基础知识点
Buddy system是linux内核中大名鼎鼎的页面管理子系统,它潜伏在linux内核底层,看起来神秘而难以捉摸。然而当揭开它神秘的面纱,才发现大道至简。如果让我用两个词来描述buddy system,我会选择:简单,优雅。
什么是buddy system?
buddy是伙伴的意思,buddy system就是伙伴系统。在人的社交中,伙伴是两个关系比较近的人,而在页面的社交中,伙伴是两块挨着的pageblock(一组连续的pages)。当两个小伙伴其中一个有任务时,比如被网卡驱动叫过去接受报文,两个小伙伴就会分开;而当任务完成后,比如报文已经被处理完毕,页面被释放,两个小伙伴又会重新团聚,手拉手合二为一。这里先 简单提一下伙伴系统的概念,后面会详细解释。
什么是page order?
page order的概念非常简单,就是page的阶,也就是1<
什么是迁移类型?
迁移类型是专门为buddy system而生的。迁移类型对buddy system的贡献我们暂时不说,我们先来解释下迁移类型的概念。
我们先来说下最简单的两种迁移类型:可移动页面和不可移动页面。
可移动页面:物理页面可以在不被用户感知的情况下,迁移到其他物理页面。比如用户空间使用的页面,可以修改虚实地址映射表,将虚拟地址偷偷映射到其他物理页面,用户感知不到物理页面的变化。
不可移动页面:物理页面不可移动。比如分配个设备的页面,由于设置直接访问物理地址,所以页面不可移动。
区分可移动页面和不可移动页面,主要是为了防止内存碎片。后面会详细解释。
什么是pageblock?
pageblock是一组连续的物理页面。pageblock中所有的pages的迁移类型是一样的,释放pages的时候,会判断该pages属于哪个pageblock,并获取其迁移类型,最终将pages加入该迁移类型对应的free_list上去。
一场简单的旅行
为了更好的理解buddy system,我在此安排了一场旅行,我们尽量把场景安排的简单,以便保证旅行的轻松愉快。
Buddy的起点
这场旅行的起点就是buddy system初始化完毕后,在首次分配页面之前的上下文。
首先我们假设最大阶是10,下图是初始阶段pages的分配图:
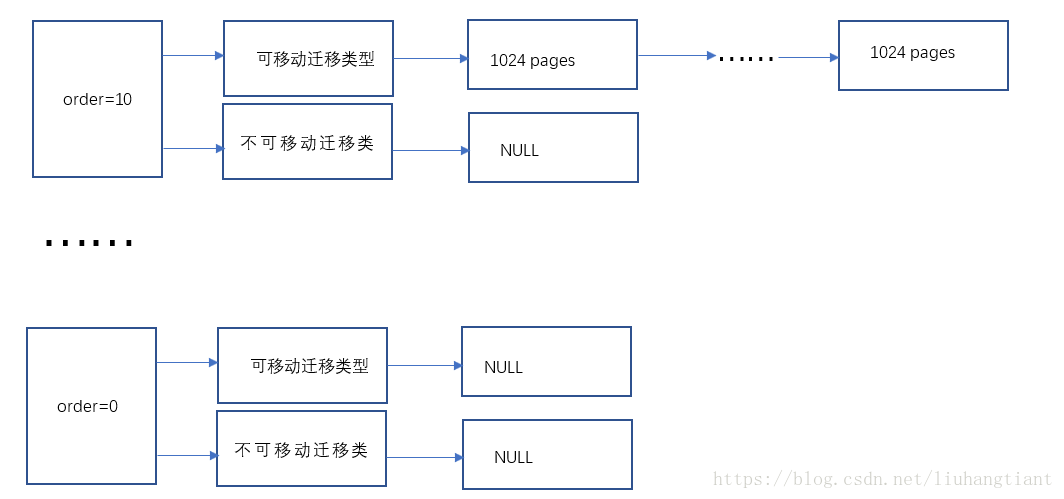
空闲pages以一定的组织形式存放在链表上。order为10的链表管理order为10的pages,也就是1024个连续的物理页块,为了尽可能避免内存碎片,每一种order对应的链表会按迁移类型分成多个,为了简单起见,这里分成两个链表,分别管理可移动物理页面和不可移动的物理页面,这样划分的好处后面会看出来。
buddy system初始化完毕后,所有的物理页都是order为10的物理页面,也就是1024个连续的物理页面被分成一组挂在order为10的可移动迁移类型链表上。其他所有的order及迁移类型对应的链表都是空的,当然这里的前提是buddy system所管理的所有连续物理内存都是1024个连续物理页面对齐的。
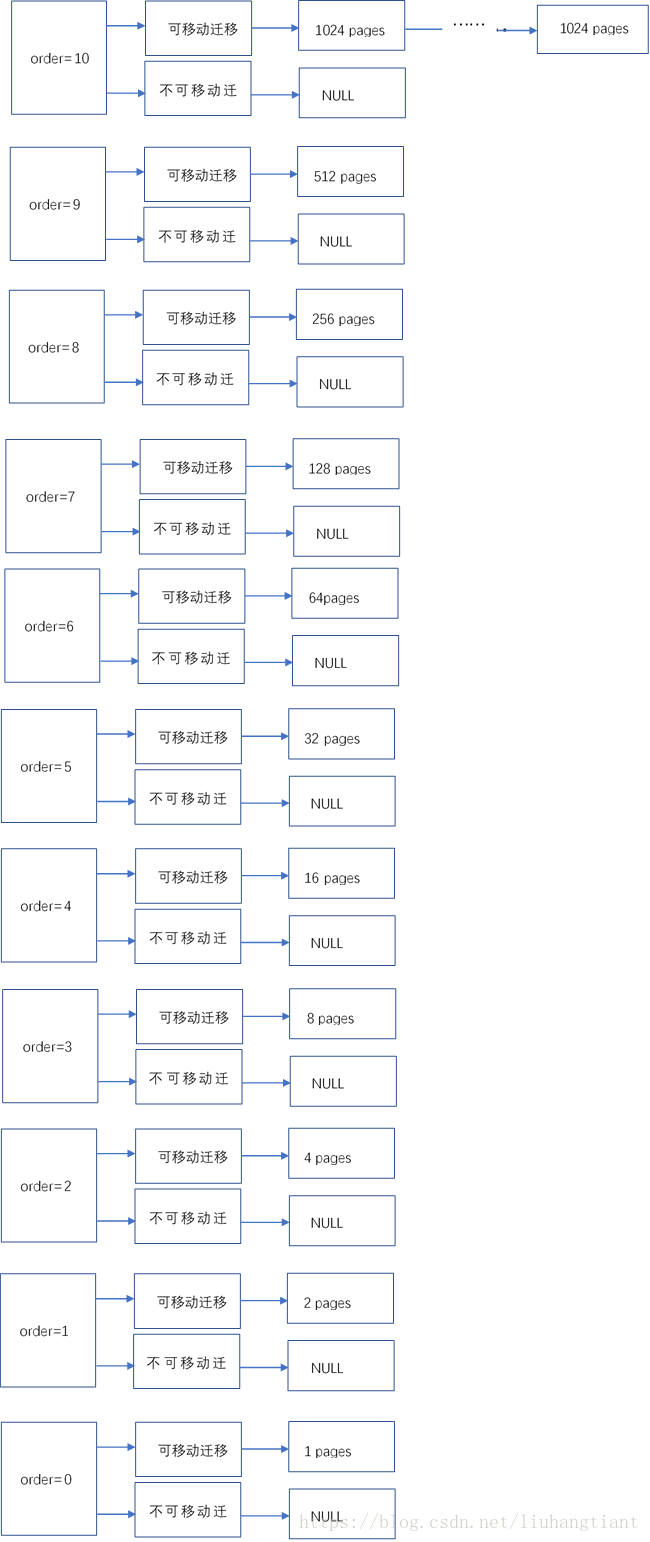
分配order为0迁移类型为可移动的page
分配页面要到最合适的链表上去分配,首选当然是从order为0的链表上分配。不巧的是,order为0的链表是空的,那么只能去order为1的链表上分配,更不巧的是order为1的链表也是空的,后面依次查询order为2-9的链表,都是空的。最终只能在order为10的链表上分配一组pages,并将这组pages从空闲链表删除,也即移除了buddy system。
然而,实际需要的是一个page,现在分配到的确是1024个pages,这要如何处理呢?其实很简单,剩余的1023个pages重新回到buddy system,重新回到buddy system遵循尽可能回到order较大的链表的原则。我们一步一步分析:
- 1023个pages回到order为10的链表是不可能的了,因为pages数量没有达到1024。
- 1024个pages的后512个pages回到order为9的可移动迁移类型链表上,还剩余511个pages。
- 511个pages的后256个pages回到order为8的可移动迁移类型链表上,还剩余255个pages。
- 255个pages的后128个pages回到order为7的可移动迁移类型链表上,还剩余127个pages。
- 最终order为9,8,7,6,5,4,3,2,1,0的可移动迁移类型链表上,都会增加一个成员。
分配完该page后,pages的分布图如下:
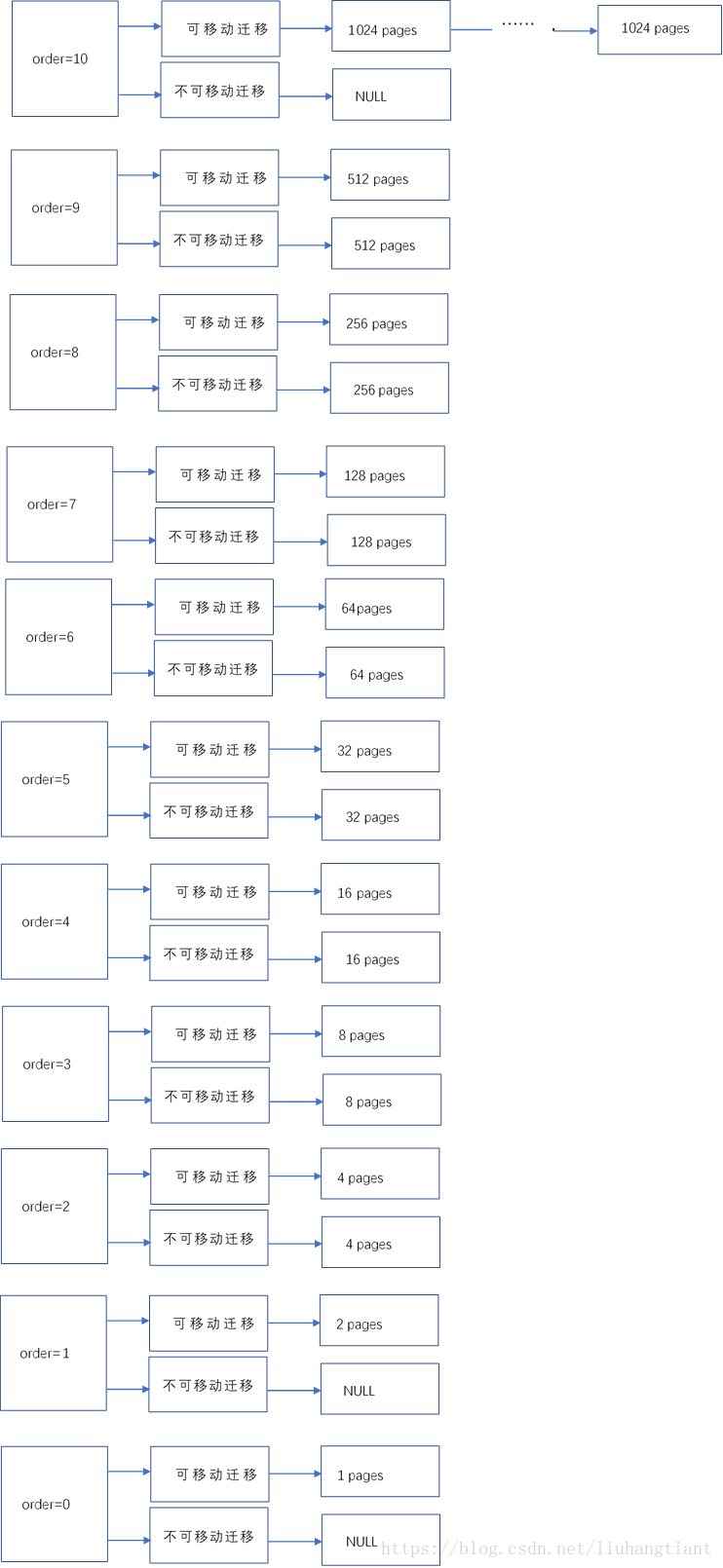
分配order为2迁移类型为不可移动的pages
order为2的可移动链表上有一个成员,而其不可移动链表上没有成员,不仅如此,所有的不可移动链表都是空的。这可怎么办?难道就分配失败了?一首凉凉就要送给给它了吗?这样也太不公平了,要知道,一开始不可移动链表上就是空的。
buddy system当然不会那么有失公允,虽然buddy system没有为不可移动链表分配pages,却提供了另外一种机制,叫做偷取机制。也就是说,当分配不到某种迁移类型的物理页面时,会尝试从其他迁移类型的链表上偷取物理页面。
比如当前场景下,由于不可移动链表全部为空,此时会偷取可移动链表上的物理页面。为了防止内存碎片,偷取机制会偷取尽可能大的空间,有以下准则需要遵循:
- 从order最大的链表尝试偷。
- 偷的时候会将整个pageblock中所有的空闲物理页面都偷过去。pageblock的order一般对应最大的order,即10。
如果一个pageblock中有超过一半的物理页面被偷了,那么就会修改整个pageblock的迁移类型,当该pageblock的页面被释放时,会被添加到新的迁移类型对应的链表上去。这样一来,实际上相当于将整个pageblock都偷过去了。
那么当前场景下,会从order为10的可移动链表上偷一个成员,即偷取1024个物理页面。由于实际需要的是4个物理页面,1024个连续物理页面的后1020个物理页面会重新回到buddy system,但是此时会回到不可移动链表上。
分配完成后,pages分配图如下:
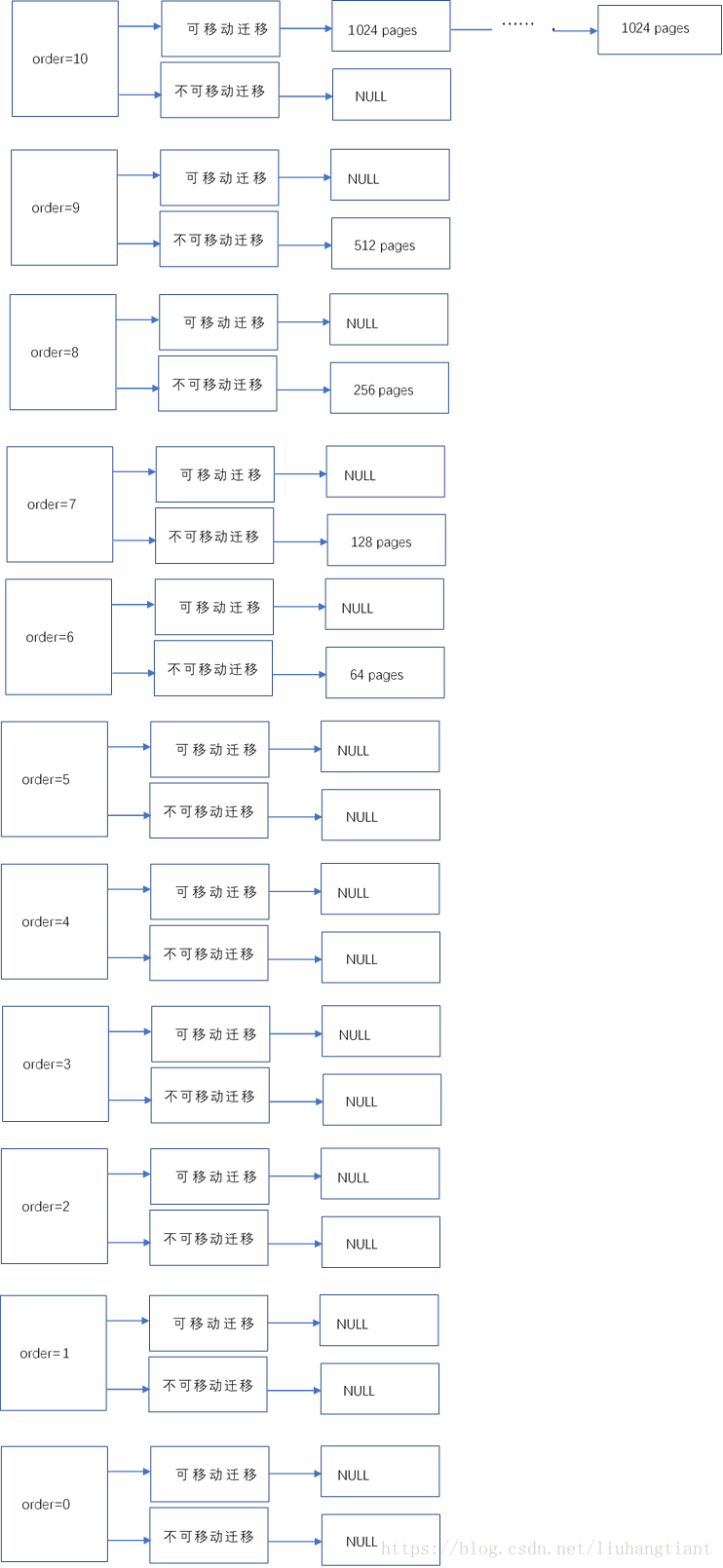
释放之前分配的order为0的page
释放的page会尝试与其伙伴(即相邻的order为0的page)合并,由于其伙伴没有被分配,依然在buddy system中,所以二者可以合并为order为1的pages;order为1的pages会继续试图与其伙伴合并,当前上下文可以合并为order为2的pages;最终合并成order为1024个pages,回到了原点。
page释放后,pages分布图如下:
迁移类型的好处
以上基本完成了这场旅行,不过我们这里要加个小插曲,解释下为何要加入迁移类型。迁移类型的目的是为了尽可能避免内存碎片。
我们已经看到,在释放pages的时候,释放的pages会尝试与其伙伴合并成更大order的pages,也就是合并成更大的内存块。如果某order的pages被永久申请,即便其伙伴是空闲的,也无法合并,这就导致内存碎片。
而迁移类型加入后,需要永久申请的pages从不可迁移链表申请,就会大大减轻内存碎片的产生。