矩阵快速幂的基础是乘法快速幂,乘法快速幂可以看完全理解乘法快速幂及其两种写法的解析,只不过an=?an=?换成了
我们可以写一个矩阵类Matrix,然后在类中重载*运算符,+运算符,然后把乘法快速幂中的mul函数写成一个模板函数,这样,就可以无缝使用乘法快速幂的方法来计算矩阵快速幂了。
mul(快速幂)模板化
用模板泛化乘法快速幂,使其适合矩阵的运算。
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Matrix(矩阵类)实现
这个就要好好说说了,首先Matrix的成员变量选择了二维数组,没有使用指针,这是为了避免浅拷贝,同时也是为了少写拷贝构造,拷贝复制,析构函数;同时,选择了二维数组,那么数组长度就用模板的参数,同时,二维数组的数据类型也用模板参数,这是为了什么?是为了矩阵中套矩阵,这样也是把Matrix类设计地更灵活,更大气。
同时,矩阵的取模得在矩阵内部进行,而mul中用到了%运算符,因此在Matrix中还得重载下%运算符,但是%运算符不做任何事。
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
Matrix的设计肯定还可以更优,但是对应付题目来说已经够了,你可以试着把我的这个Matrix改得更优,性能更好。
矩阵快速幂的一个例子
哪个地方会直接用到矩阵快速幂,对,就是图论中求对应两个点长度为n的路径数,这是矩阵乘法在图论中的经典应用,其实就是用到了矩阵乘法的特殊性,因为矩阵乘法有三重循环,最里面的一层循环就是在枚举一个点k,i -> k -> j,那么从i -> j的路径数长度为m的条数就等于i-> k路径长度为n的路径数乘上k -> j路径长度为m - n的的路径条数,枚举的过程中全加起来,可以看到,这个过程和矩阵乘法的过程是一样的。
矩阵AnAn中的ai,jai,j表示:图中点ii到点jj经过nn条边的路径数。
给出一个例子,题目链接:HDU2157 - How many ways??。
题目的大意就是让你求你从A点到B点恰好经过k个点的路径数。
其实你只要把上面那段分析中的边换成点,再读一遍,你会发现这个题目就是用矩阵乘法来做,然后快速幂加速就好了。
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
#define MOD 1000LL
#define MAX_N 25
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
int main()
{
for (int n, m, t; cin >> n >> m && n + m; ) {
Matrix<LL, MAX_N> a, b;
for (int i = 0, from, to; i < m; i++)
cin >> from >> to, a.data[from][to] = 1;
for (cin >> t; t--; ) {
int from, to, k;
cin >> from >> to >> k;
b = mul(a, k, MOD);
cout << b.data[from][to] << endl;
}
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
矩阵快速幂的简单应用(4个题)
上面那个例子是矩阵快速幂最直接最直接的用法,而矩阵快速幂用得最多的地方就是加速递推式的计算,最简单的就是快速计算斐波拉契数列。
POJ3070 - Fibonacci
题目链接:点这儿。
题目的意思就是让你求第nn项斐波拉契数列FnFn。数据范围:n≤109n≤109。
直接算肯定是超时的,所以题目中给了你一种矩阵的形式去计算斐波拉契数列: 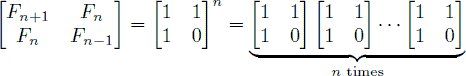
因此直接写出矩阵快速幂就行了。
#include <string.h>
#include <iostream>
using namespace std;
typedef long long LL;
#define MOD 10000LL
#define MAX_N 2
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
const LL modulu[MAX_N][MAX_N] = {
{1, 1},
{1, 0}
};
int main()
{
for (LL n; cin >> n && n + 1; ) {
Matrix<LL, MAX_N> a;
if (n < 2) {
cout << n << endl;
continue;
}
memcpy(a.data, modulu, sizeof(modulu));
cout << mul(a, n, MOD).data[0][1] << endl;
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
这个题是题目给你构建好了一个矩阵,其实我们常用的矩阵构造不是像题目这样的,当然啦,什么样的构造方式都无所谓啦,只要你觉得好用就行,这里我给出我的构造形式。
斐波拉契数列:Fi=Fi−1+Fi−2Fi=Fi−1+Fi−2:
递推式 - 1:Gi=a×Gi−1+b×Gi−2Gi=a×Gi−1+b×Gi−2 :
递推式 - 2:Gi=a×Gi−1+i2Gi=a×Gi−1+i2 :
递推式 - 3:Gi=a×Gi−1+i3Gi=a×Gi−1+i3 :
递推式 - 4:Gi=a×Gi−1+biGi=a×Gi−1+bi :
这里放出五个式子的原因是让你系统地感受下如何根据递推式去构造矩阵快速幂,至于其中的细节,你亲自做一下矩阵乘法就知道了。
其实就是要把递推式变成下面这种形式就好了:
AA是一个方阵,而BB是一个列向量(具有通项的列向量)。最后的答案就是AnAn的第一行与B0B0相乘的结果。
2018年湘潭大学程序设计竞赛 - G:又见斐波拉契
题目链接:点这儿。
这个题目让你求斐波拉契数列的加强版的加强版:
数据范围是1≤n≤10181≤n≤1018。很明显的矩阵快速幂加速运算。
把上面的几个递推式的矩阵形式综合一下,可以得到下列的矩阵形式:
然后就套用模板直接写出下面的代码了。
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
#define MOD 1000000007LL
#define MAX_N 6
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
const LL modulu[MAX_N][MAX_N] = {
{1, 1, 1, 1, 1, 1},
{1, 0, 0, 0, 0, 0},
{0, 0, 1, 3, 3, 1},
{0, 0, 0, 1, 2, 1},
{0, 0, 0, 0, 1, 1},
{0, 0, 0, 0, 0, 1}
};
int main()
{
int T;
cin >> T;
for (LL n; T--; ) {
cin >> n;
if (n <= 1) {
cout << n << endl;
continue;
}
Matrix<LL, MAX_N> a;
memcpy(a.data, modulu, sizeof(modulu));
a = mul(a, n - 1, MOD);
cout << (a.data[0][0] * 1 + a.data[0][1] * 0 + a.data[0][2] * 8 +
a.data[0][3] * 4 + a.data[0][4] * 2 + a.data[0][5]) % MOD << endl;
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
HDU1757 - A Simple Math Problem
题目链接:点这儿。
有了上面几个题目,这个题就很明显了,只不过这个题的矩阵的维数是10,矩阵关系式我就不写了,我相信你也会写了。
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
LL MOD = 1LL;
#define MAX_N 10
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
LL modulu[MAX_N][MAX_N];
int main()
{
for (LL k; cin >> k >> MOD; ) {
LL arr[MAX_N];
for (int i = 0; i < MAX_N; cin >> arr[i++]) {}
if (k < MAX_N) {
cout << k % MOD << endl;
continue;
}
// construct modulus matrix
memset(modulu, 0, sizeof(modulu));
for (int i = 0; i < 9; modulu[1 + i][i] = 1, ++i) {}
memcpy(modulu[0], arr, sizeof(arr));
// use modulus matrix to init a
Matrix<LL, MAX_N> a;
memcpy(a.data, modulu, sizeof(modulu));
a = mul(a, k - 9, MOD);
LL ans = 0;
for (int i = 0; i < MAX_N; i++)
ans = (ans + a.data[0][i] * (MAX_N - i - 1) % MOD) % MOD;
cout << ans << endl;
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
POJ3233 - Matrix Power Series
题目链接:点这儿。
这个题看起来很好做是吧,矩阵快速幂,然后把矩阵全部加起来,但是,光是这个加的操作就会超时。因此,我们先不要管AiAi,我们先把AA当一个变量;
然后剩下的就是Sn=∑ni=1Ai=∑n−1i=1Ai+An=Sn−1+AnSn=∑i=1nAi=∑i=1n−1Ai+An=Sn−1+An,这就是一个递推式,我们可以直接根据递推式-4写出矩阵形式:
这也是我为什么把这个题拿出来的原因,可以看到这个矩阵是矩阵套矩阵,也就是分块矩阵,这也就体现了Matrix模板设计和操作符重载的优势。
#include <stdio.h>
#include <iostream>
using namespace std;
typedef long long LL;
LL MOD = 1LL;
#define MAX_N 30
int NN;
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
// 不加下面这条语句会超时,这也是Matrix类的一个弊端吧,\
二维数组的长度不能在运行时确定,建议用vector代替二维数组。
n = n > 2 ? NN : n;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
int main()
{
for (LL n, k; EOF != scanf("%lld%lld%lld", &n, &k, &MOD); ) {
NN = n;
Matrix<LL, MAX_N> O, E(1), A;
Matrix<Matrix<LL, MAX_N>, 2> a;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
scanf("%lld", &A.data[i][j]);
a.data[0][0] = a.data[0][1] = E;
a.data[1][0] = O;
a.data[1][1] = A;
A = mul(a, k, MOD).data[0][1] * A;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
printf("%lld%c", A.data
[i][j], j == n - 1 ? '\n' : ' ');
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
这个题也可以用二分 + 矩阵快速幂做,看下面这个式子:
可以发现,要算SnSn,只需要算Sn2Sn2,……,这样子下去,你只需要递归lognlogn次就可以算出答案了。
这里给出我早年用JAVA写的这个代码:
import java.util.Scanner;
public class Main {
Scanner cin = new Scanner(System.in);
static final int N = 30 + 5;
int n, k, m;
public Main() {
while (cin.hasNext()) {
n = cin.nextInt();
k = cin.nextInt();
m = cin.nextInt();
int[][] a = new int[N][N];
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
a[i][j] = cin.nextInt();
Matrix A = new Matrix(a, n, m);
Matrix ans = cal(A, k);
ans.print();
}
}
Matrix powMatrix(Matrix m, int num) {
Matrix single = m, ans = new Matrix();
ans.setOne();
while (num != 0) {
if (num % 2 == 1)
ans=ans.mul(single);
single=single.mul(single);
num >>= 1;
}
return ans;
}
Matrix cal(Matrix A, int num) {
if (num == 1)
return A;
Matrix tmp = new Matrix();
tmp.setZero();
if (num % 2 == 1) {
tmp = powMatrix(A, num);
--num;
}
Matrix t = cal(A, num / 2);
return tmp.add(t.add(t.mul(powMatrix(A, num / 2))));
}
public static void main(String[] args) {
new Main();
}
}
class Matrix {
static final int N = 30 + 5;
int[][] a = new int[N][N];
static int n;
static int MOD;
Matrix() {
}
Matrix(int[][] a, int N, int M) {
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
this.a[i][j] = a[i][j] % M;
n = N;
MOD = M;
}
void setZero() {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
a[i][j] = 0;
}
void setOne() {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
a[i][j] = 0;
for (int i = 0; i < n; i++)
a[i][i] = 1;
}
void setAIJ(int i, int j, int v) {
a[i][j] = v % MOD;
}
Matrix mul(Matrix m) {
Matrix tmp = new Matrix();
tmp.setZero();
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++) {
int sum = 0;
for (int k = 0; k < n; k++)
sum = (sum % MOD + a[i][k] * m.a[k][j] % MOD) % MOD;
tmp.setAIJ(i, j, sum);
}
return tmp;
}
Matrix add(Matrix m) {
Matrix tmp = new Matrix();
tmp.setZero();
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
tmp.setAIJ(i, j, (a[i][j] + m.a[i][j]) % MOD);
return tmp;
}
void print() {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
System.out.print(a[i][j] + (j == n - 1 ? "\n" : " "));
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
矩阵快速幂的中级应用(4个题)
待写。
总结
其实矩阵快速幂的用法很多,只要能用矩阵乘法做的事情,一般都要用矩阵快速幂来假设,矩阵快速幂是你必须掌握的一门技术,难的地方就是你如何把一个问题拨开,然后试着用矩阵乘法来建模。比如用矩阵快速幂来加速递推式,难就难在你要先求出递推式,然后才能去加速,所以还是要努力啊。
矩阵快速幂的基础是乘法快速幂,乘法快速幂可以看完全理解乘法快速幂及其两种写法的解析,只不过an=?an=?换成了
我们可以写一个矩阵类Matrix,然后在类中重载*运算符,+运算符,然后把乘法快速幂中的mul函数写成一个模板函数,这样,就可以无缝使用乘法快速幂的方法来计算矩阵快速幂了。
mul(快速幂)模板化
用模板泛化乘法快速幂,使其适合矩阵的运算。
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Matrix(矩阵类)实现
这个就要好好说说了,首先Matrix的成员变量选择了二维数组,没有使用指针,这是为了避免浅拷贝,同时也是为了少写拷贝构造,拷贝复制,析构函数;同时,选择了二维数组,那么数组长度就用模板的参数,同时,二维数组的数据类型也用模板参数,这是为了什么?是为了矩阵中套矩阵,这样也是把Matrix类设计地更灵活,更大气。
同时,矩阵的取模得在矩阵内部进行,而mul中用到了%运算符,因此在Matrix中还得重载下%运算符,但是%运算符不做任何事。
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
Matrix的设计肯定还可以更优,但是对应付题目来说已经够了,你可以试着把我的这个Matrix改得更优,性能更好。
矩阵快速幂的一个例子
哪个地方会直接用到矩阵快速幂,对,就是图论中求对应两个点长度为n的路径数,这是矩阵乘法在图论中的经典应用,其实就是用到了矩阵乘法的特殊性,因为矩阵乘法有三重循环,最里面的一层循环就是在枚举一个点k,i -> k -> j,那么从i -> j的路径数长度为m的条数就等于i-> k路径长度为n的路径数乘上k -> j路径长度为m - n的的路径条数,枚举的过程中全加起来,可以看到,这个过程和矩阵乘法的过程是一样的。
矩阵AnAn中的ai,jai,j表示:图中点ii到点jj经过nn条边的路径数。
给出一个例子,题目链接:HDU2157 - How many ways??。
题目的大意就是让你求你从A点到B点恰好经过k个点的路径数。
其实你只要把上面那段分析中的边换成点,再读一遍,你会发现这个题目就是用矩阵乘法来做,然后快速幂加速就好了。
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
#define MOD 1000LL
#define MAX_N 25
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
int main()
{
for (int n, m, t; cin >> n >> m && n + m; ) {
Matrix<LL, MAX_N> a, b;
for (int i = 0, from, to; i < m; i++)
cin >> from >> to, a.data[from][to] = 1;
for (cin >> t; t--; ) {
int from, to, k;
cin >> from >> to >> k;
b = mul(a, k, MOD);
cout << b.data[from][to] << endl;
}
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
矩阵快速幂的简单应用(4个题)
上面那个例子是矩阵快速幂最直接最直接的用法,而矩阵快速幂用得最多的地方就是加速递推式的计算,最简单的就是快速计算斐波拉契数列。
POJ3070 - Fibonacci
题目链接:点这儿。
题目的意思就是让你求第nn项斐波拉契数列FnFn。数据范围:n≤109n≤109。
直接算肯定是超时的,所以题目中给了你一种矩阵的形式去计算斐波拉契数列:
因此直接写出矩阵快速幂就行了。
#include <string.h>
#include <iostream>
using namespace std;
typedef long long LL;
#define MOD 10000LL
#define MAX_N 2
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
const LL modulu[MAX_N][MAX_N] = {
{1, 1},
{1, 0}
};
int main()
{
for (LL n; cin >> n && n + 1; ) {
Matrix<LL, MAX_N> a;
if (n < 2) {
cout << n << endl;
continue;
}
memcpy(a.data, modulu, sizeof(modulu));
cout << mul(a, n, MOD).data[0][1] << endl;
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
这个题是题目给你构建好了一个矩阵,其实我们常用的矩阵构造不是像题目这样的,当然啦,什么样的构造方式都无所谓啦,只要你觉得好用就行,这里我给出我的构造形式。
斐波拉契数列:Fi=Fi−1+Fi−2Fi=Fi−1+Fi−2:
递推式 - 1:Gi=a×Gi−1+b×Gi−2Gi=a×Gi−1+b×Gi−2 :
递推式 - 2:Gi=a×Gi−1+i2Gi=a×Gi−1+i2 :
递推式 - 3:Gi=a×Gi−1+i3Gi=a×Gi−1+i3 :
递推式 - 4:Gi=a×Gi−1+biGi=a×Gi−1+bi :
这里放出五个式子的原因是让你系统地感受下如何根据递推式去构造矩阵快速幂,至于其中的细节,你亲自做一下矩阵乘法就知道了。
其实就是要把递推式变成下面这种形式就好了:
AA是一个方阵,而BB是一个列向量(具有通项的列向量)。最后的答案就是AnAn的第一行与B0B0相乘的结果。
2018年湘潭大学程序设计竞赛 - G:又见斐波拉契
题目链接:点这儿。
这个题目让你求斐波拉契数列的加强版的加强版:
数据范围是1≤n≤10181≤n≤1018。很明显的矩阵快速幂加速运算。
把上面的几个递推式的矩阵形式综合一下,可以得到下列的矩阵形式:
然后就套用模板直接写出下面的代码了。
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
#define MOD 1000000007LL
#define MAX_N 6
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
const LL modulu[MAX_N][MAX_N] = {
{1, 1, 1, 1, 1, 1},
{1, 0, 0, 0, 0, 0},
{0, 0, 1, 3, 3, 1},
{0, 0, 0, 1, 2, 1},
{0, 0, 0, 0, 1, 1},
{0, 0, 0, 0, 0, 1}
};
int main()
{
int T;
cin >> T;
for (LL n; T--; ) {
cin >> n;
if (n <= 1) {
cout << n << endl;
continue;
}
Matrix<LL, MAX_N> a;
memcpy(a.data, modulu, sizeof(modulu));
a = mul(a, n - 1, MOD);
cout << (a.data[0][0] * 1 + a.data[0][1] * 0 + a.data[0][2] * 8 +
a.data[0][3] * 4 + a.data[0][4] * 2 + a.data[0][5]) % MOD << endl;
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
HDU1757 - A Simple Math Problem
题目链接:点这儿。
有了上面几个题目,这个题就很明显了,只不过这个题的矩阵的维数是10,矩阵关系式我就不写了,我相信你也会写了。
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
LL MOD = 1LL;
#define MAX_N 10
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
LL modulu[MAX_N][MAX_N];
int main()
{
for (LL k; cin >> k >> MOD; ) {
LL arr[MAX_N];
for (int i = 0; i < MAX_N; cin >> arr[i++]) {}
if (k < MAX_N) {
cout << k % MOD << endl;
continue;
}
// construct modulus matrix
memset(modulu, 0, sizeof(modulu));
for (int i = 0; i < 9; modulu[1 + i][i] = 1, ++i) {}
memcpy(modulu[0], arr, sizeof(arr));
// use modulus matrix to init a
Matrix<LL, MAX_N> a;
memcpy(a.data, modulu, sizeof(modulu));
a = mul(a, k - 9, MOD);
LL ans = 0;
for (int i = 0; i < MAX_N; i++)
ans = (ans + a.data[0][i] * (MAX_N - i - 1) % MOD) % MOD;
cout << ans << endl;
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
POJ3233 - Matrix Power Series
题目链接:点这儿。
这个题看起来很好做是吧,矩阵快速幂,然后把矩阵全部加起来,但是,光是这个加的操作就会超时。因此,我们先不要管AiAi,我们先把AA当一个变量;
然后剩下的就是Sn=∑ni=1Ai=∑n−1i=1Ai+An=Sn−1+AnSn=∑i=1nAi=∑i=1n−1Ai+An=Sn−1+An,这就是一个递推式,我们可以直接根据递推式-4写出矩阵形式:
这也是我为什么把这个题拿出来的原因,可以看到这个矩阵是矩阵套矩阵,也就是分块矩阵,这也就体现了Matrix模板设计和操作符重载的优势。
#include <stdio.h>
#include <iostream>
using namespace std;
typedef long long LL;
LL MOD = 1LL;
#define MAX_N 30
int NN;
template<typename T, int N = 1>
struct Matrix {
Matrix(int f = 0) : n(sizeof(data[0]) / sizeof(data[0][0])) {
// 不加下面这条语句会超时,这也是Matrix类的一个弊端吧,\
二维数组的长度不能在运行时确定,建议用vector代替二维数组。
n = n > 2 ? NN : n;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
data[i][j] = T(0);
if (f)
for (int i = 0; i < n; data[i][i] = T(1), ++i) {}
}
Matrix operator * (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
for (int k = 0; k < n; k++)
ret.data[i][j] = (ret.data[i][j] + data[i][k] * other.data[k][j] % MOD) % MOD;
return ret;
}
Matrix operator + (const Matrix& other) const {
Matrix<T, N> ret;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
ret.data[i][j] = (data[i][j] + other.data[i][j]) % MOD;
return ret;
}
Matrix& operator % (const LL mod) {
return *this;
}
T data[N][N];
int n;
};
template<typename T>
T mul(T a, LL n, LL mod)
{
T ret(1);
for (; n; n >>= 1) {
ret = ret * (n & 1 ? a : T(1)) % mod;
a = a * a % mod;
}
return ret;
}
int main()
{
for (LL n, k; EOF != scanf("%lld%lld%lld", &n, &k, &MOD); ) {
NN = n;
Matrix<LL, MAX_N> O, E(1), A;
Matrix<Matrix<LL, MAX_N>, 2> a;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
scanf("%lld", &A.data[i][j]);
a.data[0][0] = a.data[0][1] = E;
a.data[1][0] = O;
a.data[1][1] = A;
A = mul(a, k, MOD).data[0][1] * A;
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
printf("%lld%c", A.data
[i][j], j == n - 1 ? '\n' : ' ');
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
这个题也可以用二分 + 矩阵快速幂做,看下面这个式子:
可以发现,要算SnSn,只需要算Sn2Sn2,……,这样子下去,你只需要递归lognlogn次就可以算出答案了。
这里给出我早年用JAVA写的这个代码:
import java.util.Scanner;
public class Main {
Scanner cin = new Scanner(System.in);
static final int N = 30 + 5;
int n, k, m;
public Main() {
while (cin.hasNext()) {
n = cin.nextInt();
k = cin.nextInt();
m = cin.nextInt();
int[][] a = new int[N][N];
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
a[i][j] = cin.nextInt();
Matrix A = new Matrix(a, n, m);
Matrix ans = cal(A, k);
ans.print();
}
}
Matrix powMatrix(Matrix m, int num) {
Matrix single = m, ans = new Matrix();
ans.setOne();
while (num != 0) {
if (num % 2 == 1)
ans=ans.mul(single);
single=single.mul(single);
num >>= 1;
}
return ans;
}
Matrix cal(Matrix A, int num) {
if (num == 1)
return A;
Matrix tmp = new Matrix();
tmp.setZero();
if (num % 2 == 1) {
tmp = powMatrix(A, num);
--num;
}
Matrix t = cal(A, num / 2);
return tmp.add(t.add(t.mul(powMatrix(A, num / 2))));
}
public static void main(String[] args) {
new Main();
}
}
class Matrix {
static final int N = 30 + 5;
int[][] a = new int[N][N];
static int n;
static int MOD;
Matrix() {
}
Matrix(int[][] a, int N, int M) {
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
this.a[i][j] = a[i][j] % M;
n = N;
MOD = M;
}
void setZero() {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
a[i][j] = 0;
}
void setOne() {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
a[i][j] = 0;
for (int i = 0; i < n; i++)
a[i][i] = 1;
}
void setAIJ(int i, int j, int v) {
a[i][j] = v % MOD;
}
Matrix mul(Matrix m) {
Matrix tmp = new Matrix();
tmp.setZero();
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++) {
int sum = 0;
for (int k = 0; k < n; k++)
sum = (sum % MOD + a[i][k] * m.a[k][j] % MOD) % MOD;
tmp.setAIJ(i, j, sum);
}
return tmp;
}
Matrix add(Matrix m) {
Matrix tmp = new Matrix();
tmp.setZero();
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
tmp.setAIJ(i, j, (a[i][j] + m.a[i][j]) % MOD);
return tmp;
}
void print() {
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
System.out.print(a[i][j] + (j == n - 1 ? "\n" : " "));
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
矩阵快速幂的中级应用(4个题)
待写。
总结
其实矩阵快速幂的用法很多,只要能用矩阵乘法做的事情,一般都要用矩阵快速幂来假设,矩阵快速幂是你必须掌握的一门技术,难的地方就是你如何把一个问题拨开,然后试着用矩阵乘法来建模。比如用矩阵快速幂来加速递推式,难就难在你要先求出递推式,然后才能去加速,所以还是要努力啊。