Hive 是什么?
1.Hive 是基于 Hadoop处理结构化数据的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类 SQL 查询功能。
2.Hive 利用 HDFS 存储数据,利用MapReduce 查询分析数据。本质是将 SQL 转换为 MapReduce 程序,比直接用 MapReduce 开发效率更高。 Hive通常是存储在关系数据库如 mysql/derby 中。 Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
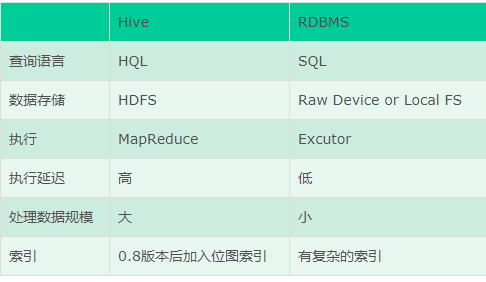
3.Hive 与传统 DB 的区别?
3.1从本质上讲hive底层是依赖于HDFS和mapreduce,而传统的数据库是依赖于本地文件系统和本设备,这就决定了hive是用mapreduce操作的HDFS数据。
3.2hive不是关系式数据库,不适合OLTP在线事务处理是延迟性很高的操作,不适合实时查询和行级更新。存储数据在关系型数据库中,使用的语言是HQL
3.3传统数据库: OLTP-->面向事务(Transaction) 操作型处理 就是关系型数据库: mysql,oracle sqlserver db2 主要是支持业务,面向业务。
Hive: OLAP-->面向分析(Analytical)分析型处理 就是数据仓库 ,面对的是历史数据(历史数据中的一部分就来自于数据库) 开展分析
4.1传统数据库表的模式是写时模式,在加载数据时强制确定的,如果数据不符合模式,数据会被拒绝加载;而hive是读时模式,对数据的验证并不在加载数据时进行,而是在查询的时候进行,但是读时模式加载数据时非常迅速的。
hive体系机构:
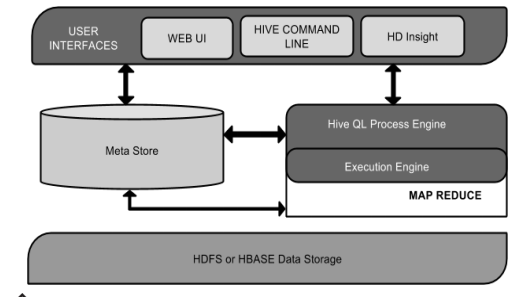
- CLI:命令行方式
- JDBC/ODBC:通过类似于MySQL接口的方式进行访问
- Web GUI:通过HTTP页面进行访问。
2.metastore是Hive元数据的集中存放地,metastore分为两个部分:服务和后台的数据存储
HIVE支持的数据类型
INT,TINYINT/SMALLINT/BIGINT,BOOLEAN,FLOAT,,DOUBLE,STRING ,BINARY,TIMESTAMP,ARRAY, MAP, STRUCT, UNION,DECIMAL
HIVE内部表和外部表
hive创建的表有两种,内部表和外部表,默认情况下是创建内部表,将表直接放入他自己的仓库目录,而这两种表的区别主要是在LOAD和DROP表的语义上面;
对于内部表的创建表并且加载数据表的操作HQL语句:
create table manage_table(id int,name string ,age int); //创建表
load data inpath '/user/centos/data.txt' into table manage_table ;//把hdfs://user/centos/data.txt 移动到hive 的 manae_tables表的仓库目录下面,即是hdfs://user/hive/warehouse/manage_table的目录下面
我们都知道,加载操作就是对文件系统中的文件进行移动或者重命名,因此速度回非常的快,即是是内部表,hive也不检查目录中的文件是否符合要加载的文件是否符合我们所声明的表的模式,如果有数据或者模式不匹配,我们只会在查询阶段进行检查。
对于内部表的删除表的操作HQL语句:
drop table manage_table,这个表包括他的元数据和数据会被一起进行删除,因此在这里要强调一点:对于内部表而言,load是移动操作,而drop是移动操作会使得数据彻底丢失。
对于外部表而言,创建表和加载数据:
create external table external_table(id int ,name string,age int); //创建外部表
load data inpath '/user/centos/data.txt' into table external table;
这个地方要强调一点:在加入了external关键字之后,hive知道数据并不是由自己来进行管理的,不会把数据移动到自己的仓库目录的下面