4. Hadoop相关配置及Executor环境变量的设置
4.1 Hadoop相关配置信息
默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下:

获取的配置信息包括:
- 将Amazon S3文件系统的AccessKeyId和SecretAccessKey加载到Hadoop的Configuration;
- 将SparkConf中所有以spark.hadoop. 开头的属性都复制到Hadoop的Configuration;
- 将SparkConf的属性spark.buffer.size复制为Hadoop的Configuration的配置io.file.buffer.size;
注意:如果指定了SPARK_YARN_MODE属性,则会使用YarnSparkHadoopUtil,否则默认为SparkHadoopUtil。
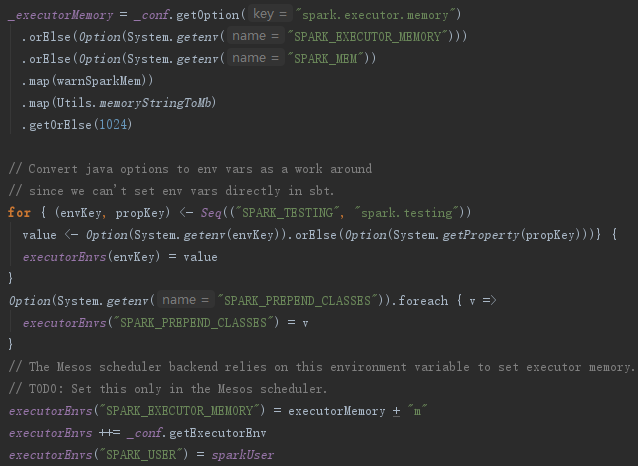
4.2 Executor环境变量
对Executor的环境变量的处理,见代码如下。executorEnvs包含的环境变量将会在注册应用的过程中发送给Master,Master给Worker发送调度后,Worker最终使用executorEnvs提供的信息启动Executor,可以通过配置spark.executor.memory指定Executor占用的内存大小,也可以配置系统变量SPARK_EXECUTOR_MEMORY或者SPARK_MEM对其大小进行设置。代码如下: