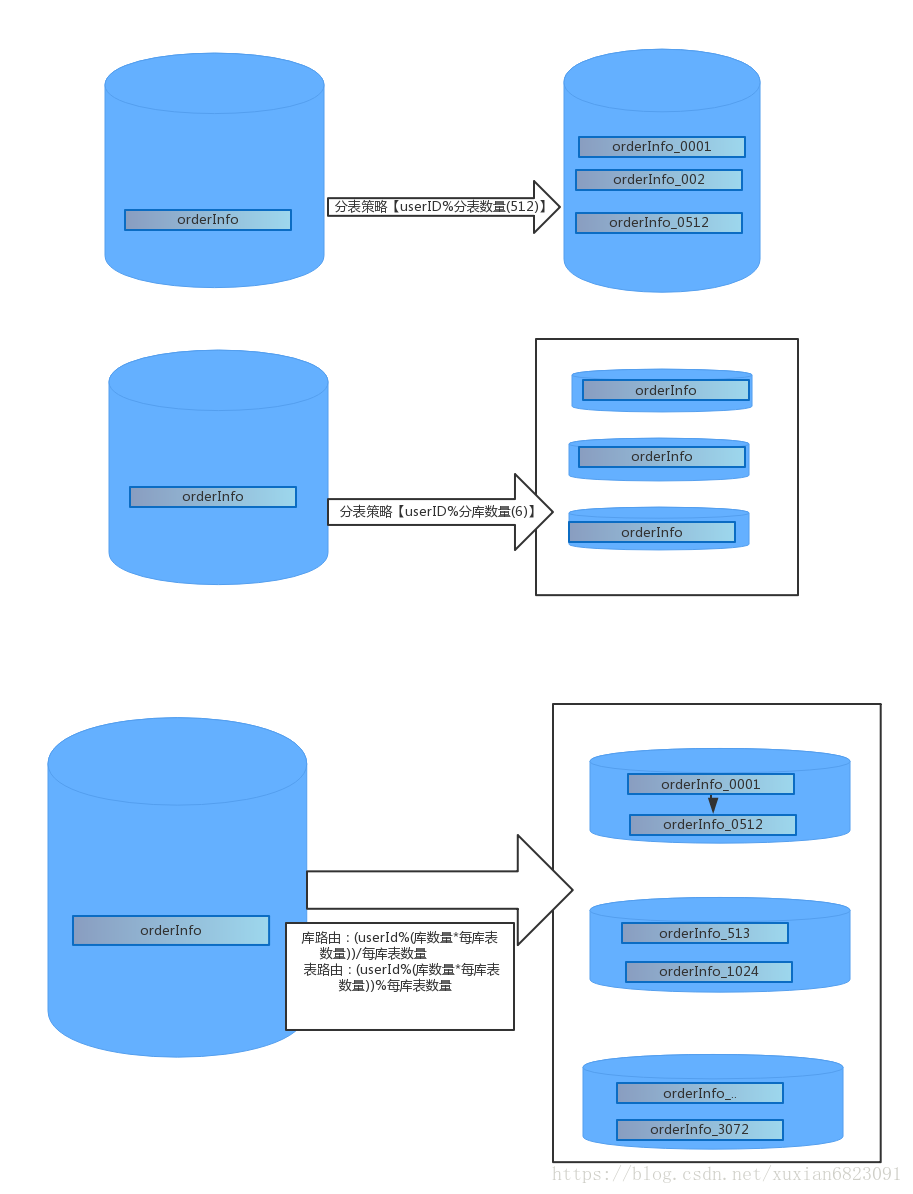
分表:
数量量达到千万级以后,主从架构可能还是不太合适,只能对读数据库进行扩展,无法对写进行扩展,写基本上还是集中在master中。 所以我们还是需要减少单表的记录条数,进而减少数据查询的时间,提高吞吐量,也就是我们说的分表。可以通过对一个关键字对分库数量取模的方式,
分库:
分表能解决单表数据量太大的问题, 但是无法解决数据库的并发处理能力,我们可以通过对一个关键字对分库数量取模的方式,对数据访问进行数据库的路由。
分库分表:
既可以解决单表海量数据的问题, 又可以提高数据库的并发处理能力。